WHAT DO VISION TRANSFORMERS LEARN? A VISUAL EXPLORATION
文章地址
代码地址
摘要
视觉转换器( Vision Transformers,ViTs )正在迅速成为计算机视觉的事实上的架构,但我们对它们为什么工作和学习什么知之甚少。虽然现有研究对卷积神经网络的机制进行了可视化分析,但对ViT的类似探索仍然具有挑战性。在本文中,我们首先解决在ViT上执行可视化的障碍。在这些解决方案的辅助下,我们观察到用语言模型监督(例如, CLIP)训练的ViT中的神经元是由语义概念而不是视觉特征激活的。我们还探索了ViT和CNN之间的潜在差异,我们发现Transformer和它们的卷积对应物一样检测图像背景特征,但它们的预测对高频信息的依赖要小得多。另一方面,两种建筑类型在特征从早期的抽象模式到后期的具体对象的过程中表现出相似的特征。此外,我们表明ViT在除最后一层之外的所有层中都保持空间信息。与以前的工作不同,我们表明最后一层最有可能丢弃空间信息,表现为一个学习的全局池化操作。最后,我们对包括DeiT、CoaT、ConViT、PiT、Swin和Twin在内的多种ViT变体进行大规模可视化,以验证我们方法的有效性。
介绍
实验发现
(1)通过剖析和可视化Transformer架构中的内部表示,我们发现patch tokens在除最后一个注意力块之外的所有层中都保留了空间信息。ViTs的最后一层学习类似于平均池化的token-mixing操作,使得分类头在摄取随机token而不是CLS token时表现出相当的准确率。
(2)在探讨了空间信息的作用后,我们深入探究了视觉通道和卷积神经网络的行为差异。在执行激活最大化可视化时,我们注意到ViTs比CNNs持续生成更高质量的图像背景。因此,我们尝试在推理过程中掩盖图像前景,发现当仅暴露于图像背景时,ViTs始终优于CNNs。这些发现支持Transformer模型从图像中提取多个源的信息,在分布外泛化和对抗鲁棒性上表现出优越的性能的观察。此外,卷积神经网络对图像中的高频纹理信息依赖较大。相比之下,我们发现ViTs即使在从输入中移除高频内容时也表现良好。
(3)虽然只有视觉的模型包含与不同物理对象和形状相对应的简单特征,但我们发现CLIP中的语言监督会导致响应复杂抽象概念的神经元。这包括响应与词性(如修饰语、形容词和介词)相关的视觉特征的神经元,响应广泛视觉场景的"音乐"神经元,甚至响应抽象的发病率概念的"死亡神经元"。
贡献
(1)我们观察到,当将标准的特征可视化方法应用于基于Transformer的模型的相对低维组件,如keys,queries,或者values时,会出现不可解释和对抗的行为。然而,将这些工具应用于position-wise feedforward层的相对高维特征,结果是成功的和信息丰富的可视化。我们对包括ViTs、DeiT、CoaT、ConViT、PiT、Swin和Twin在内的多种基于变压器的视觉模型进行大规模可视化,以验证我们方法的有效性。
(2)我们表明,针对ViT特征的patch-wise激活模式本质上类似于显著图,突出了给定特征所关注的图像区域。这种行为即使在相对较深的层中也持续存在,表明模型保留了块之间的位置关系,而不是将它们用作全局信息存储。
(3)我们比较了ViTs和CNNs的行为,发现ViTs更好地利用了背景信息,对高频、纹理属性的依赖较小。这两种类型的网络在更深的层次上逐步建立更复杂的表示,并最终包含负责检测不同对象的特征。
(4)我们研究了CLIP的自然语言监督对ViTs提取特征类型的影响。我们发现,CLIP训练的模型包含了各种特征,这些特征明显适合于检测与字幕文本对应的图像成分,如介词、形容词和概念范畴。
实验
实验思路
技术路线:基于在像素空间基于梯度做优化,主要目的是观察输入和 feature map 的关系。
优化问题是:
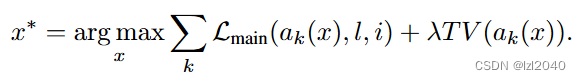
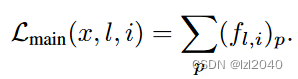
其中:ak表示对x进行增强操作,k表示第几次增强;TV表示正则项,让像素空间更锐化
主体思路:从k次增强的图像中找到Lmain损失最大的,Lmain损失其实就是将这个通道的特征图的所有位置相加,里面的特征向量f是一个通道d上的所有元素的堆叠,其中l表示是第几层,p表示patch。
可视化结果
Query,key和value的可视化结果不好,但是全连接层有更好的可视化结果,因为它向量大小为4倍d,表示更高维度。

解释:我们发现可视化的前馈特征明显比其他层更具有可解释性。我们将其他层可视化的困难归因于ViTs将大量信息打包成仅有768个特征的特性。
ViT空间信息的保留:layer 5有明显的空间信息(黑色部分),last layer就很平均了。如下图:

ViT的某些通道是由背景激活的,也有空间信息。图(a)的左边是识别草和雪,右边的激活图是由背景块产生的,如下图:


说明:对于每个图像三元组,顶部的可视化显示了我们方法的结果(优化结果),左下角的图像是验证/训练集中最活跃的图像(跟我们方法的结果最接近的图像),右下角的图像显示了激活模式(激活结果,白色的激活效果更强)。可视化结果表明,ViTs与CNNs的相似之处在于,当我们从浅层特征到深层特征的过程中,ViTs表现出从纹理到零件到物体的特征递进。L5这些表示的是层数。
结论
为了剖析视觉转换器的内部工作原理,我们引入了一个基于优化的特征可视化框架。然后,我们确定了ViT的哪些组件最适合产生可解释的图像,发现前馈层的高维内部投影是合适的,而自注意力的键、查询和值特征则不适合。
将该框架应用于上述特征,我们观察到ViTs在除最后一层外的所有层中都保留了patch的空间信息,表明网络从头开始学习空间关系。我们进一步表明,最后一个注意力层中定位信息的突然消失是由类似于平均池化的学习到的token混合行为造成的。
通过比较CNNs和ViTs时,我们发现ViTs更好地利用了背景信息,并且在仅暴露于图像背景时,ViTs能够做出远优于CNNs的预测,尽管ViTs对高频信息的丢失并不像CNNs那样敏感。我们还得出结论,这两种架构有一个共同的属性,即较早的层学习纹理属性,而较深的层学习高级对象特征或抽象概念。最后,我们表明,经过语言模型监督训练的ViTs学习到更多的语义和概念特征,而不是像典型的分类器那样学习对象特定的视觉特征。
感悟
学到了很多之前不知道的,至少不是很玄学了,主要是:
- ViT对高频信息不是很敏感
- ViT可以利用背景信息
- ViT跟CNN相同,低层特征还是纹理,高层特征就是体现对象特征了
- ViT的低维特征不好解释
- ViT中除了Transformer的最后一层外其他都保留了位置信息。