🐱 个人主页: 莎萌玩家
🙋♂️ 作者简介:全栈领域新星创作者、专注于全栈各领域技术,共同学习共同进步,一起加油呀!
💫系列专栏:网络爬虫、WEB全栈开发
📢 资料领取:python,java,c++等进阶资料以及文中源码可以找我免费领取
🔥 全栈学习交流:可以关注我们新课的微信公众号,汇集了各路大神,一起交流学习,期待你的加入!
一转眼,我在新课的学习时间也已经过半,回顾来到这的5个月时间,一点一滴,一分一秒都不是那么轻松容易,但是我相信我的选择是正确的,有人说:“选择大于努力”,一往无前,在IT的道路上越走越远和,今天我也想分享一下我在这儿的一些学习感受:
首先,老师们都是非常和蔼可亲的,平时问的问题都会积极给予回应,每个学生都有一个专门课后解答的群聊,里面全是老师:
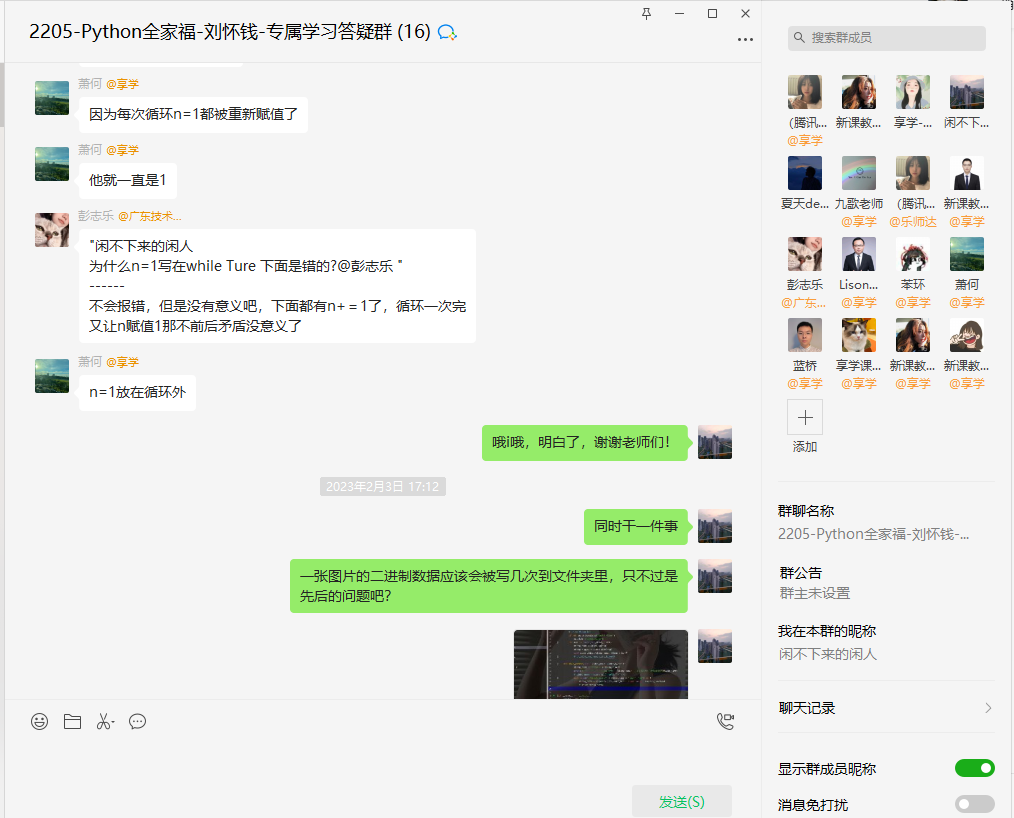
课后服务效果由此可见。
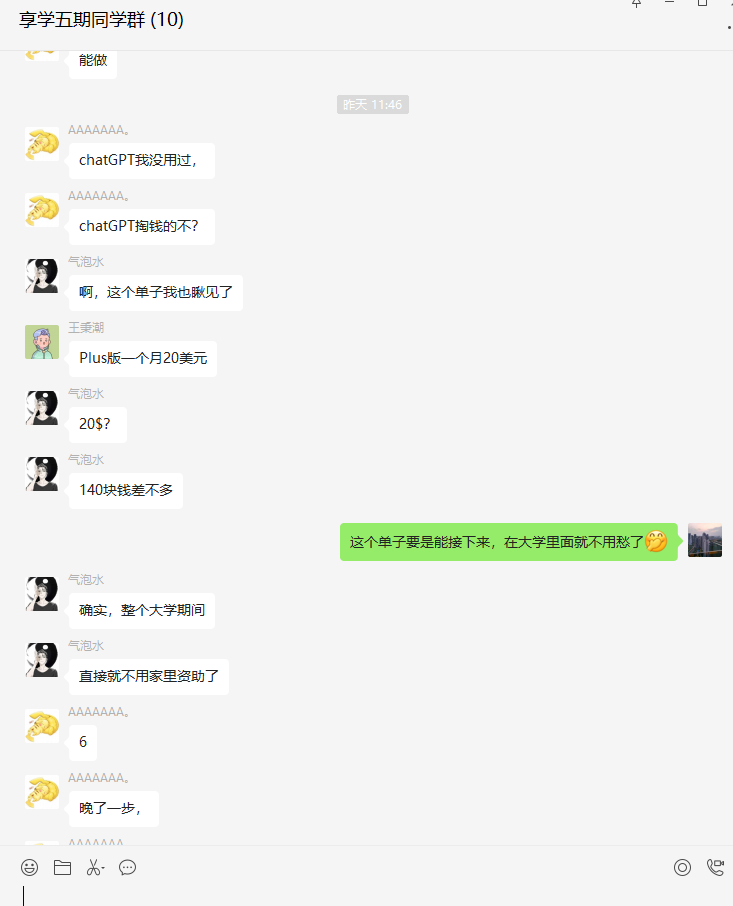
其次,学生们的学习态度也是非常积极,活跃,课上课下都非常积极的讨论平时课堂上,或者是作业中遇到的各种问题,时不时还会聊聊生活:
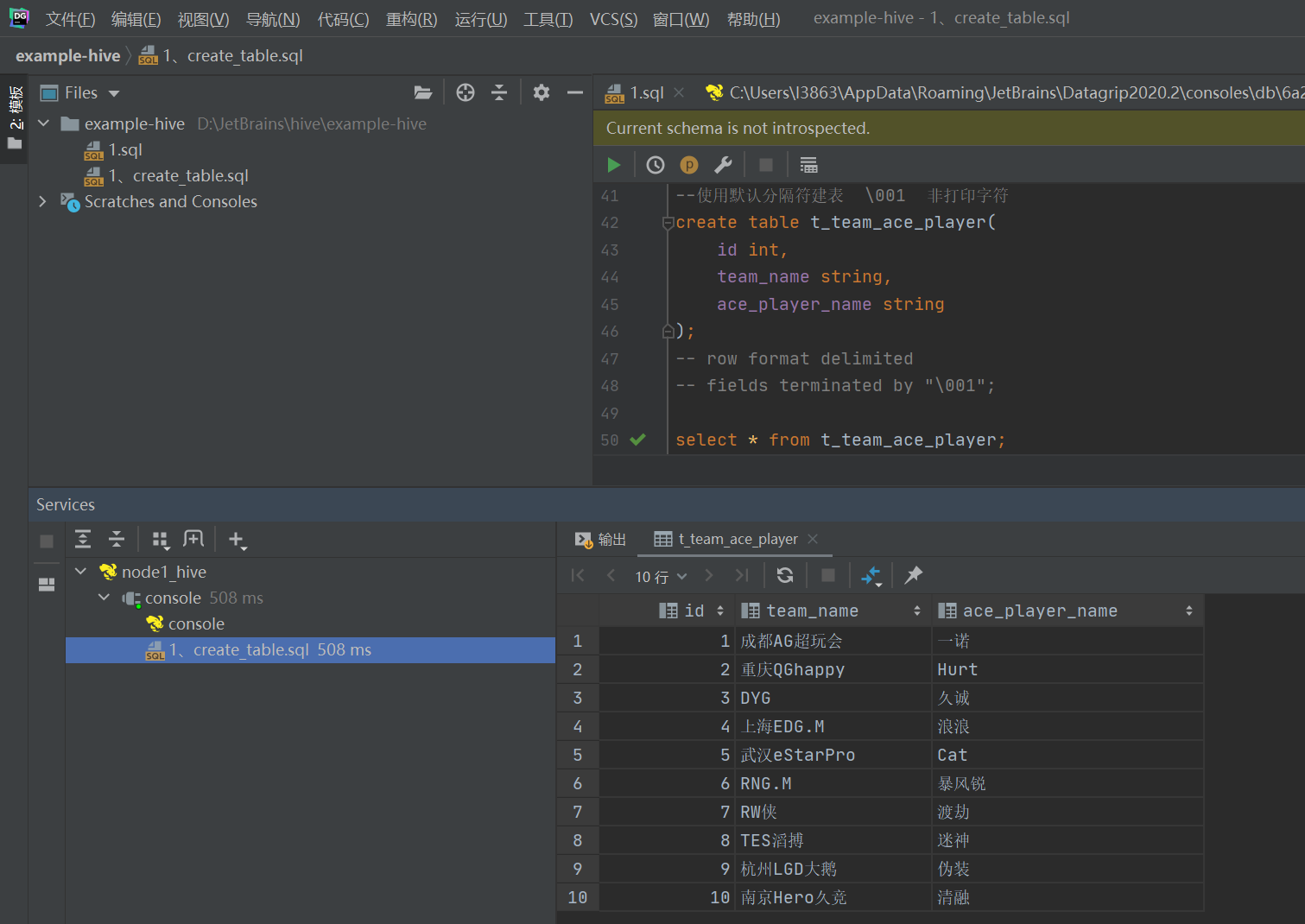
接下来给大家说说我昨晚的课程内容吧!老师讲得是SCRAPY下载图片:
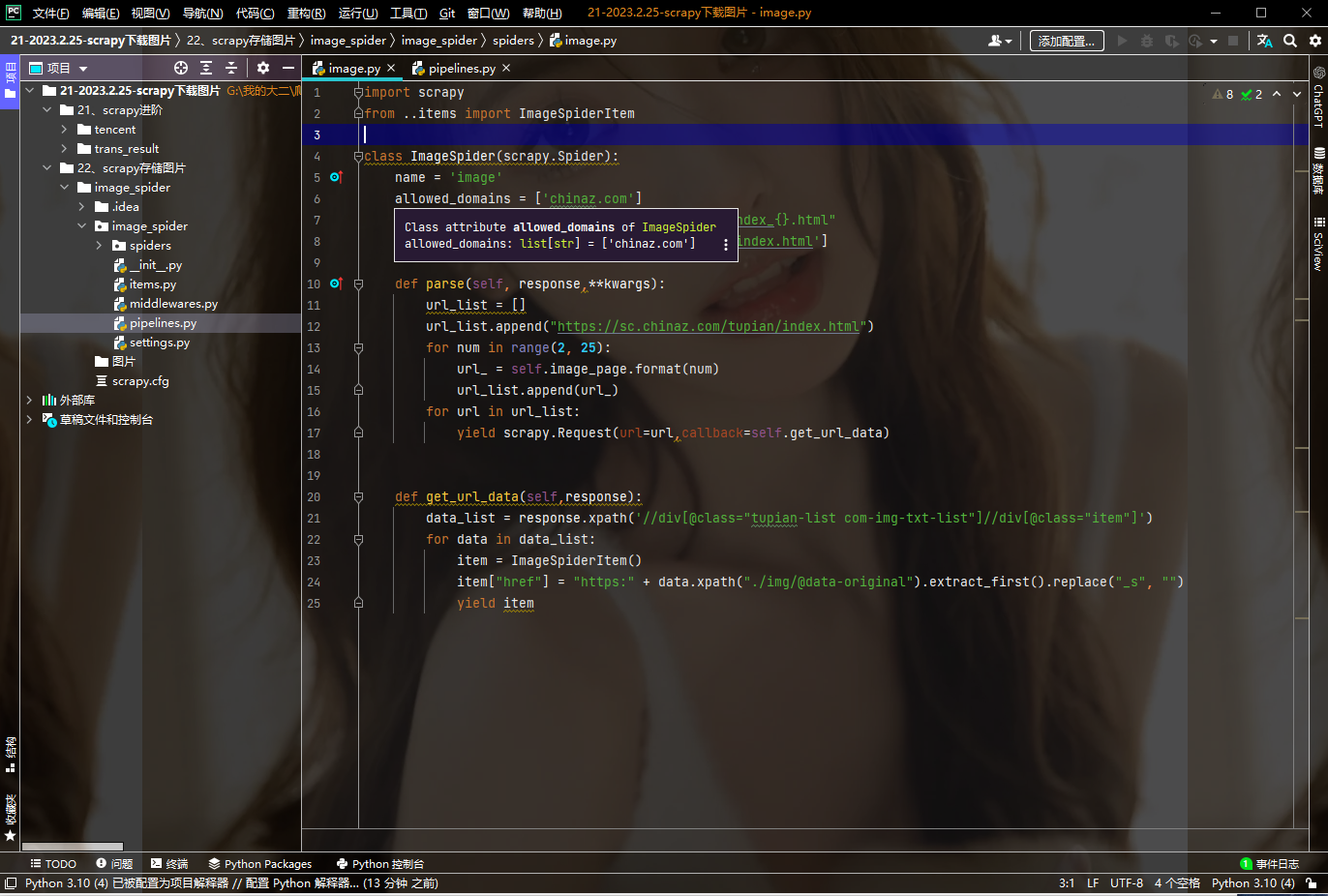
先在自己的SPIDER里面构建需要抓取的URL,然后提取图片链接并且封装在item里面。
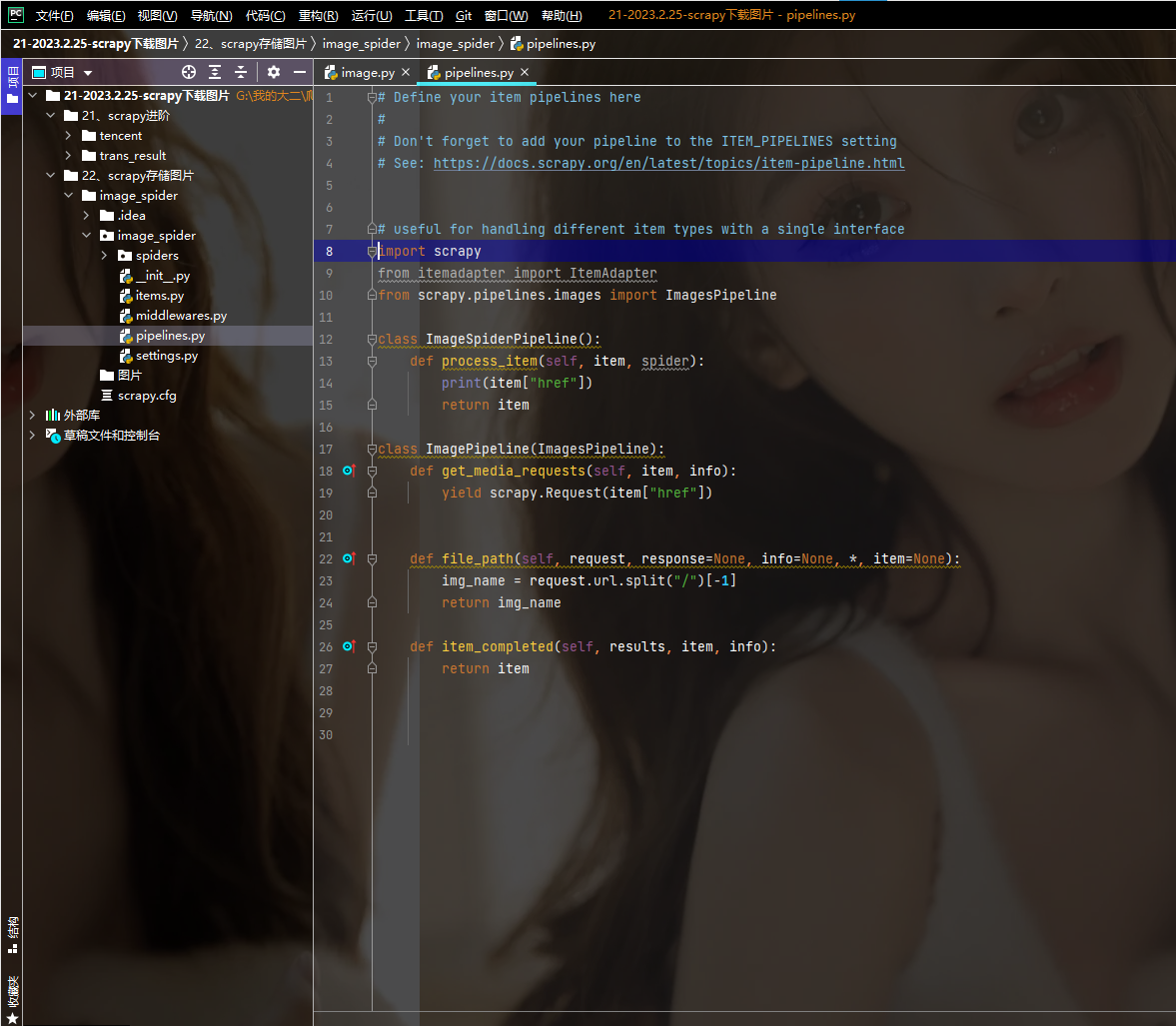
分析上图代码,可见用SCARAPY下载图片需要在管道里面引入一个类:ImagePipeline,然后构造一个类并且继承于ImagePipeline。然后在类里面重写三个函数,分别是get_media_requests,file_path,item_completed;他们的功能分别是向图片链接发起请求,给图片起名字,返回(item)
下面对这三个功能分别做解释:先来看看管道里引入类ImagePipeline的源码,找到函数get_media_requests:
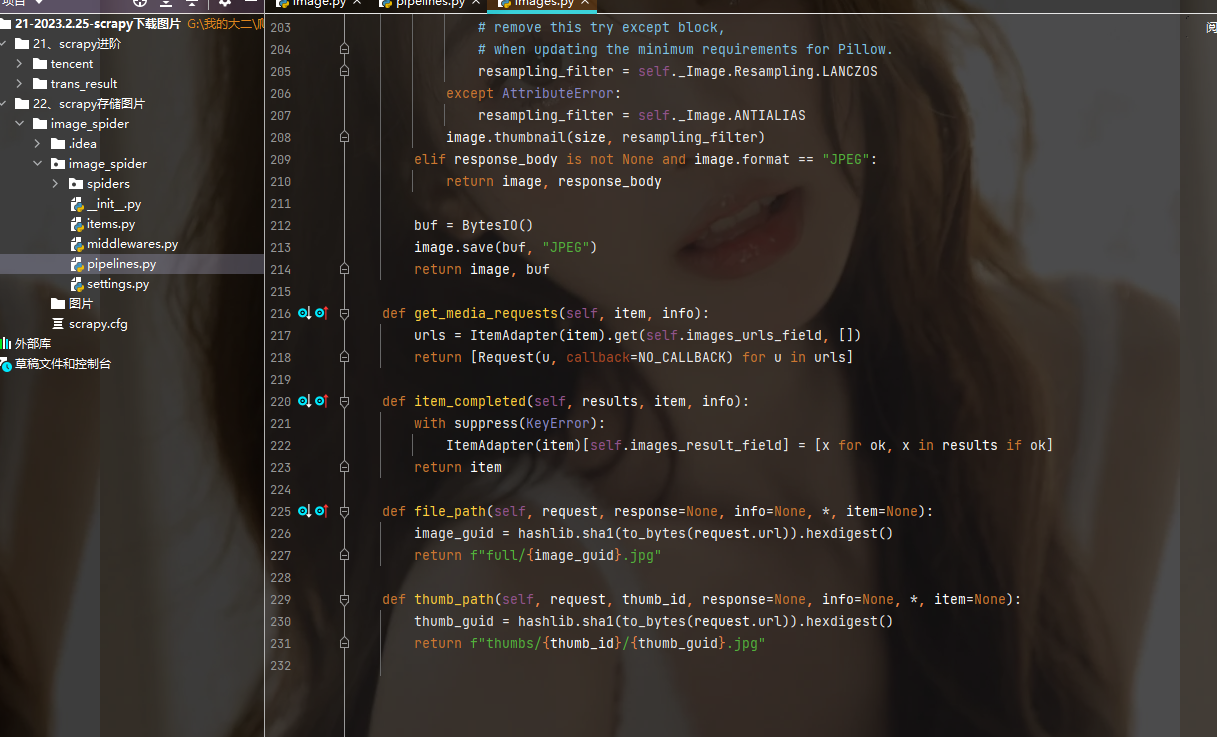
可见函数get_media_requests返回的数据类型是一个列表,并且这个列表是列表推导式生成的,其实列表里面存储的就是每张图片的二进制数据。至于函数item_completed,他单纯的用来返回item,没有这个函数是无法返回ITEM的,但是实现整个代码业务逻辑需要返回item,所以设计者就发明了:item_completed这个函数。
下面看看设置:
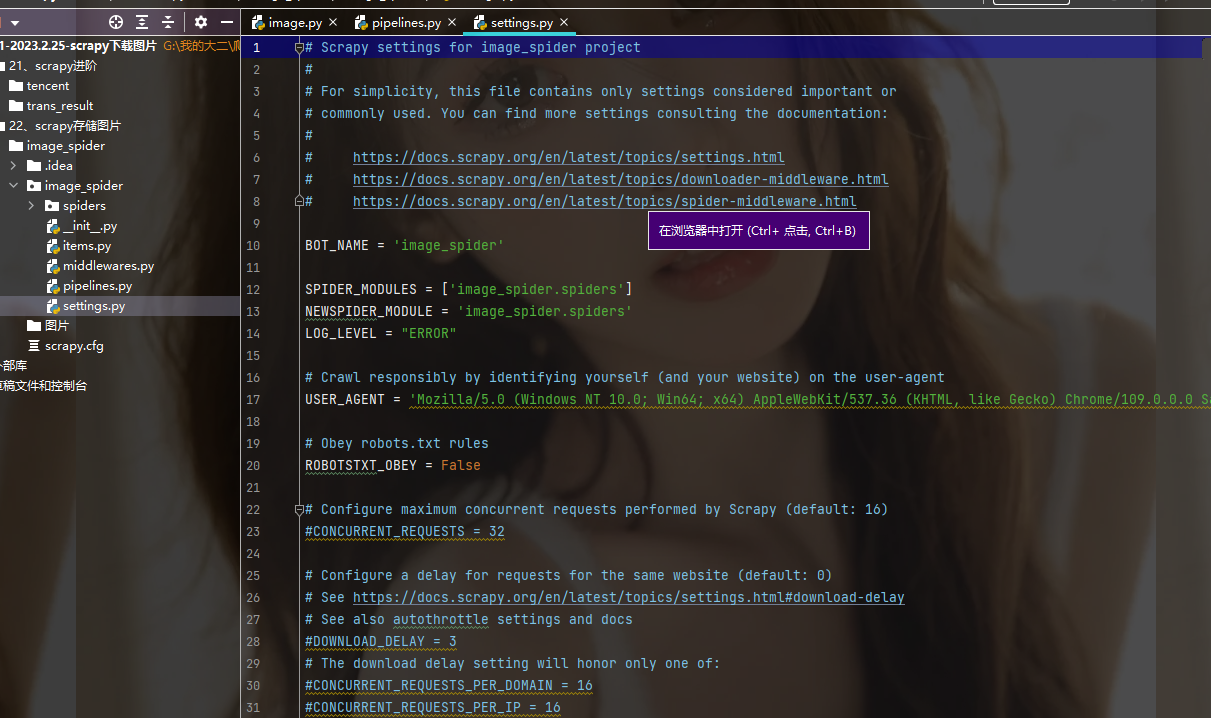
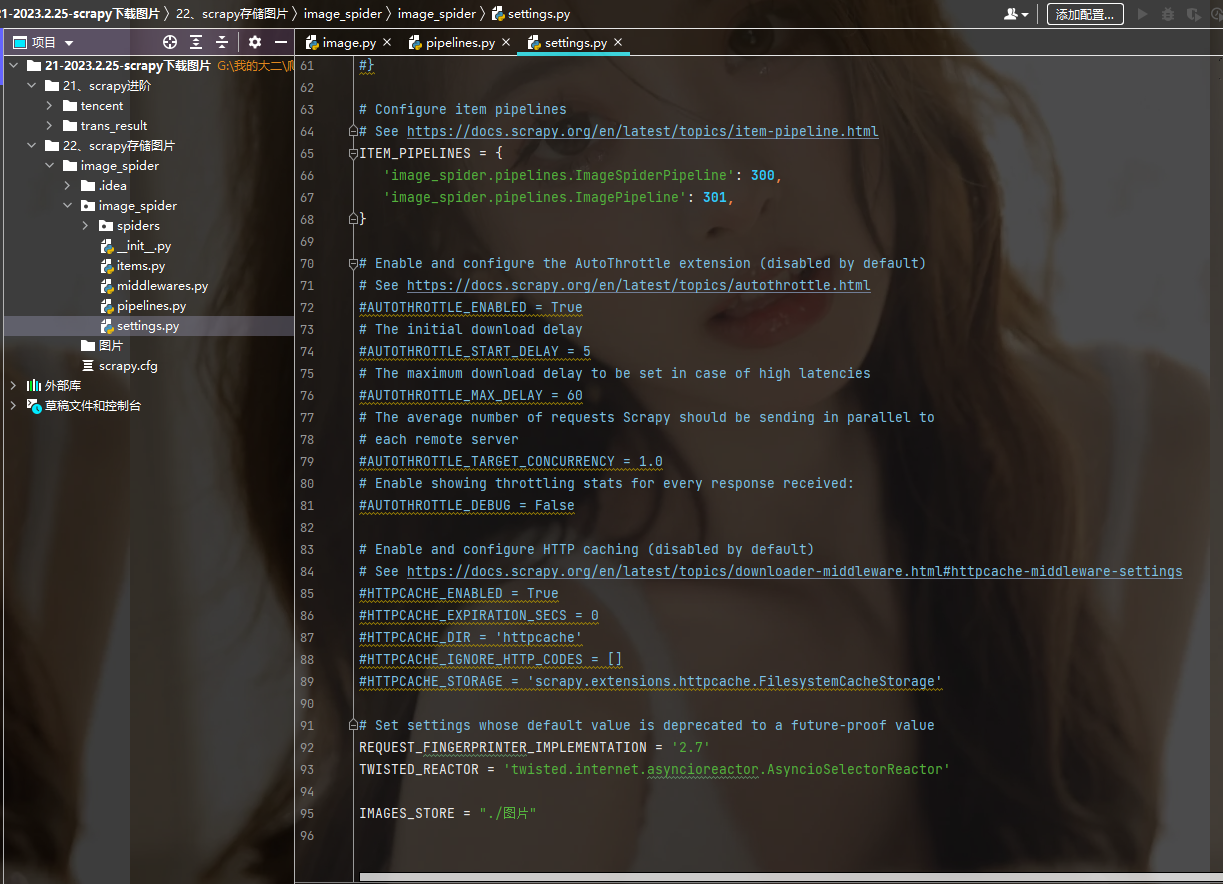
可见,在settings里面设置了日志等级LOG_LEVEL = "ERROR",添加了USER_AGENT ,并且修改了ROBOTS协议ROBOTSTXT_OBEY = False,下面还打开了管道,最后面添加了一个图片保存的位置:
IMAGES_STORE = "./图片"
项目跑起来速度非常快,不到一分钟就下载了一千多张高清大图,相比于之前用REQUSESTS写的多线程,多进程,效率都有显著的提升!这是因为scrapy基于TWISTED,他本身就是异步爬取,所以底层代码量虽然很大,但应用在在爬取大量页面,对大量URL发起请求时速度却是最快的。
如果用requests向大量URL发起请求,requests很容易崩溃,这就是为什么我们要学习scrapy的好处:在企业里工作,很多时候需要爬取的页面就是几千页,那么发起请求就得有成千上万次,若是不用scrapy,就无法完成工作任务!
暂时先分享这么多吧,希望大家都能在学习过程当中都能有所收获,拿到自己满意的兼职和 offer,如想获取更多资料或者联系加群,可以关注我们新课的微信公众号哦!
![[架构之路-121]-《软考-系统架构设计师》-计算机体系结构 -3-汇编语言与ARM系统的初始化](https://img-blog.csdnimg.cn/img_convert/a61431ba399354b5d5fd596471fdbc23.png)