华为OD机试模拟题 用 C++ 实现 - 玩牌高手(2023.Q1)
news2026/2/11 10:23:26

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/375440.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

《数据库系统概论》学习笔记——第六章 关系数据理论
教材为数据库系统概论第五版(王珊) 这一章重点在于各种范式的概念和将低级范式转为高级范式。一定要看多值依赖和4NF(因为这个概念很绕又烦,但是期中期末都考了)。最后计算题就是一定要会:算闭包࿰…

少走弯路,来自HR自动化实践者5条忠告 | RPA铺第4期
安东尼与巴克利共同撰写的《“无人力”的人力资源?自动化、人工智能及机器学习时代的产业演变》一书中指出,到2030年,全球8.5%的制造业劳动力(约2000万工人)将会被自动化机器人取代。
因自动化、人工智能、机器学习带…
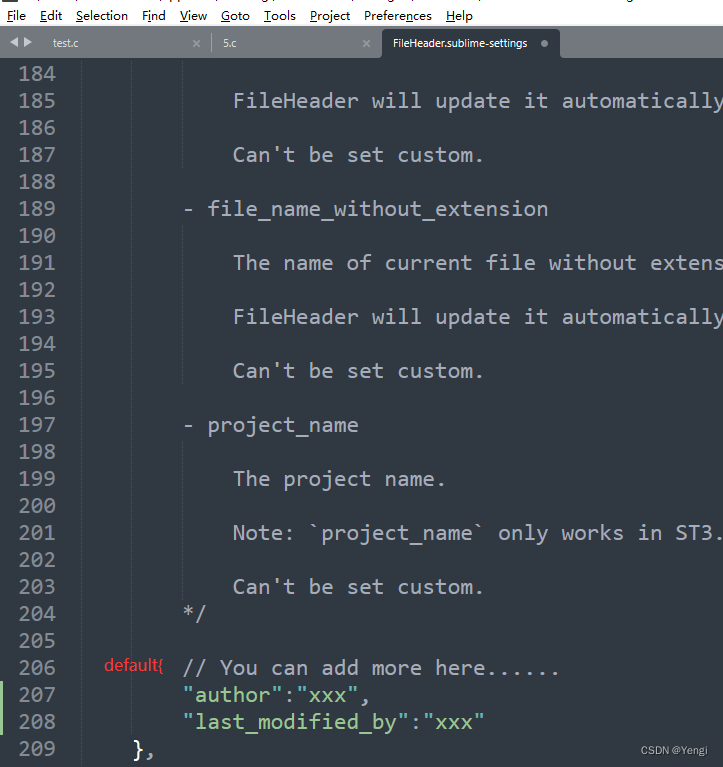
sublimeText3新建文件自动添加注释头
参考:
https://github.com/shiyanhui/FileHeader/blob/master/README.rst
https://packagecontrol.io/packages/FileHeader
https://github.com/shiyanhui/FileHeader fileheader:https://codeload.github.com/shiyanhui/FileHeader/zip/refs/heads/m…

【谷粒学院】MybatisPlus(1~17)
1.项目介绍 2.项目背景介绍 3.项目商业模式介绍
4.项目功能模块介绍 5.项目技术点介绍 6.项目技术点-MybatisPlus介绍
官网:http://mp.baomidou.com/
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做…
电子科技大学软件工程期末复习笔记(五):生产率和工作度量
目录
前言
重点一览
软件产品度量
测量软件生产率的两种方法
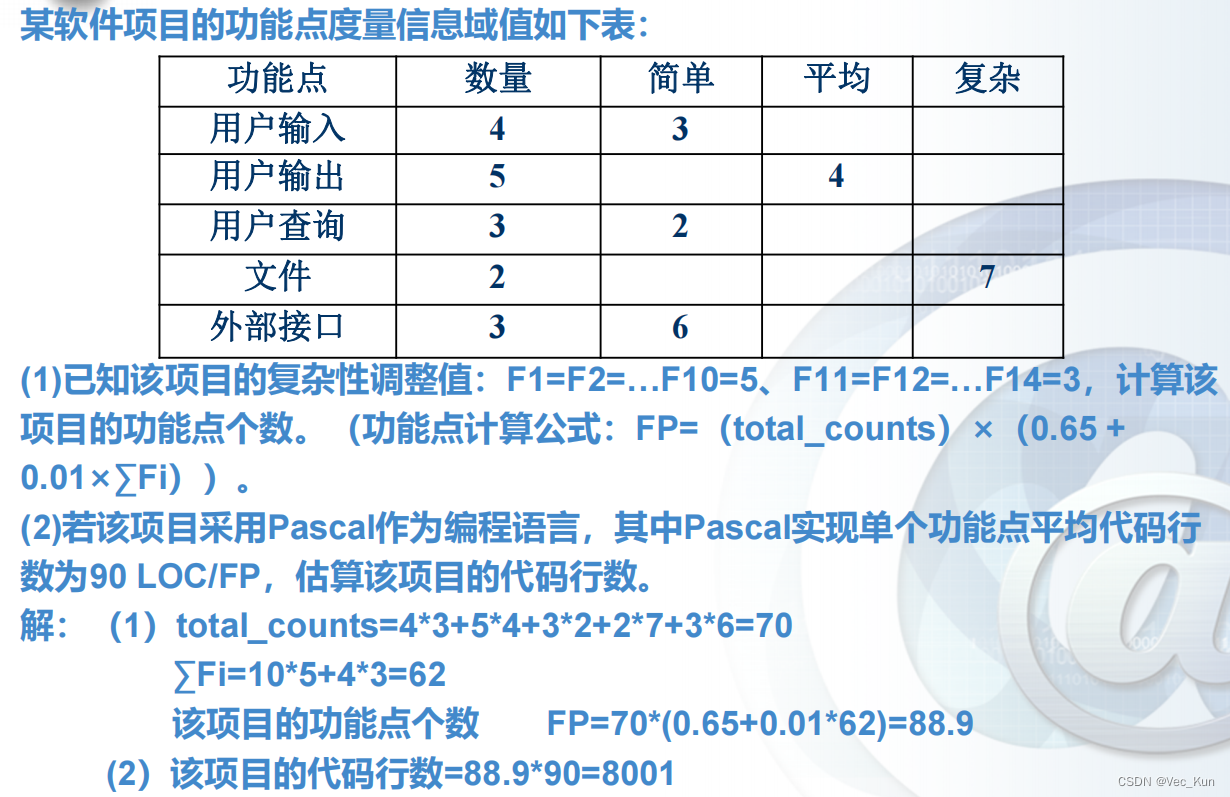
基于LOC测量 例题: 优点 缺点
基于功能点测量 例题:
本章小结 前言
本复习笔记基于王玉林老师的课堂PPT与复习大纲,供自己期末复习与学弟学妹参考用。 重点一览 这一部分内…
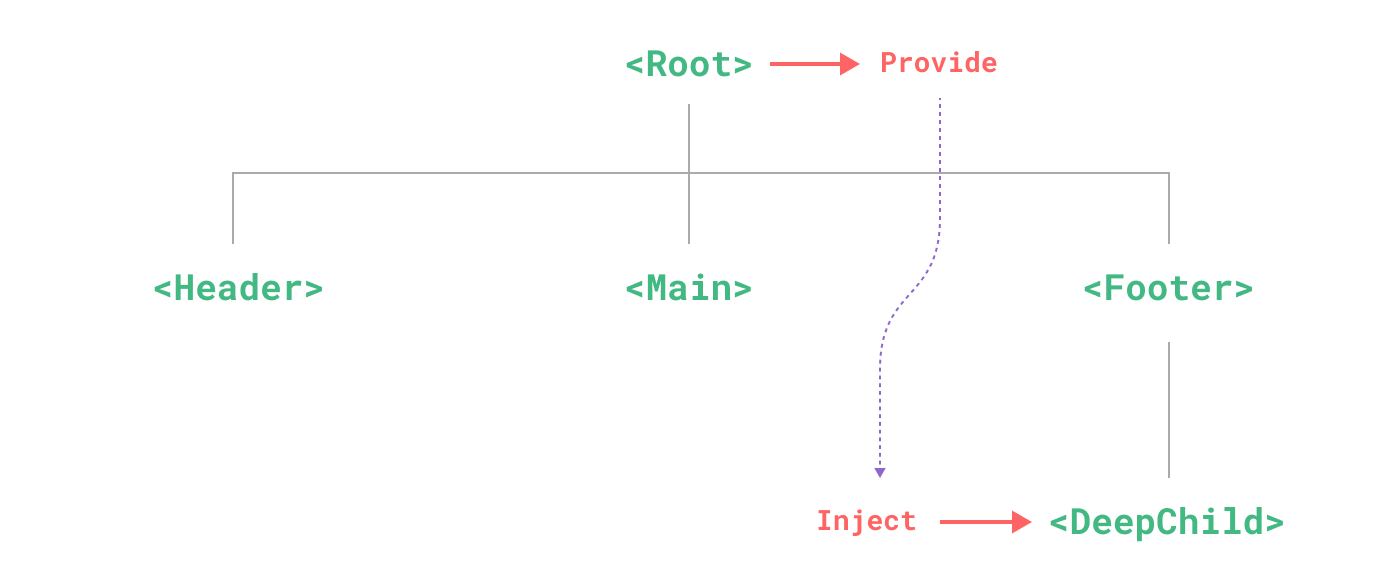
Vue3 中组件的使用(下)
目录前言:一、透传属性和事件1. 如何“透传属性和事件”2. 如何禁止“透传属性和事件”3. 多根元素的“透传属性和事件”4. 访问“透传属性和事件”二、插槽1. 什么是插槽2. 具名插槽3. 作用域插槽三、单文件组件CSS功能1. 组件作用域CSS2. 深度选择器3. CSS中的v-b…
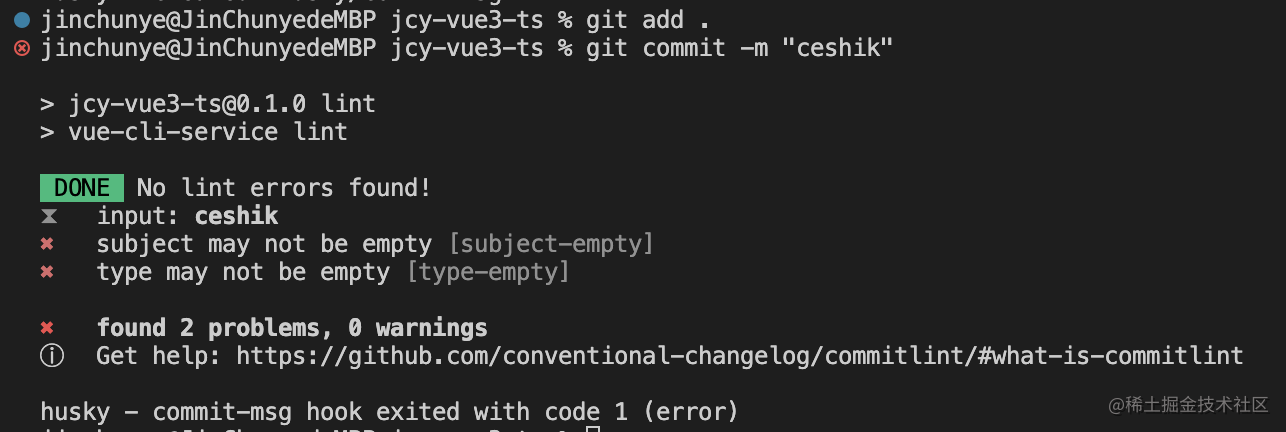
如果让我来搭建项目【规范篇】
目录前言代码规范集成editorconfig配置使用prettier工具安装prettier配置.prettierrc文件:VSCode需要安装prettier的插件测试prettier是否生效如果想一次性更改代码格式,在package.json中配置一个scripts:使用ESLint检测git Husky和eslintgit…


linux基本功系列之mount命令实战
文章目录前言一. mount命令的介绍二. 语法格式及常用选项三. 参考案例3.1 将iso镜像挂载到/mnt上3.2 把某个分区挂载到/sdb1上3.3 用只读的形式把/dev/sdb2挂载到/sdb2上3.4 设置自动挂载总结前言
大家好,又见面了,我是沐风晓月,本文是专栏【…

阶段八:服务框架高级(第二章:分布式事务)
阶段八:服务框架高级(第二章:分布式事务)Day-分布式事务0.学习目标1.分布式事务问题1.1.本地事务1.2.分布式事务1.3.演示分布式事务问题2.理论基础2.1.CAP定理2.1.1.一致性2.1.2.可用性2.1.3.分区容错2.1.4.矛盾2.2.BASE理论2.3.解…
超出认知的数据压缩 用1-bit数据来表示32-bit的梯度 语音识别分布式机器学习 梯度压缩 论文精读
说明
介绍1−bit1-bit1−bit论文内容。 原文链接:1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs | Semantic Scholar
ABS
实验证明在分布式机器学习的过程中能够通过将同步所传递的梯度进行量化…

什么是企业商机管理 管理销售商机流程方法
现代企业发展道路上,市场竞争愈演愈烈,很多企业都开始重视客户信息化管理来促成销售交易,在销售管理中的商机需按照轻重缓急进行分类、跟进、监控,才能对商机进行有效管理。
从某种程度上来说,一个订单成功与否的关键…
SpringBoot整合XxlJob
SpringBoot整合XxlJob
1.XxlJob简介
官方网址:https://www.xuxueli.com/xxl-job
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
为什么要使…

【10k~30k的区别】=== 功能测试、自动化测试、性能测试的区别
按测试执行的类型来分:功能测试、自动化测试、性能测试 1.功能测试
功能测试俗称点点点测试。初级测试人员的主要测试任务就是执行测试工程师所写的测试用 例,记录用例的执行状态及bug情况。与开发人员进行交互直到bug被修复。
功能测试理论…
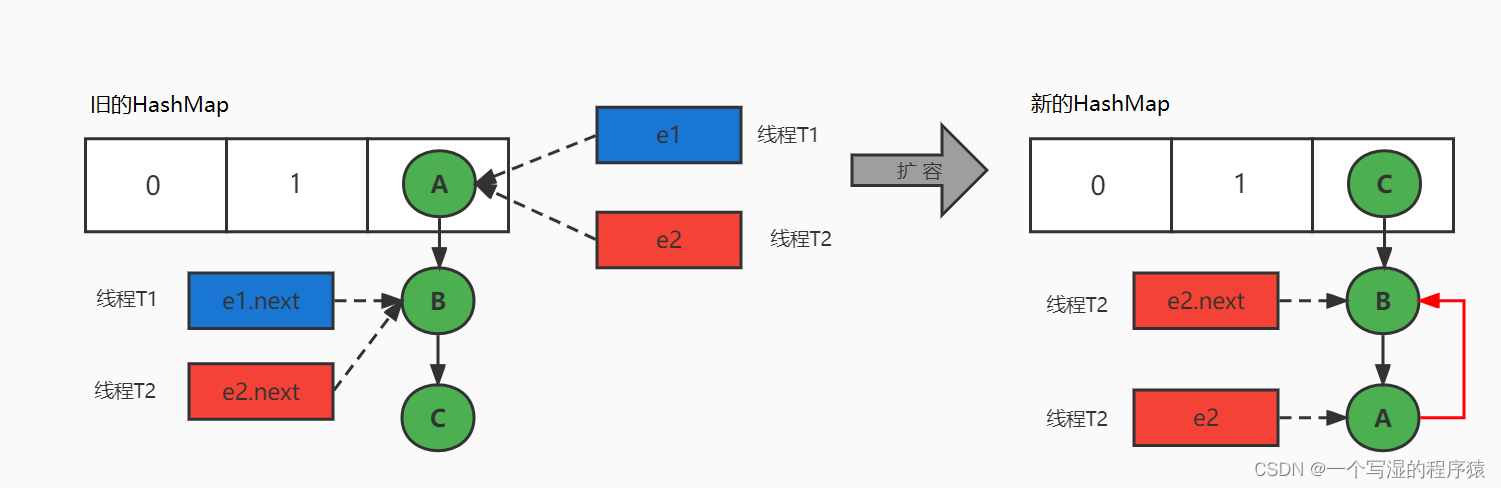
Java查漏补缺(14)数据结构剖析、一维数组、链表、栈、队列、树与二叉树、List接口分析、Map接口分析、Set接口分析、HashMap的相关问题
Java查漏补缺(14)数据结构剖析、一维数组、链表、栈、队列、树与二叉树、List接口分析、Map接口分析、Set接口分析、HashMap的相关问题本章专题与脉络1. 数据结构剖析1.1 研究对象一:数据间逻辑关系1.2 研究对象二:数据的存储结构…
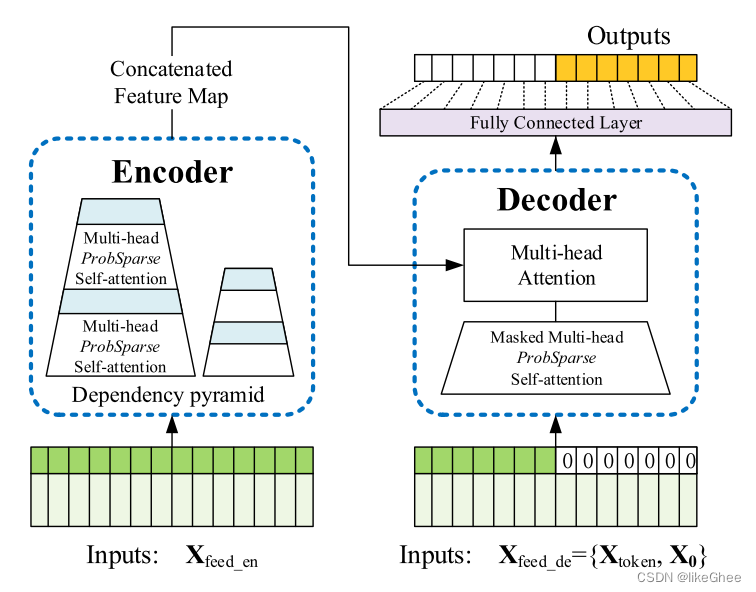
(pytorch进阶之路)Informer
论文:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI’21 Best Paper)
看了一下以前的论文学习学习,我也是重应用吧,所以代码部分会比较多,理论部分就一笔带过吧
论文作者也很良心的…

微服务的Feign到底是什么
Feign是什么
分区是一种数据库优化技术,它可以将大表按照一定的规则分成多个小表,从而提高查询和维护的效率。在分区的过程中,数据库会将数据按照分区规则分配到不同的分区中,并且可以在分区中使用索引和其他优化技术来提高查询效…

目标检测论文阅读:CBNet算法笔记
标题:CBNet: A Composite Backbone Network Architecture for Object Detection 期刊:TIP2022 论文地址:https://ieeexplore.ieee.org/document/9932281/ 官方代码:https://github.com/VDIGPKU/CBNetV2 作者单位:北京大…
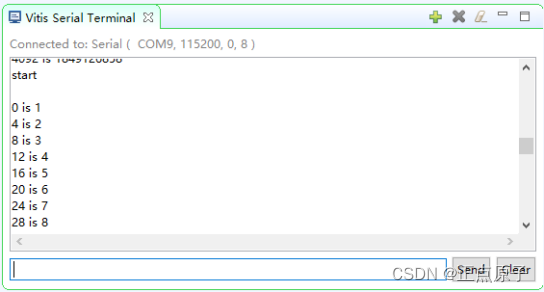
【正点原子FPGA连载】第二十章AXI4接口之DDR读写实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html
第二十章AXI4接口…
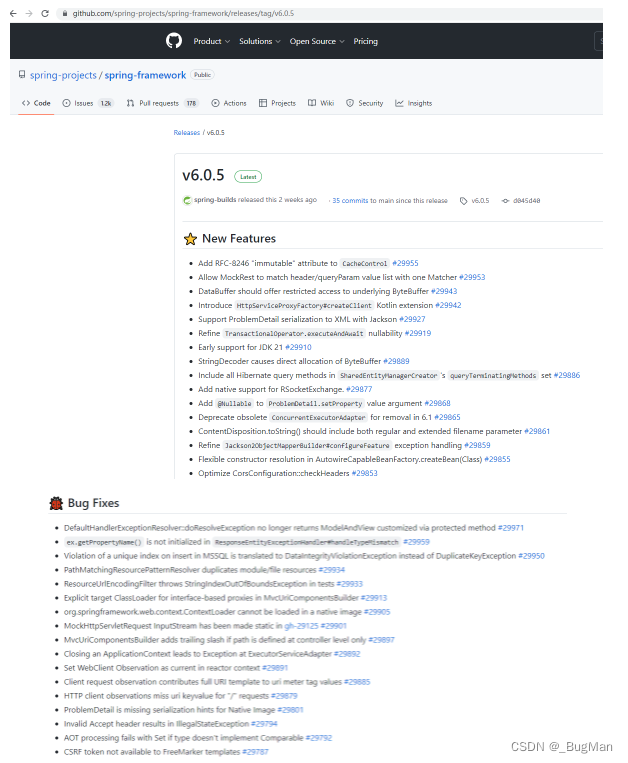
如何查看Spring Boot各版本的变化
目录
1.版本
2.基础特性和使用
3.新增特性和Bug修复 1.版本
打开Spring官网,点进Spring Boot项目我们会发现在不同版本后面会跟着不同的标签: 这些标签对应不同的版本,其意思如下:
GA正式版本,通常意味着该版本已…