Flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统,能够有效的收集、聚合、移动大量的日志数据。
优点:
使用Flume采集数据不需要写一行代码,注意是一行代码都不需要,只需要在配置文件中随便
写几行配置Flume就会死心塌地的给你干活了
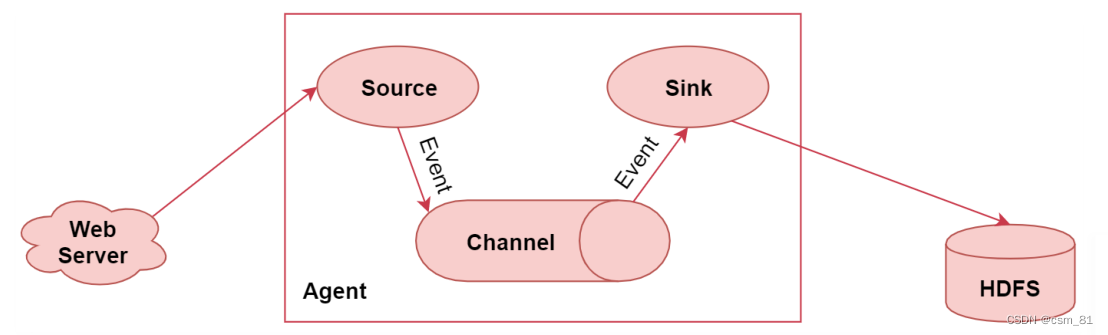
左边的web server表示是一个web项目,web项目会产生日志数据,通过中间的Agent把日志数据采集到HDFS中。
其中这个Agent就是我们使用Flume启动的一个代理,它是一个持续传输数据的服务,数据在Agent内部的这些组件之间传输的基本单位是Event
Flume三大核心组件:Source Channel Sink
从图中可以看到,Agent是由Source、Channel、Sink这三大组件组成的,这就是Flume中的三大核心组件.
其中source是数据源,负责读取数据
channel是临时存储数据的,source会把读取到的数据临时存储到channel中
sink是负责从channel中读取数据的,最终将数据写出去,写到指定的目的地中
Flume的特性
1. 它有一个简单、灵活的基于流的数据流结构,这个其实就是刚才说的Agent内部有三大组件,数据通过这三大组件流动的
2. 具有负载均衡机制和故障转移机制
3. 一个简单可扩展的数据模型(Source、Channel、Sink),这几个组件是可灵活组合的
Flume应用场景:
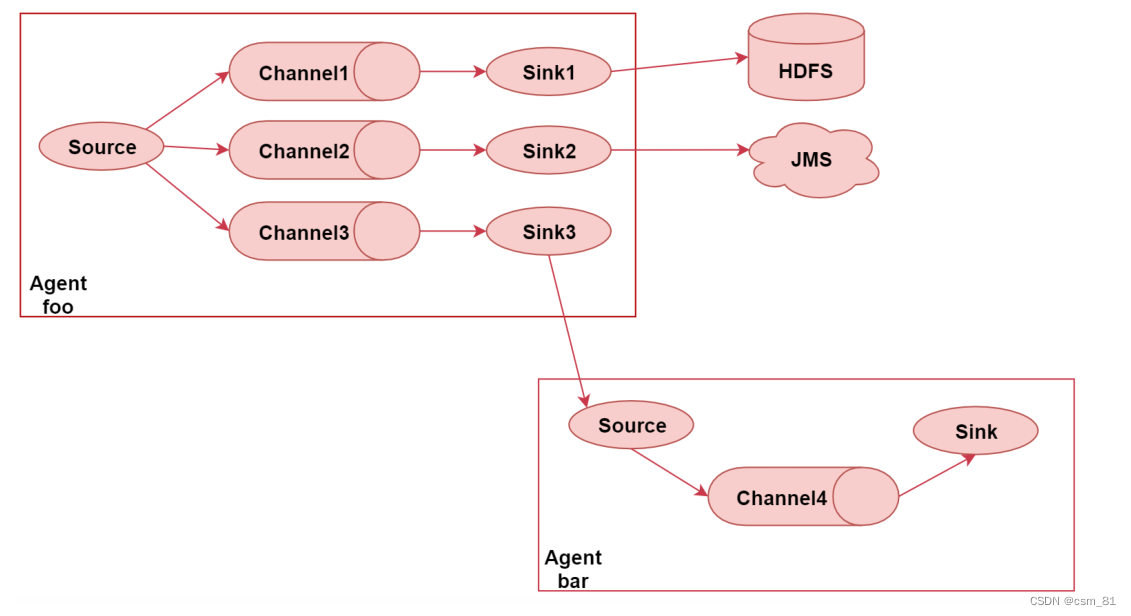
这个图里面一共有两个Agent,表示我们启动了2个Flume的代理,或者可以理解为了启动了2个flume的进程。
首先看左边这个agent,给他起个名字叫 foo
这里面有一个source,source后面接了3个channel,表示source读取到的数据会重复发送给每个
channel,每个channel中的数据都是一样的
针对每个channel都接了一个sink,这三个sink负责读取对应channel中的数据,并且把数据输出到不同的目的地,
sink1负责把数据写到hdfs中
sink2负责把数据写到一个Java消息服务数据队列中
sink3负责把数据写给另一个Agent
Flume中多个Agent之间是可以连通的,只需要让前面Agent的sink组件把数据写到下一
个Agent的source组件中即可。

这个图里面一共启动了四个agent,左边的三个agent都是负责采集对应web服务器中的日志数据,数据采集过来之后统一发送给agent4,最后agent4进行统一汇总,最终写入hdfs。
这种架构的好处是后期如果要修改最终数据的输出目的地,只需要修改agent4中的sink即可,不需要修改agent1、2、3。
但是这种架构也有弊端,
1. 如果有很多个agent同时向agent4写数据,那么agent4会出现性能瓶颈,导致数据处理过慢
2. 这种架构还存在单点故障问题,如果agent4挂了,那么所有的数据都断了。
不过这些问题可以通过flume中的负载均衡和故障转移机制解决




![[数据结构]:05-循环队列(链表)(C语言实现)](https://img-blog.csdnimg.cn/a63177dcd6974290a3eaa455362d19a4.png)