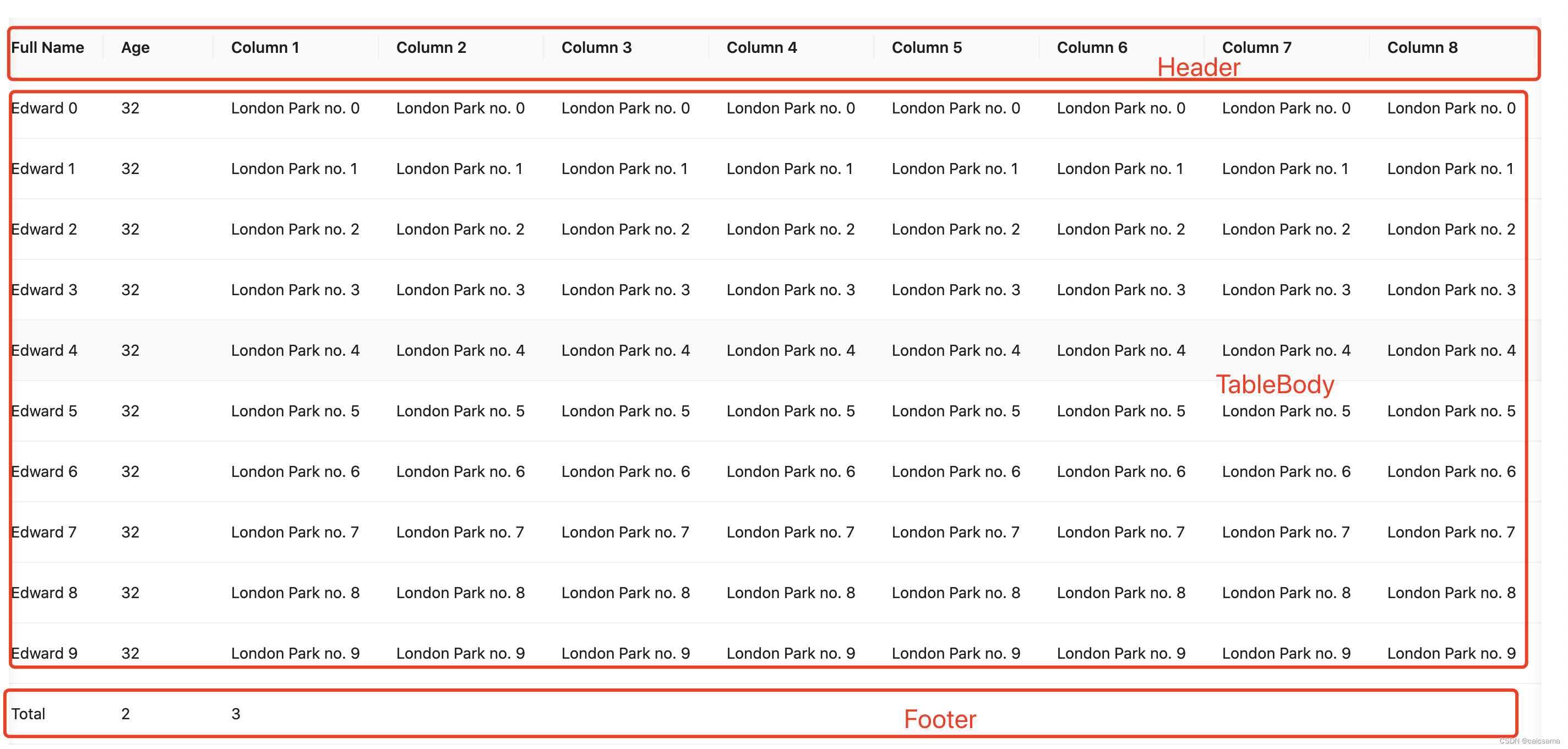
0 问题描述
参考链接
(3条消息) HiveSql面试题12--如何分析去掉最大最小值的平均薪水(字节跳动)_莫叫石榴姐的博客-CSDN博客
文中已经给出了三种解法,这里我们借助于此题,来研究如何用percent_rank()函数求解,简化解题思路。
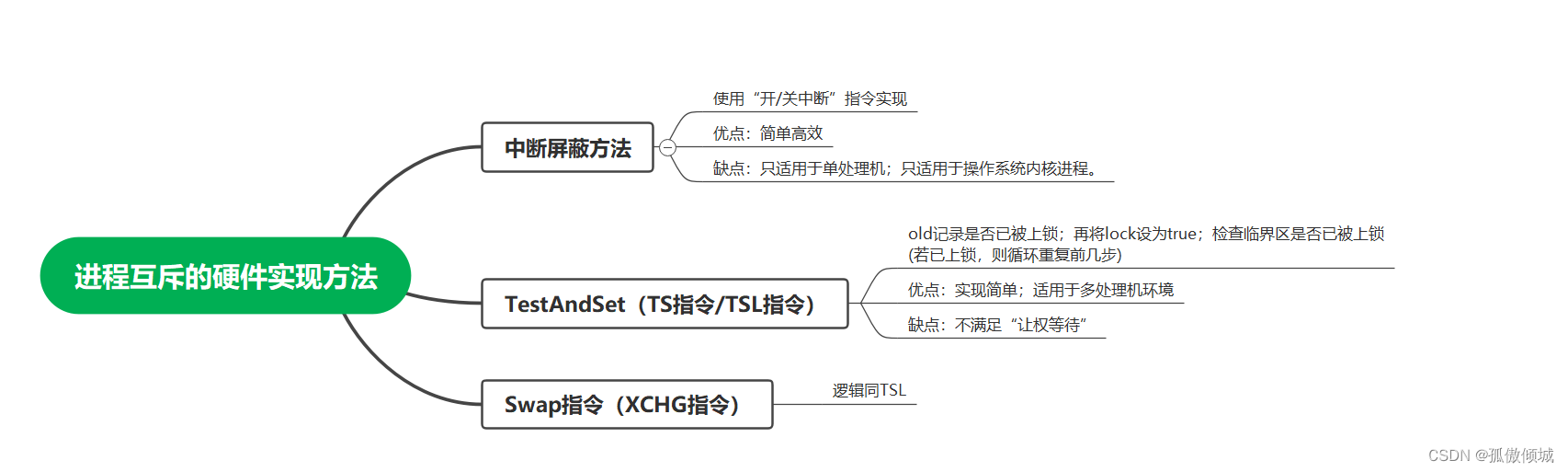
1 percent_rank()函数 使用
percent_rank() 函数为分布函数,用于返回某个排序数值在数据集中的百分比排位,其值分布在0-1之间【0,1】,此函数用于计算数值在数据集内的相对位置。
计算公式:当前行rn -1 / 组内行数 -1 其中减去1表示排位时候不包括他本身,表示他前面有多少人比他值低或高,在实际中有一定分析意义。
使用场景:用于关心排在我前面的有多少人。
如:班级成绩为例,返回的百分数60%表示某个分数排在班级总分排名前60%。
比如站队:我往往关心的是排在我前面的有多少人。如下一组数据:
如成绩为20的人,排在他前面的有5个人,除去自身,总共有6个人,那么他的相对排名百分比为 5/6
成绩为10的,排在他前面的有6个人,除去自身,那么整个群体中都比他的分数高,所以也就是100%
成绩 | 排名(rank) | 百分比排名(percent_rank) |
100 | 1 | 0% |
100 | 1 | 0% |
80 | 3 | 33% |
40 | 4 | 50% |
40 | 4 | 50% |
20 | 6 | 83% |
10 | 7 | 100% |
注意点:(1)percent_rank()对重复值的处理
(2)percent_rank()对NULL值的处理
特点:首尾一定是0 和1
cume_dist():累积百分比
和percent_rank()差不多,区别在于是否排除自身影响
含义:
升序排序:表示小于等于当前值的人数所占百分比
降序排序:大于等于当前值的人数所占百分比
2 题目分析
题目中要求是去除最大、最小值后的平均值,因此本题难点问题是如何去除,最大、最小值。我们经过上面分析,percent_rank() 函数为按照某个排序后值进行排名后当前行的占比,其值在[0,1]区间内,按照其特性,我们知道排序后,0和1 的值代表最小和最大值,因此我们根据该函数很容易获取最大最小值的标记,从而解决了row_number() 或dense_rank()函数使用一次排序不能彻底区分最大,最小值的问题,简化了问题的求解方式。具体SQL如下:
with salary as (
select
'10001' emp_num , '1' dep_num , '60117' salary
union all
select '10002' emp_num , '2' dep_num , '92102' salary
union all
select '10003' emp_num , '2' dep_num , '86074' salary
union all
select '10004' emp_num , '1' dep_num , '66596' salary
union all
select '10005' emp_num , '1' dep_num , '66961' salary
union all
select '10006' emp_num , '2' dep_num , '81046' salary
union all
select '10007' emp_num , '2' dep_num , '94333' salary
union all
select '10008' emp_num , '1' dep_num , '75286' salary
union all
select '10009' emp_num , '2' dep_num , '85994' salary
union all
select '10010' emp_num , '1' dep_num , '76884' salary
)
SELECT dep_num,cast(avg(salary) as decimal(18,0)) as avg_salary
from(
SELECT
emp_num
,dep_num
,salary
,PERCENT_RANK() over(PARTITION BY dep_num ORDER BY salary) as rate
from salary
) t
where rate != 0 and rate != 1
group by dep_num;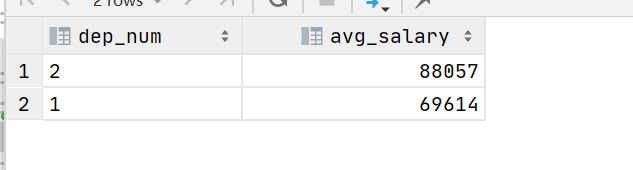
3 小结
本文给出了一种利用percent_rank()求去掉最大最小值的平均薪水的方法,该方法更简洁高效,值得借鉴。通过本文需要掌握的姿势点如下:
PERCENT_RANK函数的作用、意义及使用场景是什么?
PERCENT_RANK函数的结果是如何计算?
PERCENT_RANK与cume_disk()函数的区别?
如何利用PERCENT_RANK()函数的特性快速get最大、最小值?