考书目《人工智能之机器视觉》–程晨
1.从计算机读取一张图片显示
##获取图片
import cv2
im=cv2.imread("im.jpg")
cv2.imshow("my",im)
cv2.waitKey()
cv2.destroyAllWindows()
2.显示视频帧
import cv2
#cap = cv2.VideoCapture("video.mp4")获取video.mp4.的视频
cap = cv2.VideoCapture(0) #0默认电脑内置摄像头
while True:
ret,frame = cap.read()#read()含有两个返回值
if ret==True:
cv2.imshow("cap",frame)
if cv2.waitKey(0) & 0xFF == ord('q'):
break
cap.release()#释放是摄像头
cv2.destroyAllWindows()#释放opencv打开的所有窗口
3.图像处理引入numpy模块,
(1)计算向量的内积和矩阵使用dot()
x=[1,2,3]
y=[4,5,6]
则numpy.dot(x,y)的结果`
1*4+2*5+3*6=32
4.图像的翻转
图像的翻转函数flip(),两人参数,第一个是要翻转的图片,第二个是图像翻转的模式,0表示垂直翻转(沿着x轴翻转),1表示水平翻转(沿着y轴翻转).另外保存图片函数imwrite(),两个参数,第二个是要保存的图片,第一个参数是新图片的名字
#图片翻转和保存
import cv2
img=cv2.imread("im.jpg")
res= cv2.flip(img,1)#水平翻转
cv2.imshow("ims1.jpg",img)
cv2.imshow("ims.jpg",res)
cv2.imwrite("save.jpg",res)#保存
cv2.waitKey()
cv2.destroyAllWindows() # 释放opencv打开的所有窗口
5.图像的平移
解释 img.shape[:2]:
img.shape[:2] 取彩色图片的长、宽。
如果img.shape[:3] 则取彩色图片的长、宽、通道。
关于img.shape[0]、[1]、[2]
img.shape[0]:图像的垂直尺寸(高度)
img.shape[1]:图像的水平尺寸(宽度)
img.shape[2]:图像的通道数
在矩阵中,[0]就表示行数,[1]则表示列数
仿射变换,指一个向量空间进行线性变换+平移变成另外一个向量空间,它需要一个变换矩阵,而由于仿射变换较为复杂,一般很难找出这个矩阵,于是opencv提供了cv2.getAffineTransform()
cv2.getAffineTransForm()通过找原图像中三个点的坐标和变换图像的相应三个点坐标,创建一个2X3的矩阵。最后这个矩阵会被传给函数cv2.warpAffine()。代码如下图
#图片平移
import cv2
import numpy
img=cv2.imread("im.jpg")
rows,cols =img.shape[:2] #彩色图片的长、宽,图片像素的行数,列数返回给rows,cols
p1=numpy.float32([[0,0],[cols-1,0],[0,rows-1]])
p2=numpy.float32([[25,40],[cols-1+25,40],[25,rows-1+40]])
M= cv2.getAffineTransform(p1,p2)#自动求解M的函数
res = cv2.warpAffine(img,M,(cols,rows))# 仿射变换
cv2.imshow("origin.jpg",img)
cv2.imshow("new",res)
cv2.imwrite("save.jpg",res)#保存
cv2.waitKey()
cv2.destroyAllWindows() # 释放opencv打开的所有窗口
仿射变换,指一个向量空间进行线性变换+平移
变成另外一个向量空间,它需要一个变换矩阵,而由于仿射变换较为复杂,
一般很难找出这个矩阵,
于是opencv提供了cv2.getAffineTransform(),
cv2.getAffineTransForm()通过找原图像中三个点
的坐标和变换图像的相应三个点坐标,创建一个2X3的矩阵。
最后这个矩阵会被传给函数cv2.warpAffine()

opencv提供了一个根据旋转角度和旋转中心的自动求解M矩阵函数-getRotationMatrix2D()
6.图片的缩放
#图片缩放
import cv2
import numpy
img=cv2.imread("im.jpg")
res = cv2.resize(img,(300,300)) #缩放
cv2.imshow("origin.jpg",img)
cv2.imshow("new",res)
cv2.imwrite("save.jpg",res)#保存
cv2.waitKey()
cv2.destroyAllWindows() # 释放opencv打开的所有窗口
7.计算机视觉有三种常用的色彩空间,灰度,BGR和HSV,灰度通过去除彩色信息来转换为灰阶,灰阶彩色空间对中间处理特别好,如人脸检测就是需要灰度转换。
要将BGR图片转换为HSV使用的函数是cvtColor()函数。参数1是转换的函数,参数2是转换的形式。cvtColor()函数能够转换为任何色彩空间,只需要修改第二个参数。

7.卷积运算



OpenCV用filter2D()函数是实现卷积操作,
#进行垂直边缘提取
kernel= numpy.array([[矩阵]])
edge_v =cv2.fliter2D(img,kernel)
#进行水平边缘提取
edge_v =cv2.fliter2D(img,kernel.T)#kernel.T表示kernel的转置
8.滤波器
线性滤波方式有均值滤波blur()函数和高斯滤波Gaussian Blur()函数

(1)均值blur()

(5,5)表示卷积核的大小,越大图片越模糊
(2)高斯滤波Gaussian Blur
9.Canny 边缘检测
Canny比较简单的边缘检测函数,例子:

效果:



10.人脸检测


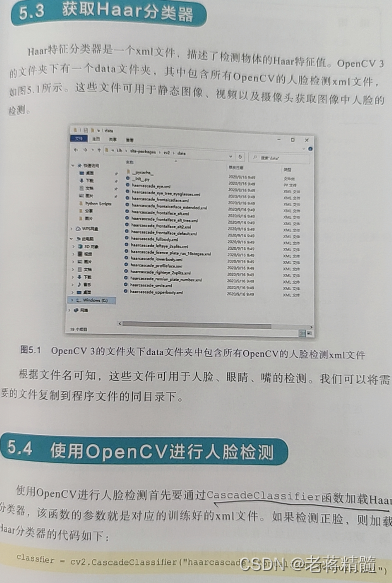
使用OpenCV人脸检测通过CascadeClassifier()函数加载Haar分类器,该函数的参数就是对于训练好的xml文件,代码:
classfier=cv2.CascadeClassifier("harrcascade_frontalface_default.xml")(xml放到工程目录下)
程序:detectMultiScale()进行人脸识别
#人脸检测
import cv2
import numpy
img=cv2.imread("im.jpg")
grey= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
classfier=cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
faceRects =classfier.detectMultiScale(grey,scaleFactor=1.1,minNeighbors=3,minSize=(32,32))
for faceRect in faceRects:
x,y,w,h =faceRect
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,255),2)
cv2.imshow("origin.jpg",img)
cv2.waitKey()
cv2.destroyAllWindows() # 释放opencv打开的所有窗口
解释:

检测到人脸了,还可以在人脸范围内检测眼睛
#检测眼睛
import cv2
import numpy
img=cv2.imread("im.jpg")
grey= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
classfier=cv2.CascadeClassifier("haarcascade_eye.xml")
faceRects =classfier.detectMultiScale(grey,scaleFactor=1.1,minNeighbors=3,minSize=(32,32))
for faceRect in faceRects:
x,y,w,h = faceRect
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
#人脸识别区域
face_img = grey[y:y+h,x:w+x]
eyes = classfier.detectMultiScale(face_img,scaleFactor=1.1,minNeighbors=6,minSize=(30,30))
for ex, ey, ew, eh in eyes:
cv2.rectangle(img, (x+ex,y+ey),(x+ex+ew,y+ey+eh),(0, 255, 0), 2)
cv2.imshow("origin.jpg",img)
cv2.waitKey()
cv2.destroyAllWindows() # 释放opencv打开的所有窗口
视频中的人脸识别