一个网站往往由很多相互关联的网页组成,每个网页上都可能包含我们所要关心的数据,那么我们怎么样获取这些数据呢?显然我们必须穿梭于各个网页之间,那么按什么样的规则穿梭呢?常用的有深度优先与广 度优先方法。为了说明这两种方法的工作过程,本节特意设计一个简单的网站。
1. Web服务网站
设计好books.html, program.html, database.html, netwwork.html, mysql.html, java.html, python.html等网页文件以utf-8的编码存储在文件夹,各个文件的内容如下:
books.html
<h3>计算机</h3>
<ul>
<li><a href="database.html">数据库</a></li>
<li><a href="program.html">程序设计</a></li>
<li><a href="network.html">计算机网络</a></li>
</ul>database.html
<h3>数据库</h3>
<ul>
<li>
<ahref="mysql.html">MySQL数据库</a>
</li>
</ul>program.html
<h3>程序设计</h3>
<ul>
<li><ahref="python.html">Python程序设计</a></li>
<li><ahref="java.html">Java程序设计</a></li>
</ul>network.html
<h3>计算机网络</h3>mysql.html
<h3>MySQL数据库</h3>python.html
<h3>Python程序设计</h3>java.html
<h3>Java程序设计</h3>然后再用 FLask 设计一个 server.py 的 Web 程序来呈现它们:
import flask
import os
app=flask.Flask(__name__)
def getFile(fileName):
data=b""
ifos.path.exists(fileName):
fobj=open(fileName, "rb")
data=fobj.read()
fobj.close()
return data
@app.route("/")
defindex():
return getFile("books.html")
@app.route("/<section>")
def process(section):
data=""
if section!="":
data=getFile(section)
return data
if__name__=="__main__":
app.run()
搭建完 web 网站,访问http://127.0.0.1:5000网址后执行 index 函数,返回 books.html的网页
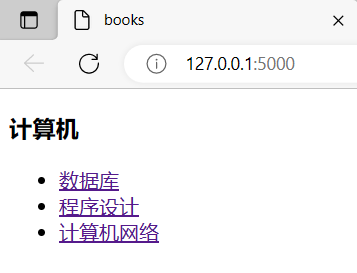
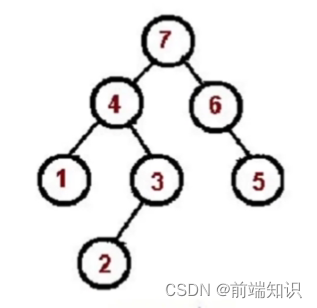
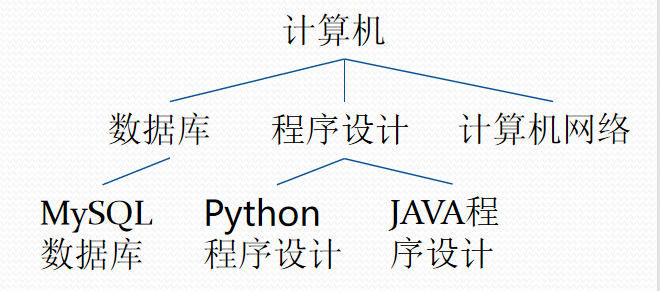
这些网页的结构实际上是一棵树:
2. 递归程序爬取数据
设计一个客户端程序client.py爬取这个网站各个网页的<h3>的标题值,
设计的思想如下:
1. 从books.html出发;
2.访问一个网页,获取<h3>标题;
3.获取这个网页中所有<a>超级链接的 href 值形成links列表;
4.循环links列表,对于每个链接link都指向另外一个网页,递归回到 2
5.继续links的下一个link,直到遍历所有link为止;
因此程序是一个递归调用得过程,
客户端程序 client.py 如下:
from bs4 import BeautifulSoup
import urllib.request
def spider(url):
try:
data=urllib.request.urlopen(url)
data=data.read()
data=data.decode()
soup=BeautifulSoup(data, "lxml")
print(soup.find("h3").text)
links=soup.select("a")
for link in links:
href=link["href"]
url=start_url+"/"+href
# print(url)
spider(url)
except Exceptionas err:
print(err)
start_url="http://127.0.0.1:5000"
spider(start_url)
print("The End")
运行结果如下:
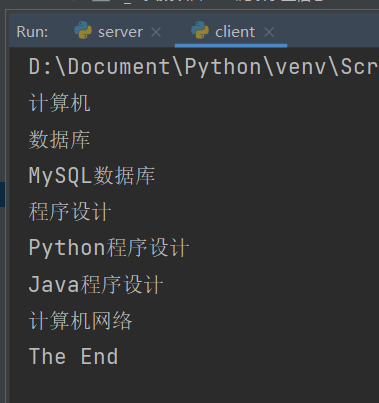
显然这种递归程序都是采用深度优先得方法遍历树。
3. 深度优先爬取数据
如果不使用递归程序实现深度优先的顺序爬取网站数据,也可以设计一个栈Stack 来完成。Python中的列表list就是一个栈,很容易设计自己的一个栈Stack类:
class Stack:
def __init__(self):
self.st= []
def pop(self): # 出栈
return self.st.pop()
# pop([index=-1]) 默认弹出的是列表的最后一个元素。
def push(self, obj): # 入栈
self.st.append(obj)
def empty(self): # 判断栈是否为空
return len(self.st) ==0采用 Stack 类后可以设计深度优先的顺序爬取数据的客户端程序的思想如下:
第一个url入栈;
如果栈为空程序结束,如不为空,出栈一个url,爬取它的<h3>标题值;
获取url站点的所有超级链接<a>的 href 值,组成链接列表links,把这些链接全部压栈;
回到 2
客户端程序 client2.py 如下:
# 深度优先爬取数据,使用list实现栈类,实现网站数据的爬取
import urllib.request
from bs4 import BeautifulSoup
class Stack:
def __init__(self):
self.st= []
def pop(self): # 出栈
return self.st.pop() # 与广度相比,出栈最后一个元素
# pop([index=-1]) 默认弹出的是列表的最后一个元素。
def push(self, obj): # 入栈
self.st.append(obj)
def empty(self): # 判断栈是否为空
return len(self.st) ==0
def spider(url):
stack=Stack()
stack.push(url)
while not stack.empty():
url=stack.pop()
try:
data=urllib.request.urlopen(url)
data=data.read().decode()
soup=BeautifulSoup(data, 'lxml')
print(soup.find("h3").text)
links=soup.select("a")
for i in range(len(links) -1, -1, -1):
href=links[i]["href"]
url=start_url+"/"+href
stack.push(url)
except Exceptionas err:
print(err)
start_url="http://127.0.0.1:5000"
spider(start_url)
print("The End")
运行结果如下:
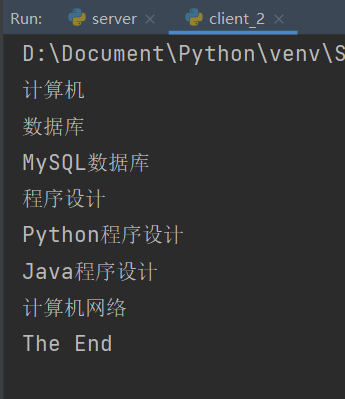
4. 广度优先爬取数据
遍历网站树还有一种广度优先的顺序,这要使用到队列,在Python中实现一个队列十分简单,Python中的列表list就是一个队列,很容易设计自己的一个队列Queue类:
class Queue:
def __init__(self):
self.st= []
def fetch(self): # 出列
return self.st.pop(0) # 与深度优先相比
# 弹出队列第一个元素(index=0)
def enter(self, obj): # 入列
self.st.append(obj)
def empty(self): # 判断列是否为空
return len(self.st) ==0设计广度优先的顺序爬取数据的客户端程序的思想如下:
1. 第一个url入列;
2. 如果列空程序结束,如不为空出列一个url,爬取它的<h3>标题值;
3. 获取url站点的所有超级链接<a>的href值,组成链接列表links,把这些 链接全部入 队列;
4. 回到 2
客户端程序 client3.py 如下:
# 广度优先爬取数据
from bs4 import BeautifulSoup
import urllib.request
class Queue:
def __init__(self):
self.st = []
def fetch(self): # 出列
return self.st.pop(0) # 与深度优先相比
# 弹出队列第一个元素(index=0)
def enter(self, obj): # 入列
self.st.append(obj)
def empty(self): # 判断列是否为空
return len(self.st) == 0
def spider(url):
queue = Queue()
queue.enter(url)
while not queue.empty():
url = queue.fetch()
try:
data = urllib.request.urlopen(url)
data = data.read()
data = data.decode()
soup = BeautifulSoup(data, "lxml")
print(soup.find("h3").text)
links = soup.select("a")
for link in links:
href = link["href"]
url = start_url + "/" + href
queue.enter(url)
except Exception as err:
print(err)
start_url = "http://127.0.0.1:5000"
spider(start_url)
print("The End")