标题:Information Extraction from Resume Documents in PDF Format
下载地址:https://library.imaging.org/ei/articles/28/17/art00013
长度:8页
发表时间:2016
引用量cite=27
先读标题、摘要、结论、
然后 methods/experiment design,result analysis
(1)文章的概要。介绍这篇文章讲的什么?模型是什么?
从PDF格式的简历中提取信息
(2)文章的实现流程及实现难度
第二步,然后每个blocks可以使用条件随机场来进行分类。分类的时候使用的特征有两种 ,一种是内容为基础的特征content-based features,另外一种是从PDF文件中解析出来的页面布局的特征 layout based features which are parsed from PDF documents.
layout-based features这一特征,使得平均F1 score提高了22%。
two-layer model
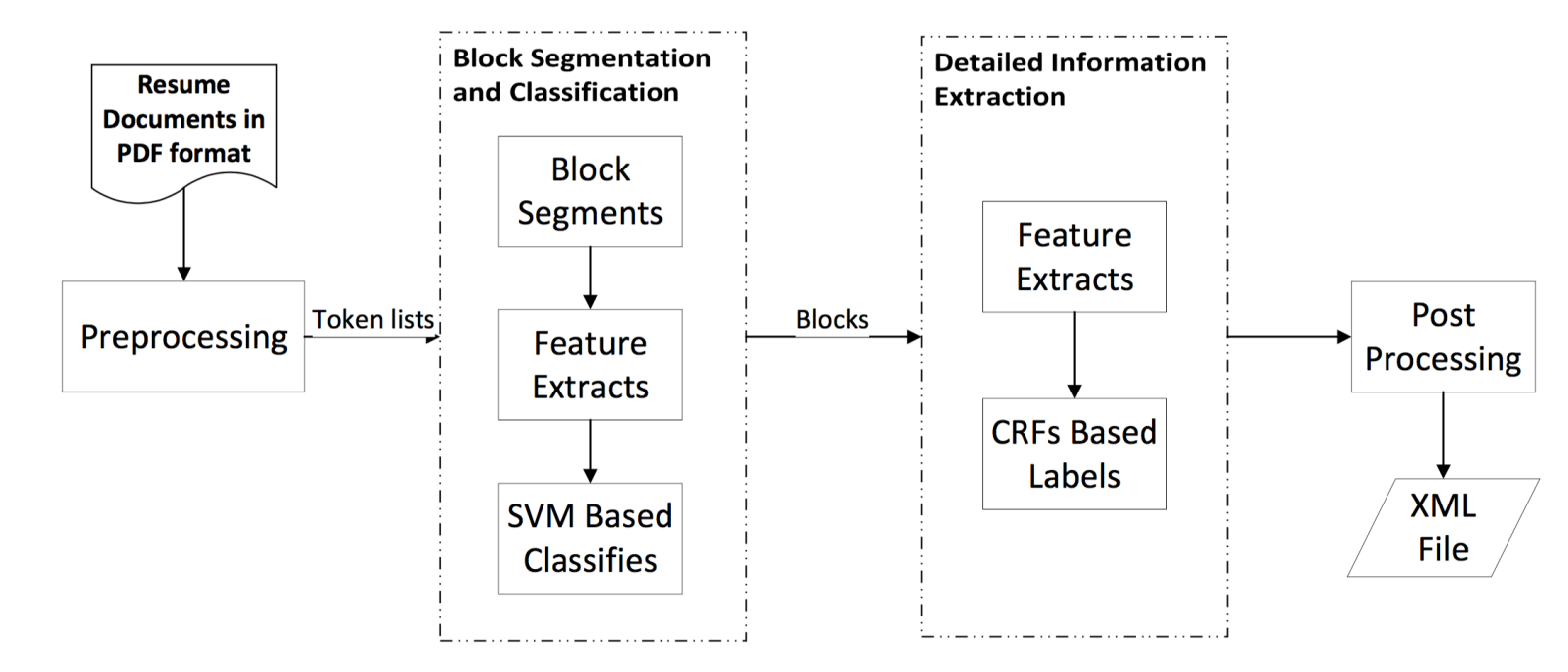
Step1 PreProcessing预处理
这一步其实就是分词segmentation。分词以前,每个英文单词叫做character。分词以后,一个词或几个词组成的一个语义块,被称为token。下面这个分词的过程,就是在merge characters into tokens的过程。
先把简历文件resume document中的每个文字字符解析parses出来放到一个文字列表character list中。然后,我们从左到右遍历每一个字符,按照下面这两个准则进行分词。
-1- 如果连续的两段字符successive characters之间的具备以下几个特性,我们将把他们拆开split。(1)字号不同或者字体不同font style(2)两个字符character之间的空gap大于某个阈值fixed threshhold
-2- 如果遍历的当前字符是一个标点符号punctuations(比如双引号,括号,冒号,逗号),那么就把这个标点和这个标点以前的字符,标点之后的字符拆开separate。但是注意,下面这两个情况不做分词,不切开(1)如果这个标点是破折号,就不要做拆分(2)如果current character是一个period(英文句号那个小点),比如 Ph.D., Dr., Prof.,这些都不要拆开。
针对文章的layout布局排版信息也进行记录:像字体名字font name、字号大小font size、方框bounding box
这一步预处理以后,为了避免打错标签mis-tagging,我们会使用heuristic rules去merge合并tokens或者split拆分tokens
Step2 Block Segmenting and Classifying
2.1 Segmenting
我猜测这一步就是把上一步的切好的语义块token,再次进行合并,组成一个个block。这一步其实就是特征工程,这一步,分好block,为后面的信息提取information extraction步骤提供尽可能好的特征
根据前面定义好的简历hierarchical logical structure层次逻辑结构,整个文件document会被分割成一个个blocks。分割好的这一个个block对都应逻辑结构logic structure的一个高层次块high-level block.(也没看懂,具体是怎么做的)
使用的方法是递归自下而上算法recursively bottom-up algorithm.以把行与行之间空当大小作为标准,对他们进行排序。小的block被merge进更大的block里面。(没懂什么意思)
一些基于文件布局排版document layout segmentation的信息会被用来阻止prevent错误分割mis-segmenting和分割的过多over-segmenting了.layout information包括 font size, font style, blank space,alignment。举个例子说明,比如说有简历中有一段text是被加粗的,那么这段被加粗的字可能是这个block的title。那么这个title就不应该和之间的preceding block进行合并,而是应该单独拿出来。
这里注意一个block里面应该有多少个词组成,这个词数block size是一个超参数。后面我们会做实验展示这个把这个超参数调小或者调大,最终performance score是多少,从而带着你找到一个最优的block size的数字。
2.2 Block classification using a SVM model
用SVM判断每个block是属于什么category的,多分类任务。训练分类任务用的dataset是label过的。工具用的是libSVM。
2.3 Feature Extraction
根据启发式规则heuristic rules来把一页纸的内容分割成多个blocks(什么启发式算法你讲出来)。分割是根据内容content和排版布局layout来划分
分类是用SVM将这些block分类成pre-defined category,分类的依据是content内容大意和layout排版布局。
排版布局的block被映射成简历文件的逻辑架构Then layout blocks are mapped to the logical structure of the resume document
Step3 Detailed Information Extraction
我们将detailed information extraction这个问题,转化成了打一系列标签的问题。
只有教育背景和个人信息这两个block被单独挑出来进一步信息提取。其他的block都是对一个block打一个tagging标签就结束了,而不会进行进一步的信息抽取。
Step4 Post Processing
第一层: high-level blocks.
第二层:低层块的相关细节信息relevant detailed information in low-level blocks
(3)文章值得借鉴的地方以及启发
整个模型的效果:the average F1-score of the hierarchical extraction model = 72.78%, which is 25 percent higher thanthe flat model
(4)读完本文的疑问
a hierarchical extraction method,分层如何体现?什么叫分层模型?
hierarchical logical structure这是什么?层次逻辑结构?