一、集群
1.1 为什么要使用集群
前面我们介绍了如何安装及运行 RabbitMQ 服务,不过这些是单机版的,无法满足目前真实应用的 要求。如果 RabbitMQ 服务器遇到内存崩溃、机器掉电或者主板故障等情况,该怎么办?单台 RabbitMQ 服务器可以满足每秒 1000 条消息的吞吐量,那么如果应用需要 RabbitMQ 服务满足每秒 10 万条消息的吞 吐量呢?购买昂贵的服务器来增强单机 RabbitMQ 务的性能显得捉襟见肘,搭建一个 RabbitMQ 集群才是 解决实际问题的关键。
1.2 搭建步骤
准备好几个队列节点,命名好(比如叫node1、node2……)
配置各个节点的 hosts 文件,让各个节点都能互相识别对方
vim /etc/hosts确保各个节点的 cookie 文件使用的是同一个值
启动 RabbitMQ 服务,顺带启动 Erlang 虚拟机和 RbbitMQ 应用服务(在每台节点上分别执行以 下命令)
rabbitmq-server -detached在从节点执行
rabbitmqctl stop_app
(rabbitmqctl stop 会将 Erlang 虚拟机关闭,rabbitmqctl stop_app 只关闭 RabbitMQ 服务)
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node1
rabbitmqctl start_app(只启动应用服务)集群状态
rabbitmqctl cluster_status需要重新设置用户
创建账号 :
rabbitmqctl add_user admin 123设置用户角色:
rabbitmqctl set_user_tags admin administrator设置用户权限:
rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*"二、镜像队列
2.1 为什么使用镜像队列
如果 RabbitMQ 集群中只有一个 Broker 节点,那么该节点的失效将导致整体服务的临时性不可用,并 且也可能会导致消息的丢失。可以将所有消息都设置为持久化,并且对应队列的durable属性也设置为true, 但是这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘井执行刷盘动作之间存在 一个短暂却会产生问题的时间窗。
通过 publisherconfirm 机制能够确保客户端知道哪些消息己经存入磁盘, 尽管如此,一般不希望遇到因单点故障导致的服务不可用。 引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他 Broker 节点之上,如果集群中 的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。
2.2 搭建步骤
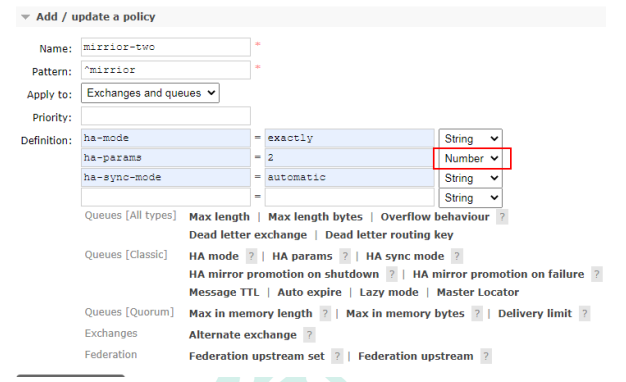
在节点上创建policy即可。
三、实现高可用负载均衡
3.1 使用HAProxy实现负载均衡
HAProxy 提供高可用性、负载均衡及基于 TCPHTTP 应用的代理,支持虚拟主机,它是免费、快速并 且可靠的一种解决方案,包括 Twitter、Reddit、StackOverflow、GitHub 在内的多家知名互联网公司在使用。
HAProxy 实现了一种事件驱动、单一进程模型,此模型支持非常大的井发连接数。
当然,除了HAProxy,市面上还有nginx,lvs,haproxy等软件,他们的区别http://www.ha97.com/5646.html
3.2 Keepalived 实现双机(主备)热备
试想如果前面配置的 HAProxy 主机突然宕机或者网卡失效,虽然 RabbitMQ 集群没有任何故障但是 对于外界的客户端来说,所有的连接都会被断开,结果将是灾难性的。确保负载均衡服务的可靠性同样显得 十分重要。这里就要引入 Keepalived,它能够通过自身健康检查、资源接管功能做高可用(双机热备),实现 故障转移。
四、Federation Exchange
4.1 为什么要使用Federation Exchange
北京的broker和深圳的broker之间相距甚远,网络延迟是一个不得不面对的问题。
假如现在有一个在北京 的业务(Client 北京) 需要连接(broker 北京),向其中的交换器 exchangeA 发送消息,此时的网络延迟很小, (Client 北京)可以迅速将消息发送至 exchangeA 中,就算在开启了 publisherconfirm 机制或者事务机制的 情况下,也可以迅速收到确认信息。
而此时又有个在深圳的业务(Client 深圳)需要向 exchangeA 发送消息, 那么(Client 深圳) (broker 北京)之间有很大的网络延迟,(Client 深圳) 将发送消息至 exchangeA 会经历一 定的延迟,尤其是在开启了 publisherconfirm 机制或者事务机制的情况下,(Client 深圳) 会等待很长的延 迟时间来接收(broker 北京)的确认信息,进而必然造成这条发送线程的性能降低,甚至造成一定程度上的 阻塞。
那么,将业务(Client 深圳)部署到北京的机房可以解决这个问题,但是如果(Client 深圳)调用的另些服务都部 署在深圳,那么又会引发新的时延问题,总不见得将所有业务全部部署在一个机房,那么容灾又何以实现?
这里使用 Federation 插件就可以很好地解决这个问题。






![[数据结构]:05-循环队列(链表)(C语言实现)](https://img-blog.csdnimg.cn/a63177dcd6974290a3eaa455362d19a4.png)