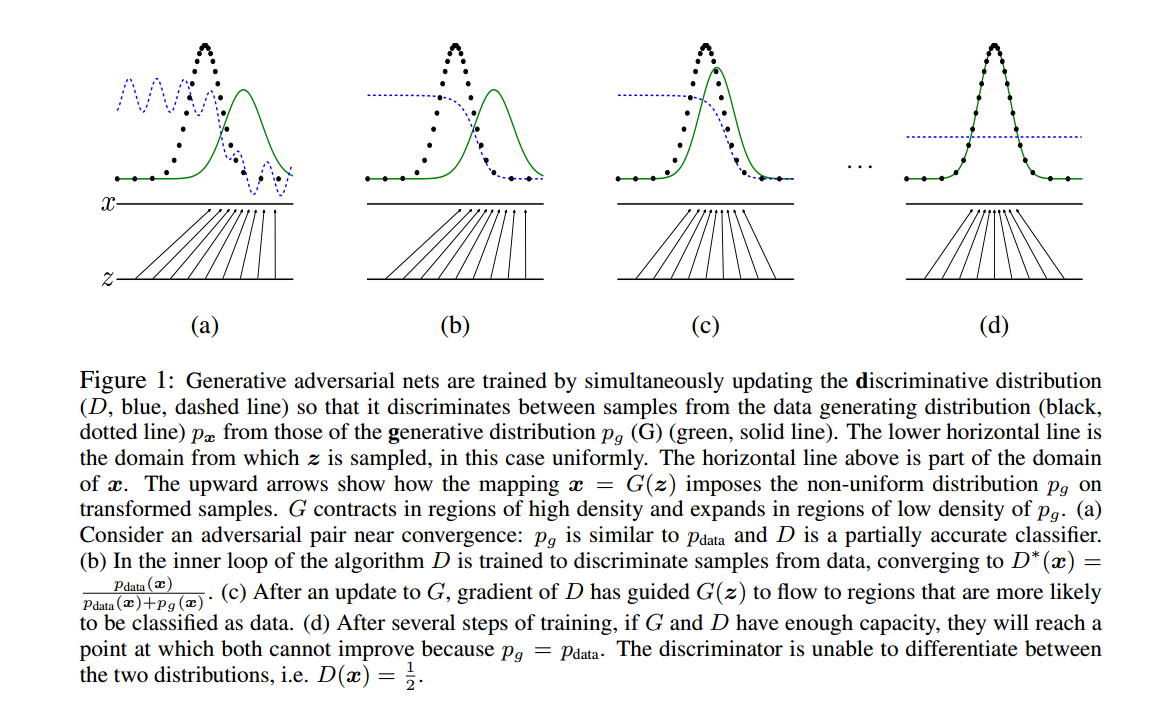
1. 前言
深度学习虽然发展迅速,但是由于其线性的特性,受到了对抗样本的影响,很容易造成系统功能的失效。
以图像分类为例子,对抗样本很容易使得在测试集上精度很高的模型在对抗样本上的识别精度很低。
对抗样本指的是在合法数据上添加了特定的小的扰动,人眼不能明显分辨但是会影响深度学习模型的输出的样本。

常见的防御方法有对抗训练Adversarial Training。最近我在尝试复现对抗训练,找了一下发现有一些基于tensorflow的对抗训练的代码,但是没怎么看见pytorch的代码,所以我在这里做一个记录。
2. 参考文献:
1书籍《AI安全之对抗样本入门》
2 论文 Explaining and Harnessing Adversarial Examples 论文链接
3. 以FGSM算法为例的对抗训练的实现(基于Pytorch)
3.1 FGSM算法概述
FGSM算法由上面参考文献中的论文首次提出。
全名叫Fast Gradient Sign Method
前言介绍中说了,对抗样本是在合法数据上添加一个特定的扰动,FGSM算法就是用来计算这个扰动的,称其为
η
\eta
η。
FGSM算法属于一个白盒攻击算法,即知道被攻击模型的结构,模型参数并且可以控制输入输出。
数学式子如下:
η
=
ϵ
s
i
g
n
(
∇
x
J
(
θ
,
x
,
y
)
)
(1)
\eta =\epsilon sign(\nabla_xJ(\theta,x,y)) \tag{1}
η=ϵsign(∇xJ(θ,x,y))(1)
ϵ \epsilon ϵ是攻击强度; θ \theta θ是模型的参数;x是输入模型的样本;y是x对应的标签;sign是符号函数,大于0取1,小于0取-1,等于0时就是0。
公式(1)表示,输入x后得到pred,然后pred与y计算loss,最后loss反向传播一次,获取x的梯度并且取符号,然后乘以扰动强度
ϵ
\epsilon
ϵ就得到了我们需要的特定的扰动。
这么做的原因是因为在把这个扰动
η
\eta
η加到原合法数据x上时,相当于使得x朝着loss增大的方向去变化了,loss增大的方向就是预测结果与标签不同的方向。
一般梯度下降优化模型参数时,都是减去梯度方向的某一步长的值。
代码实现:cleverhans攻防库
3.2 对抗训练的思想
论文 Explaining and Harnessing Adversarial Examples采用在训练过程中加入对抗样本的方法。这使得模型或多或少都会学习到一些对抗样本的知识,可以在一定程度上帮助模型抵御对抗样本的攻击。
但是对抗训练的缺点是针对特定攻击算法进行对抗训练的模型只对该攻击算法有防御效果,不同的攻击算法或者相同算法的不同扰动强度都会使得对抗训练的防御效果大打折扣。
对抗训练的训练过程中的目标函数:
J
~
(
θ
,
x
,
y
)
=
α
J
(
θ
,
x
,
y
)
+
(
1
−
α
)
J
(
θ
,
x
~
,
y
)
(2)
\widetilde J(\theta,x,y) = \alpha J(\theta,x,y)+(1-\alpha)J(\theta,\widetilde x,y) \tag{2}
J
(θ,x,y)=αJ(θ,x,y)+(1−α)J(θ,x
,y)(2)
x
~
\widetilde x
x
是对抗样本,x是合法样本。
α
\alpha
α在论文中取0.5
3.3 tensorflow实现的对抗训练的代码
tensorflow的对抗训练的实现
3.4 我用pytorch实现的对抗训练代码
3.4.1 总的运行流程
if __name__ == "__main__":
# 使用哪个设备训练---
device = "cuda"
# device = "cpu"
# 攻击算法的相关参数---
eps = 0.01 # FGSM的攻击强度
attack_type = "FGSM"
# 输出日志
print("attack_type = {}".format(attack_type))
print("eps = {}".format(eps))
# 加载模型---
model_name = "Resnet18"
cls = loadModel()
# 对抗训练用的参数
batchsize = 16
lr = 1e-4
total_epochs = 500
# 开始对抗训练
clsWithAdv = ClsWithAdvData(cls, attack_type)
# 对抗训练过程
clsWithAdv.mainProcess()
# 在测试集对应的对抗样本测试集上测试精度
clsWithAdv.test_model()
3.4.2 加载模型的函数
def loadModel():
"""
加载模型, 对其训练并测试精度
:return: 返回的是已经加载好了的模型
"""
if model_name == "Resnet18":
# 这里可以把模型的初始化自定义
# FineTuneClassifier是我自己写的初始化resnet18的类
classifier = FineTuneClassifier(model_name="Resnet18")
else:
# 模型名字不正确则抛出运行时异常
raise RuntimeError("The model_name:{} is invalid!".format(model_name))
# 返回初始化完毕的模型
return classifier
3.4.3 主要的训练流程
from cleverhans.torch.attacks.projected_gradient_descent import projected_gradient_descent
from torch.utils.data import DataLoader
from tqdm import tqdm
import torch
from torch import optim
import time
import torch.nn as nn
from cleverhans.torch.attacks.fast_gradient_method import fast_gradient_method
from cleverhans.torch.attacks.carlini_wagner_l2 import carlini_wagner_l2
import numpy as np
import os
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from torch.utils.data import Dataset
# 下面这两个是我自己写的
# mypath用于获取工程文件夹的目录,方便保存和加载文件时使用绝对路径
import mypath
# accuracy是计算预测结果和标签的相同个数的函数
from myutils.classifier_accuracy import accuracy
class ClsWithAdvData:
def __init__(self, model, attack_type):
super(ClsWithAdvData, self).__init__()
# 输出日志
print("trainClsByAdvData...")
print("batchsize = {}, lr = {}, total_epochs = {}".format(batchsize, lr, total_epochs))
# 获取数据集
self.train_loader = DataLoader(MyOwnDataset(type="Train"), batch_size=batchsize, shuffle=True)
self.val_loader = DataLoader(MyOwnDataset(type="Val"), batch_size=batchsize, shuffle=True)
self.test_loader = DataLoader(MyOwnDataset(type="Test"), batch_size=batchsize, shuffle=True)
# 训练开始的时间,用于保存模型
self.train_begin_time = time.strftime("%Y-%m-%d_%H-%M", time.localtime())
# 模型保存的路径
self.ckp_path = os.path.join(mypath.root_path, "AdvTrain", "ckp", model_name + "_" + self.train_begin_time)
# 损失函数
self.loss_fun = nn.CrossEntropyLoss()
# 模型送入设备
self.classifier = model
self.classifier.to(device)
# 优化器
self.optimer = optim.AdamW(self.classifier.parameters(), lr=lr, weight_decay=0.05)
# 学习率衰减
self.scheduler = optim.lr_scheduler.StepLR(self.optimer, step_size=10, gamma=0.99)
# 攻击方法
self.attack_type = attack_type
# 训练过程中的日志数据
self.train_loss_list = []
self.train_acc_list = []
self.val_acc_list = []
def mainProcess(self):
"""
对抗训练的训练流程
"""
# ------开始训练------
best_val_acc = 0 # 最高的验证准确率
for e in range(total_epochs):
# 定期清空模型,减少不必要的显存消耗
torch.cuda.empty_cache()
# 训练一次模型
# 返回的是本次训练的累计loss和精度信息
currentEpoch_train_loss, currentEpoch_train_acc = self.train(self.train_loader)
# 计算验证集上的精度
val_acc = self.eval_data(self.val_loader)
# 打印一次日志
print("[Epoch %d/%d] [Train_loss: %f]\n [Train_acc: %f] [Val_acc: %f]\n" % (
e, total_epochs,
currentEpoch_train_loss,
currentEpoch_train_acc,
val_acc))
# 将loss,acc保存到列表list中方便绘图可视化
self.train_loss_list.append(currentEpoch_train_loss)
self.train_acc_list.append(currentEpoch_train_acc)
self.val_acc_list.append(val_acc)
self.saveLossData() # 保存loss数据
# 本次epoch的验证精度最高则保存模型
if val_acc > best_val_acc:
torch.save(self.classifier.state_dict(), self.ckp_path)
print("当前模型已经保存")
# 更新最好验证集的记录
best_val_acc = val_acc
# for total_epochs end
def train(self, train_loader):
"""
一个epoch的训练过程
:param train_loader: 训练数据集
:return:
float(epoch_loss)是本次epoch训练过程中的累计loss.
float(train_acc) 是本次epoch训练过程中的预测准确率.
"""
correct_num = 0 # 某次epoch分类正确的图片个数
epoch_num = 0 # 某次epoch已经参与训练的图片个数
epoch_loss = 0 # 某次epoch所有batch的loss的和
# 模型置训练模式
self.classifier.train()
# 进度条
bar = tqdm(train_loader, ncols=100)
# 开始训练一个epoch
for index, (img, label) in enumerate(bar):
# 数据送入设备
img, label = img.to(device), label.to(device)
# 使用攻击算法获取对抗样本
adv_img = self.attack(img)
# 分类器给出预测
pred = self.classifier(img) # legitimate样本的预测结果
adv_pred = self.classifier(adv_img) # 对抗样本的预测结果
# 计算loss
legitimate_loss = self.loss_fun(pred, label.long())
adv_loss = self.loss_fun(adv_pred, label.long())
cls_loss = 0.5*legitimate_loss + 0.5*adv_loss
# 记录本次epoch的累计loss
epoch_loss += cls_loss
# 更新网络
self.optimer.zero_grad()
cls_loss.backward()
self.optimer.step()
# 累计分类正确的个数
correct_num += accuracy(pred, label)
# 累计已经预测过的总数
epoch_num += label.size(0)
# epoch end
# 计算本次epoch训练的精度
train_acc = np.true_divide(correct_num, epoch_num)
# 衰减学习率
if self.optimer.state_dict()['param_groups'][0]['lr'] > lr / 1e2:
self.scheduler.step()
# 删除一些变量,尽可能降低内存/显存使用量
del correct_num, epoch_num
del img, label, pred, cls_loss
return float(epoch_loss), float(train_acc)
def eval_data(self, data_loader, adv=False, preparedAdvData=False):
"""
在验证集或者测试集上评估精度
:param data_loader: 使用的数据集
:param adv: 是否需要将样本转换为对应的对抗样本
:param preparedAdvData:
是否提前准备好了对抗样本数据。
提前准备好的advTest数据集的是一个list:
"normal":normal_data, "adv":adv_data, "label":label_data
:return: 评估的精度
"""
correct_num = 0 # 本次测试中分类正确的图片个数
epoch_num = 0 # 本次测试中已经参与的图片个数
# 模型置训练模式
self.classifier.eval()
# 进度条
bar = tqdm(data_loader, ncols=100)
for index, data in enumerate(bar):
# 提前准备好了对抗样本数据的话,img使用data的第二个
if preparedAdvData:
img = data[1].to(device)
else:
img = data[0].to(device)
# 是否需要将当前样本转换为对应的对抗样本
if adv:
img = self.attack(img)
label = data[-1].to(device)
# 分类器给出预测
pred = self.classifier(img)
# 累计分类正确的个数
correct_num += accuracy(pred, label)
# 累计已经预测过的总数
epoch_num += label.size(0)
# for end
# 计算本次测试中的精度
train_acc = np.true_divide(correct_num, epoch_num)
# 删除变量,减少一个指向。某一块内存只有没有被任何变量指向才会被释放。
del img, label, pred, correct_num, epoch_num
return float(train_acc)
def test_model(self):
# self.loadPreTrainedModel()
# 训练完成所有epoch, 计算测试集上的精度
test_acc = self.eval_data(self.test_loader)
print("在攻击前的测试数据集上测试精度...")
print("[Test_acc: %f]\n" % test_acc)
# 在攻击后的测试数据集上测试精度
# 加载攻击后的数据集
adv_test_loader = DataLoader(MyOwnDataset(model_name,attack_type,eps), batch_size=batchsize, shuffle=True)
test_acc = self.eval_data(adv_test_loader, adv=True)
print("在攻击后的测试数据集上测试精度...")
print("[Test_acc: %f]\n" % test_acc)
def loadPreTrainedModel(self):
self.classifier.load_state_dict(torch.load(os.path.join(mypath.root_path, "AdvTrain", "ckp",
"my_own_ckp_name")))
# 保存训练过程中的loss数据
def saveLossData(self):
# 将日志列表保存为文件
np.save(os.path.join(mypath.root_path, "AdvTrain", "loss", model_name + "_train_loss_list.npy"),
torch.tensor(self.train_loss_list, device="cpu").numpy())
np.save(os.path.join(mypath.root_path, "AdvTrain", "loss", model_name + "_train_acc_list.npy"),
torch.tensor(self.train_acc_list, device="cpu").numpy())
np.save(os.path.join(mypath.root_path, "AdvTrain", "loss", model_name + "_val_acc_list.npy"),
torch.tensor(self.val_acc_list, device="cpu").numpy())
# 绘制loss变化的可视化图像
plt.figure()
x = np.linspace(start=0, stop=len(self.train_loss_list), num=len(self.train_loss_list), dtype=np.uint32)
plt.plot(x, torch.tensor(self.train_loss_list, device="cpu").numpy(), "red", label="train_loss_list")
# plt.plot(x, torch.tensor(self.val_loss_list, device="cpu").numpy(), "blue", label="val_loss_list")
plt.legend(loc='best')
plt.savefig(os.path.join(mypath.root_path, "AdvTrain", "loss", model_name + "_loss.png"))
plt.close()
# 绘制acc变化的可视化图像
plt.figure()
x = np.linspace(start=0, stop=len(self.train_loss_list), num=len(self.train_loss_list), dtype=np.uint32)
plt.plot(x, torch.tensor(self.train_acc_list, device="cpu").numpy(), "yellow", label="train_acc_list")
plt.plot(x, torch.tensor(self.val_acc_list, device="cpu").numpy(), "green", label="val_acc_list")
plt.legend(loc='best')
plt.savefig(os.path.join(mypath.root_path, "AdvTrain", "loss", model_name + "_acc.png"))
plt.close()
def attack(self, img):
"""
使用攻击算法得到对抗样本
:param img: 输入的合法legitimate数据
:return: 输入数据对应的对抗样本
"""
if attack_type == "FGSM":
img = fast_gradient_method(self.classifier, img, eps, np.inf)
elif attack_type == "PGD":
img = projected_gradient_descent(self.classifier, img,
eps=eps, eps_iter=1 / 255,
nb_iter=min(255 * eps + 4, 1.25 * (eps * 255)), norm=np.inf)
elif attack_type == "CW":
img = carlini_wagner_l2(self.classifier, img, n_classes=500,
lr=lr,
initial_const=initial_const,
binary_search_steps=binary_search_steps,
max_iterations=max_iterations)
else:
raise RuntimeError("Attack type is invalid!")
return img