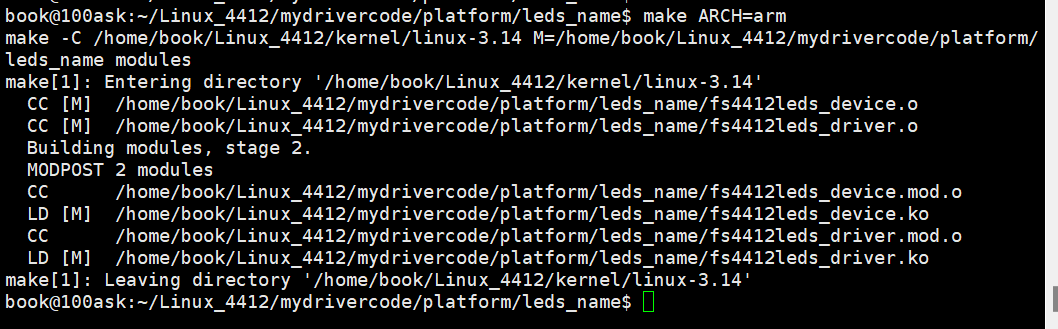
文章目录
- 1.基础介绍
- 2.CRNN模型结构
- 2.1 特征提取
- 2.2 双向循环神经网络层
- 2.3 转录层(Transcription Layers)
- 参考资料
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
title: 2.OCR文本识别Convolution Recurrent Neural Network
toc: true
category: OCR
date: 2023-02-20 12:39:20
tags:
- OCR
categories: - OCR
1.基础介绍
论文:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
Code: https://github.com/bgshih/crnn
这篇论文是2015年07月份华中科技大学的Baoguang Shi/Xiang Bai等提交的。
文本识别是OCR任务中关键的一步,经过文本检测后可以获取文本区域的图像,文本识别可以将文本的图像patch转成字符序列。
这篇文章中提出的模型架构,将图像的特征提取/序列学习模型/文本转录做了整和,实现了模型的端到端训练。通过模型的整和,模型能够处理任意长度的序列,且对于有字典和无字典(lexicon)的任务都取得了比较好的效果。
论文中提出的四种方法的优势:
- 可端到端训练
- 可处理任意长度的文本序列
- 不需要限定字典
- 生成的模型更小
提出模型的组成主要包括:
2.CRNN模型结构

从上图中可以看到模型主要包括三部分,卷积层提取特征,双向循环神经网络学习标签序列中的上下文信息,转录层将输出的冗余字符串通过 B \mathcal{B} B。
2.1 特征提取
特征提取使用的是标准的卷积层+最大值池化的方法。图像在输入到CNN之前需要先将其高度resize到一个固定的数值,然后CNN的输出是高度为1的不定长特征序列向量,从左到右是相同维度的序列,作为BiLSTM的输入。特征序列向量的每一列对应原图像中的一个矩形区域:

例如输入为(32,100,3)的图像,经过CNN特征提取后输出的序列特征的shape为
(
1
,
25
,
512
)
(1,25,512)
(1,25,512)
2.2 双向循环神经网络层

循环神经网络(Recurrent Neural Network,RNN)从其定义,中间使用了隐含层的信息传递,使得其具有了序列预测的能力。

但是当序列的长度比较长的时候,一个位置的预测依赖更远的先前语义信息时,RNN的表现就有些弱了,例如,使用RNN的语言模型在处理I grew up in France… I speak fluent French.,从French比较近的上下文可以知道speak fluent后面应该时语言,但借助更久远的信息in France能进一步推断应该是French。

长短期记忆网络(Long Short Term Memory,LSTM)的提出正是
对RNN的改进,为了解决RNN不能处理的长期依赖问题,LSTM中上部的C_t那条线使得信息能够从较远的过去传递到当前的位置,
σ
\sigma
σ函数的使用又让
L
S
T
M
LSTM
LSTM能够选择性的记忆或遗忘传递过来的信息,因此LSTM能更好的处理远期依赖的问题。
从前面图中可以看到LSTM和传统的RNN模型只能从左侧向右侧传递依赖信息,但实际上在处理序列数据时可以同时利用序列当前位置左侧和右侧的信息来共同处理,Bilateral Direction LSTM使用两条路径,实现了利用左右侧上下文信息来做推理。

Pytorch.nn模块中实现的LSTM层,通过参数可以直接控制LSTM的层数和是否是双向LSTM。
class RNNBase(torch.nn.Module)
def __init__(self, mode: str, input_size: int, hidden_size: int,
num_layers: int = 1, bias: bool = True, batch_first: bool = False,
dropout: float = 0., bidirectional: bool)
...
class LSTM(RNNBase):
...
2.3 转录层(Transcription Layers)
BiLSTM的输出Shape为(N,T,C),N是Batch Size,T是序列长度,C是序列每个位置可能的取值类别数(字典中字符的个数),对输出在维度2上做softmax得到的就是序列每个位置字符取值的概率。

在模型训练时,因为CNN提取的特征长度是不固定的,和图像对应的字符串之间也没有对应关系,因此直接从这种未切分的数据中直接学习字符串序列需要使用特殊的方法,文章作者使用的是2006年一篇文章中提出的Connectionist Temporal Classification(CTC)算法,这一部分是CRNN模型能之间从字符串图像中直接学习的关键,具体可以参考另一篇文章的详细介绍
参考资料
- 1.https://zhuanlan.zhihu.com/p/43534801




![[优化]上下游交互策略](https://img-blog.csdnimg.cn/39f905196a9b433587b6a26a97e64703.png)