文章目录
- 前言
- 什么是 Java 内存模型
- 为什么需要 Java 内存模型
- 顺序一致性内存模型
- Happens-Before 规则
- 总结
前言
在并发编程中,当多个线程同时访问同一个共享的可变变量时,会产生不确定的结果,所以要编写线程安全的代码,其本质上是对这些可变的共享变量的访问操作进行管理。导致这种不确定结果的原因就是可见性、有序性和原子性问题,Java 为解决可见性和有序性问题引入了 Java 内存模型,使用互斥方案(其核心实现技术是锁)来解决原子性问题。这篇先来看看解决可见性、有序性问题的 Java 内存模型(JMM)。
什么是 Java 内存模型
Java 内存模型在维基百科上的定义如下:
The Java memory model describes how threads in the Java programming
language interact through memory. Together with the description of
single-threaded execution of code, the memory model provides the
semantics of the Java programming language.
内存模型限制的是共享变量,也就是存储在堆内存中的变量,在 Java 语言中,所有的实例变量、静态变量和数组元素都存储在堆内存之中。而方法参数、异常处理参数这些局部变量存储在方法栈帧之中,因此不会在线程之间共享,不会受到内存模型影响,也不存在内存可见性问题。
通常,在线程之间的通讯方式有共享内存和消息传递两种,很明显,Java 采用的是第一种即共享的内存模型,在共享的内存模型里,多线程之间共享程序的公共状态,通过读-写内存的方式来进行隐式通讯。
从抽象的角度来看,JMM 其实是定义了线程和主内存之间的关系,首先,多个线程之间的共享变量存储在主内存之中,同时每个线程都有一个自己私有的本地内存,本地内存中存储着该线程读或写共享变量的副本(注意:本地内存是 JMM 定义的抽象概念,实际上并不存在)。抽象模型如下图所示:
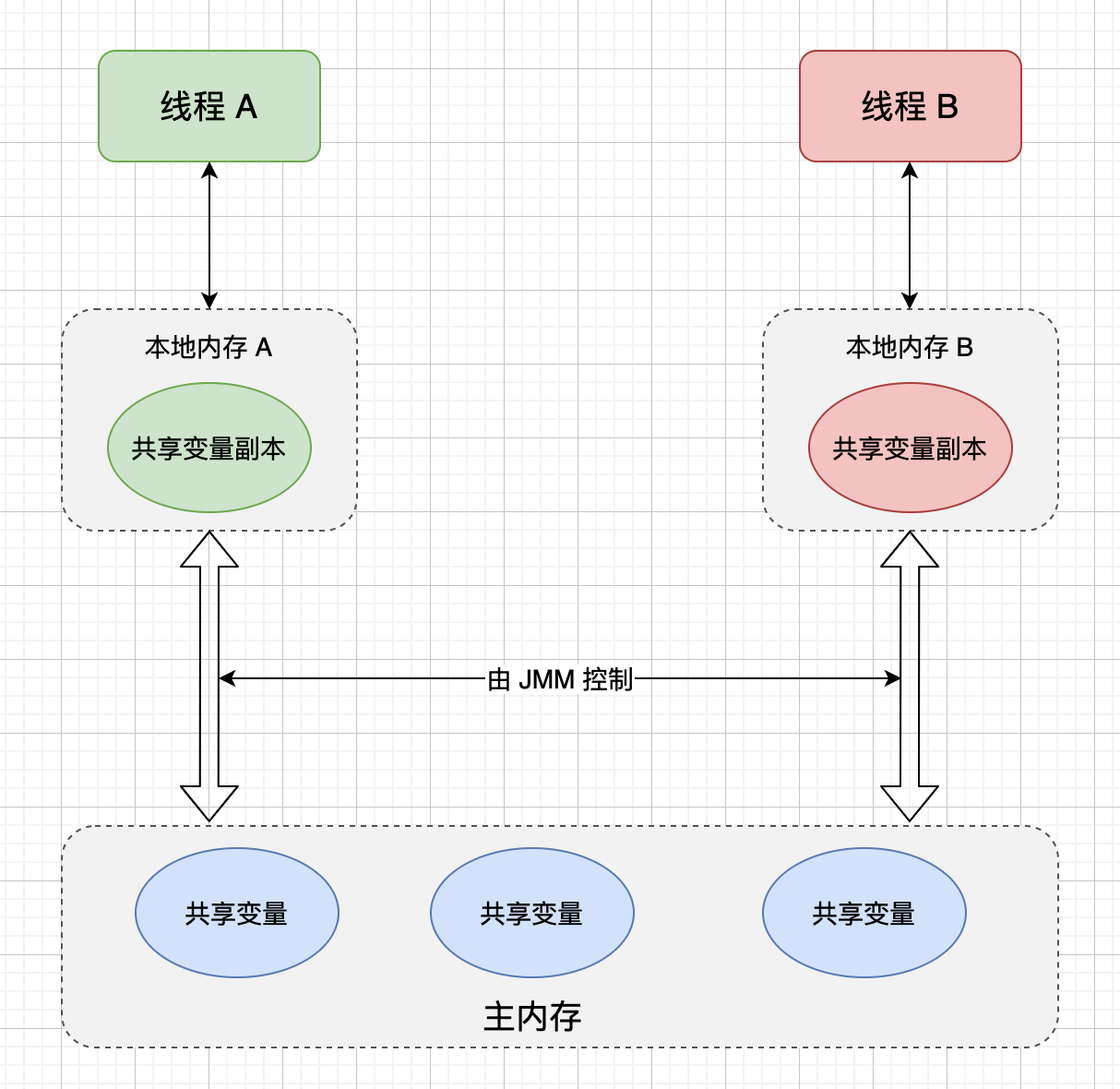
在这个抽象的内存模型中,在两个线程之间的通信(共享变量状态变更)时,会进行如下两个步骤:
线程 A 把在本地内存更新后的共享变量副本的值,刷新到主内存中。
线程 B 在使用到该共享变量时,到主内存中去读取线程 A 更新后的共享变量的值,并更新线程 B 本地内存的值。
JMM 本质上是在硬件(处理器)内存模型之上又做了一层抽象,使得应用开发人员只需要了解 JMM 就可以编写出正确的并发代码,而无需过多了解硬件层面的内存模型。
为什么需要 Java 内存模型
在日常的程序开发中,为一些共享变量赋值的场景会经常碰到,假设一个线程为整型共享变量 count 做赋值操作(count = 9527;),此时就会有一个问题,其它读取该共享变量的线程在什么情况下获取到的变量值为 9527 呢?如果缺少同步的话,会有很多因素导致其它读取该变量的线程无法立即甚至是永远都无法看到该变量的最新值。
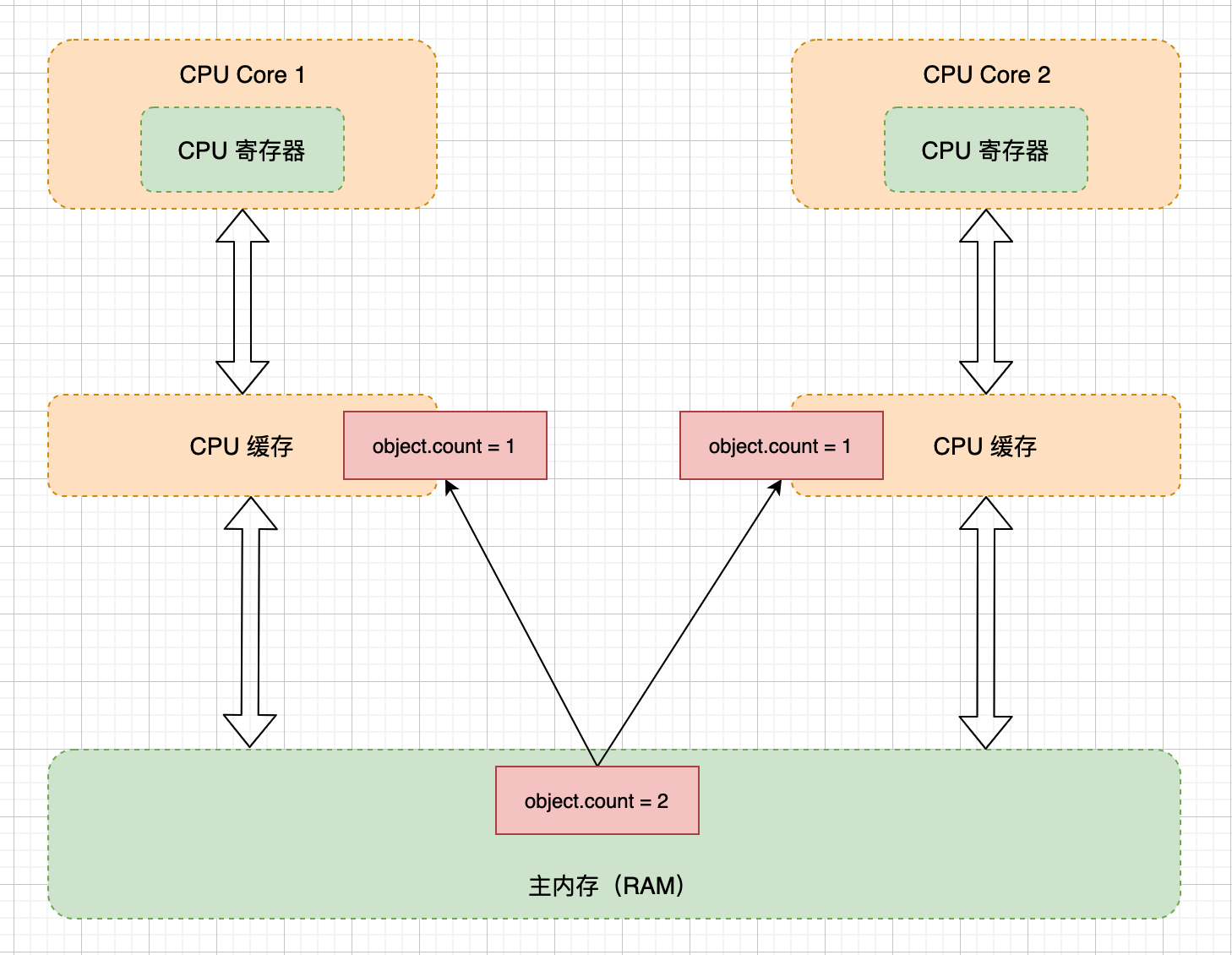
比如缓存就可能会改变写入共享变量副本提交到主内存的次序,保存在本地缓存的值,对于其它线程是不可见的;编译器为了优化性能,有时候会改变程序中语句执行的先后顺序,这些因素都有可能会导致其它线程无法看到共享变量的最新值。
在文章开头,提到了 JMM 主要是为了解决可见性和有序性问题,那么首先就要先搞清楚,导致可见性和有序性问题发生的本质原因是什么?现在的服务绝大部分都是运行在多核 CPU 的服务器上,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据就会有一致性问题了,当一个线程对共享变量的修改,另外一个线程无法立刻看到。导致可见性问题的本质原因是缓存。
有序性是指代码实际的执行顺序和代码定义的顺序一致,编译器为了优化性能,虽然会遵守 as-if-serial 语义(不管怎么重排序,在单线程下的执行结果不能改变),不过有时候编译器及解释器的优化也可能引发一些问题。比如:双重检查来创建单实例对象。下面是使用双重检查来实现延迟创建单例对象的代码:
/**
* @author mghio
* @since 2021-08-22
*/
public class DoubleCheckedInstance {
private static DoubleCheckedInstance instance;
public static DoubleCheckedInstance getInstance() {
if (instance == null) {
synchronized (DoubleCheckedInstance.class) {
if (instance == null) {
instance = new DoubleCheckedInstance();
}
}
}
return instance;
}
}
这里的 instance = new DoubleCheckedInstance();,看起来 Java 代码只有一行,应该是无法就行重排序的,实际上其编译后的实际指令是如下三步:
- 分配对象的内存空间
- 初始化对象
- 设置 instance 指向刚刚已经分配的内存地址
上面的第 2 步和第 3 步如果改变执行顺序也不会改变单线程的执行结果,也就是说可能会发生重排序,下图是一种多线程并发执行的场景:
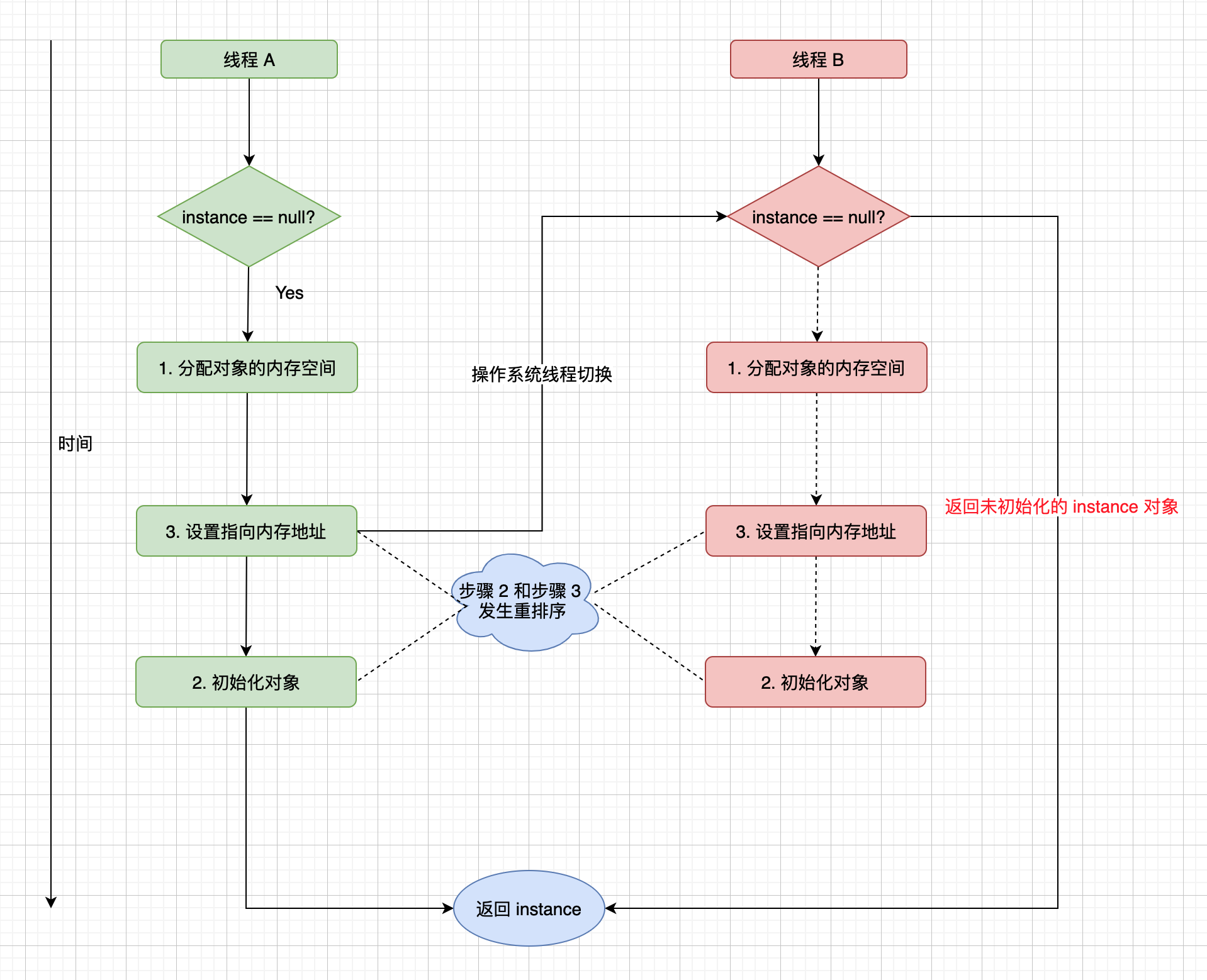
此时线程 B 获取到的 instance 是没有初始化过的,如果此来访问 instance 的成员变量就可能触发空指针异常。导致有序性问题的本质原因是编译器优化。那你可能会想既然缓存和编译器优化是导致可见性问题和有序性问题的原因,那直接禁用掉不就可以彻底解决这些问题了吗,但是如果这么做了的话,程序的性能可能就会受到比较大的影响了。
其实可以换一种思路,能不能把这些禁用缓存和编译器优化的权利交给编码的工程师来处理,他们肯定最清楚什么时候需要禁用,这样就只需要提供按需禁用缓存和编译优化的方法即可,使用比较灵活。因此Java 内存模型就诞生了,它规范了 JVM 如何提供按需禁用缓存和编译优化的方法,规定了 JVM 必须遵守一组最小的保证,这个最小保证规定了线程对共享变量的写入操作何时对其它线程可见。
顺序一致性内存模型
顺序一致性模型是一个理想化后的理论参考模型,处理器和编程语言的内存模型的设计都是参考的顺序一致性模型理论。其有如下两大特性:
一个线程中的所有操作必须按照程序的顺序来执行
所有的线程都只能看到一个单一的执行操作顺序,不管程序是否同步
在工程师视角下的顺序一致性模型如下:
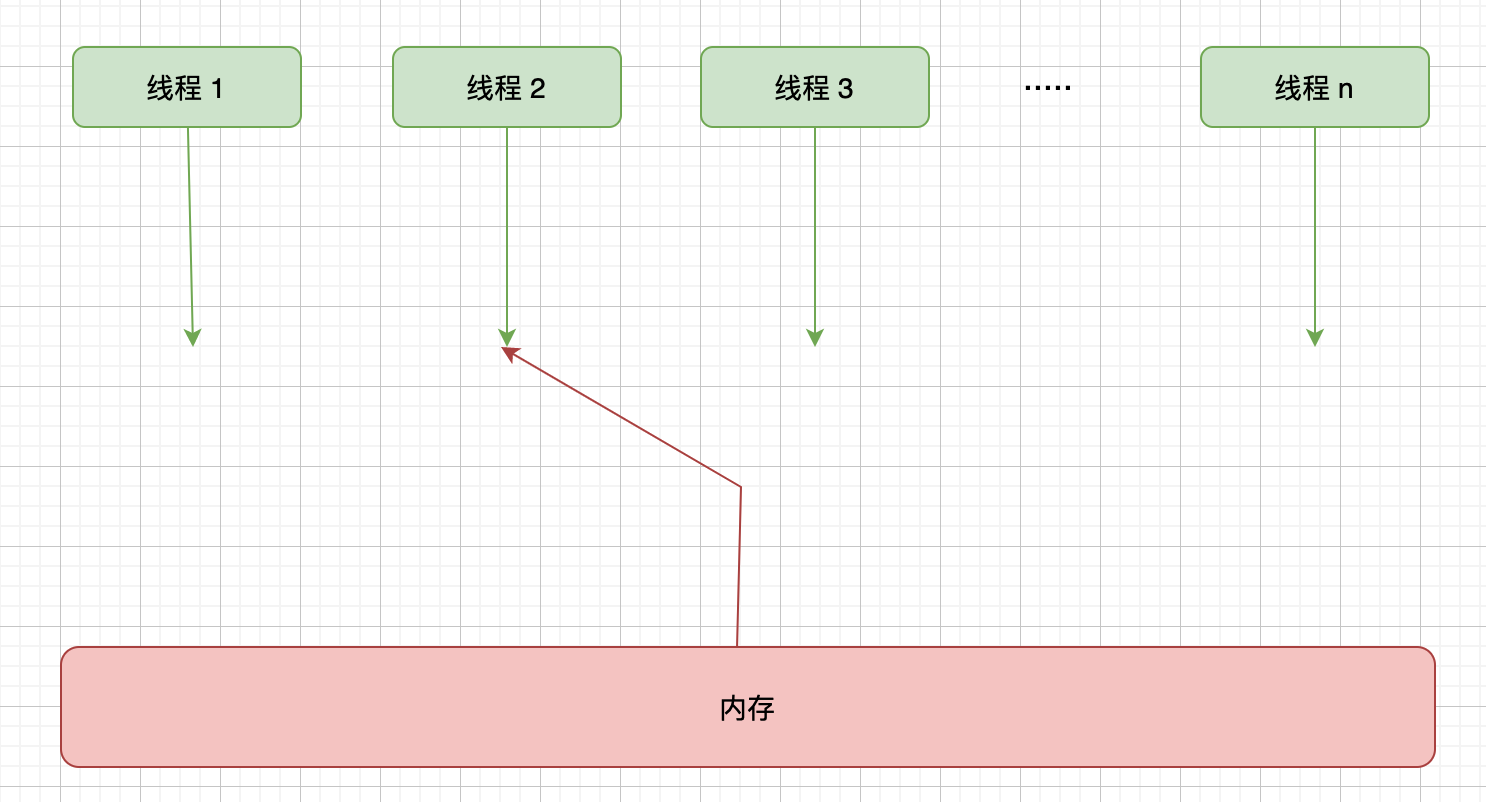
顺序一致性模型有一个单一的全局内存,这个全局内存可以通过左右摇摆的开关可以连接到任意一个线程,每个线程都必须按照程序的顺序来执行内存的读和写操作。该理想模型下,任务时刻都只能有一个线程可以连接到内存,当多个线程并发执行时,就可以通过开关就可以把多个线程的读和写操作串行化。
顺序一致性模型中,所有操操作完全按照顺序串行执行,但是在 JMM 中就没有这个保证了,未同步的程序在 JMM 中不仅程序的执行顺序是无序的,而且由于本地内存的存在,所有线程看到的操作顺序也可能会不一致,比如一个线程把写共享变量保存在本地内存中,在还没有刷新到主内存前,其它线程是不可见的,只有更新到主内存后,其它线程才有可能看到。
JMM 对在正确同步的程序做了顺序一致性的保证,也就是程序的执行结果和该程序在顺序一致性内存模型中的执行结果相同。
Happens-Before 规则
Happens-Before 规则是 JMM 中的核心概念,Happens-Before 概念最开始在 这篇论文 提出,其在论文中使用 Happens-Before 来定义分布式系统之间的偏序关系。在 JSR-133 中使用 Happens-Before 来指定两个操作之间的执行顺序。
JMM 正是通过这个规则来保证跨线程的内存可见性,Happens-Before 的含义是前面一个对共享变量的操作结果对该变量的后续操作是可见的,约束了编译器的优化行为,虽然允许编译器优化,但是优化后的代码必须要满足 Happens-Before 规则,这个规则给工程师做了这个保证:同步的多线程程序是按照 Happens-Before 指定的顺序来执行的。目的就是为了在不改变程序(单线程或者正确同步的多线程程序)执行结果的前提下,尽最大可能的提高程序执行的效率。
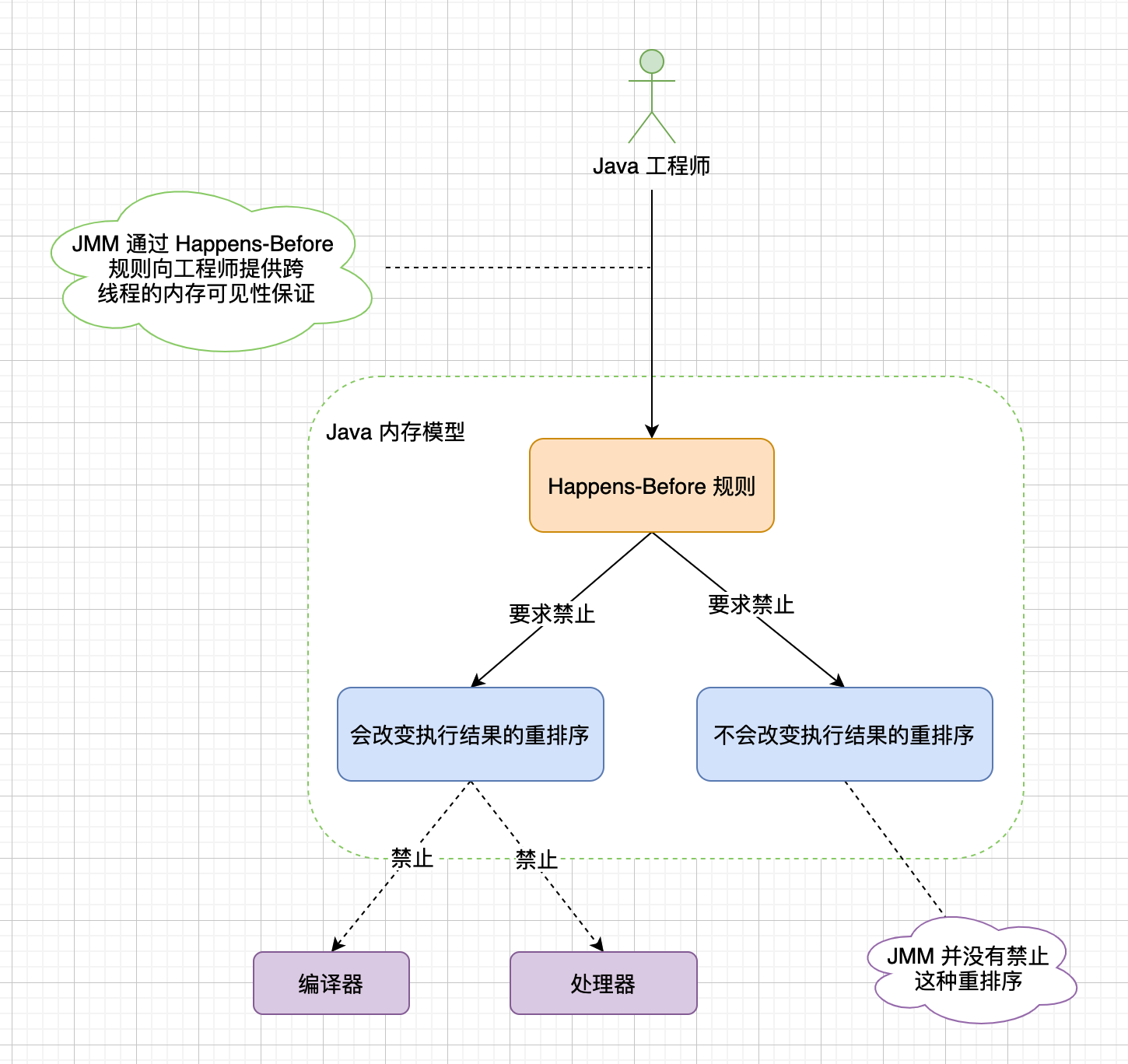
JSR-133 规范中定了如下 6 项 Happens-Before 规则:
程序顺序规则:一个线程中的每个操作,Happens-Before 该线程中的任意后续操作
监视器锁规则:对一个锁的解锁操作,Happens-Before 于后面对这个锁的加锁操作
volatile 规则对一个 volatile 类型的变量的写操作,Happens-Before 与任意后面对这个 volatile 变量的读操作
传递性规则:如果操作 A Happens-Before 于操作 B,并且操作 B Happens-Before 于操作 C,则操作 A Happens-Before 于操作 C
start() 规则:如果一个线程 A 执行操作 threadB.start() 启动线程 B,那么线程 A 的 start() 操作 Happens-Before 于线程 B 的任意操作
join() 规则:如果线程 A 执行操作 threadB.join() 并成功返回,那么线程 B 中的任意操作 Happens-Before 于线程 A 从 threadB.join() 操作成功返回
JMM 的一个基本原则是:只要不改变单线程和正确同步的多线程的执行结果,编译器和处理器随便怎么优化都可以,实际上对于应用开发人员对于两个操作是否真的被重排序并不关心,真正关心的是执行结果不能被修改。因此 Happens-Before 本质上和 sa-if-serial 的语义是一致的,只是 sa-if-serial 只是保证在单线程下的执行结果不被改变。
总结
本文主要介绍了内存模型的相关基础知识和相关概念,JMM 屏蔽了不同处理器内存模型之间的差异,在不同的处理器平台上给应用开发人员抽象出了统一的 Java 内存模型(JMM)。常见的处理器内存模型比 JMM 的要弱,因此 JVM 会在生成字节码指令时在适当的位置插入内存屏障(内存屏障的类型会因处理器平台而有所不同)来限制部分重排序。