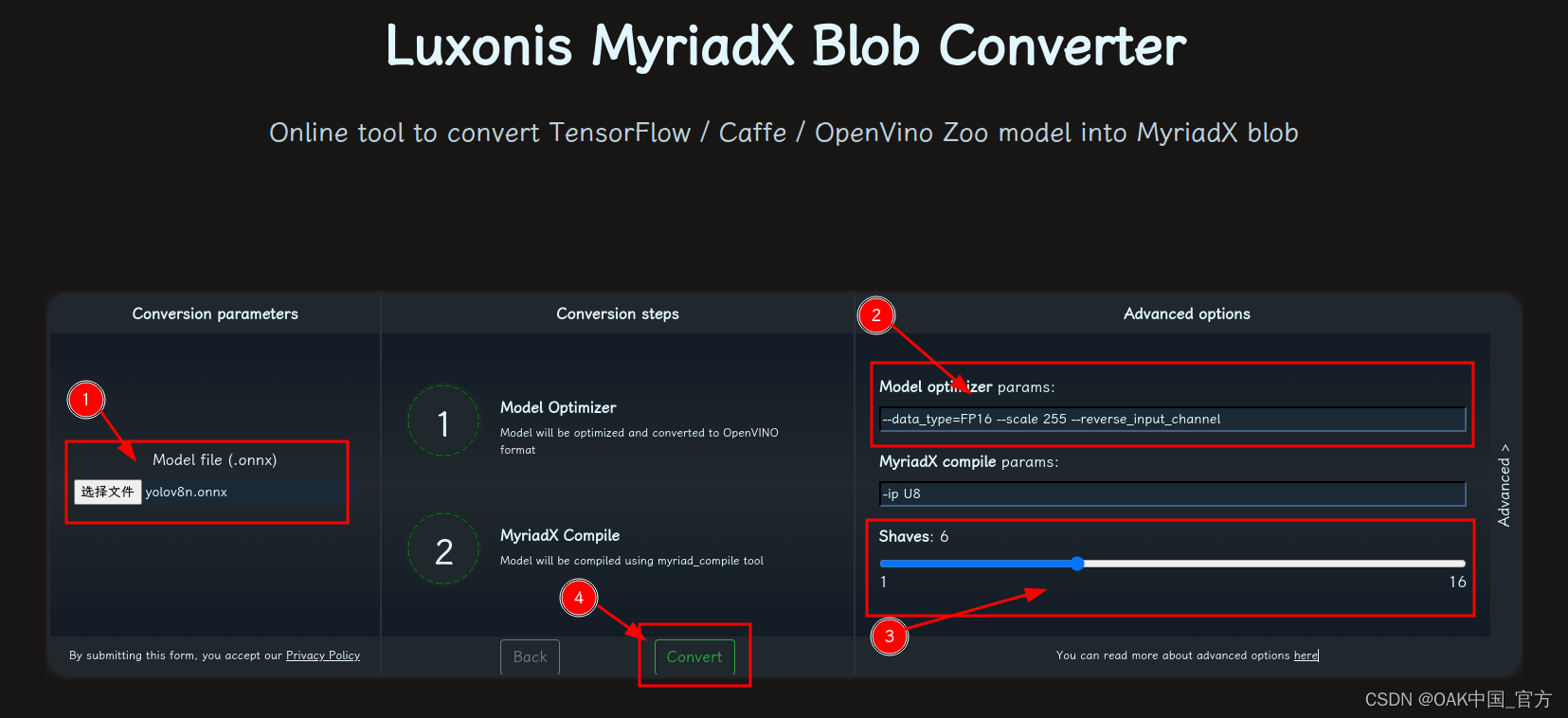
目录
1--nn.Conv2d()参数量的计算
2--nn.Linear()参数量计算
3--显存占用量比较
1--nn.Conv2d()参数量的计算
conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=1)计算公式:
Param = in_c * out_c * k * k + out_c;
in_c 表示输入通道维度;
out_c 表示输出通道维度;
k 表示卷积核大小;
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=1)
def forward(self, x):
return self.conv1(x)
if __name__ == "__main__":
model = Model().cuda(0)
x = torch.rand(2, 3, 6, 8).cuda(0)
y = model(x)
Param_sum = sum([param.nelement() for param in model.parameters()])
print("Param.sum: ", Param_sum)上面代码中,nn.Conv2d() 的参数量为 3 * 64 * 1 * 1 + 64 = 256;

2--nn.Linear()参数量计算
linear1 = nn.Linear(in_features=3, out_features=64)计算公式:
Param = in_f * out_f + out_f;
in_f 表示输入特征维度;
out_f 表示输出特征维度;
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(in_features=3, out_features=64)
def forward(self, x):
x = x.permute(0, 2, 3, 1).reshape(-1, 3)
return self.linear1(x)
if __name__ == "__main__":
model = Model().cuda(0)
x = torch.rand(2, 3, 6, 8).cuda(0)
y = model(x)
Param_sum = sum([param.nelement() for param in model.parameters()])
print("Param.sum: ", Param_sum)上面代码中,nn.Conv2d() 的参数量为 3 * 64 + 64 = 256;

3--显存占用量比较
一般情况下,同维度操作的 nn.Conv2d() 会比 nn.Linear() 的显存占用量要高,即使两者的参数量一致;
比如上面代码中,通过 nvidia-smi 发现,第一个模型会比第二个模型的显存占用量要高;



![[11]云计算|简答题|案例分析|云交付|云部署|负载均衡器|时间戳](https://img-blog.csdnimg.cn/img_convert/49e101c786c788cd071f4c16f911d83b.gif)