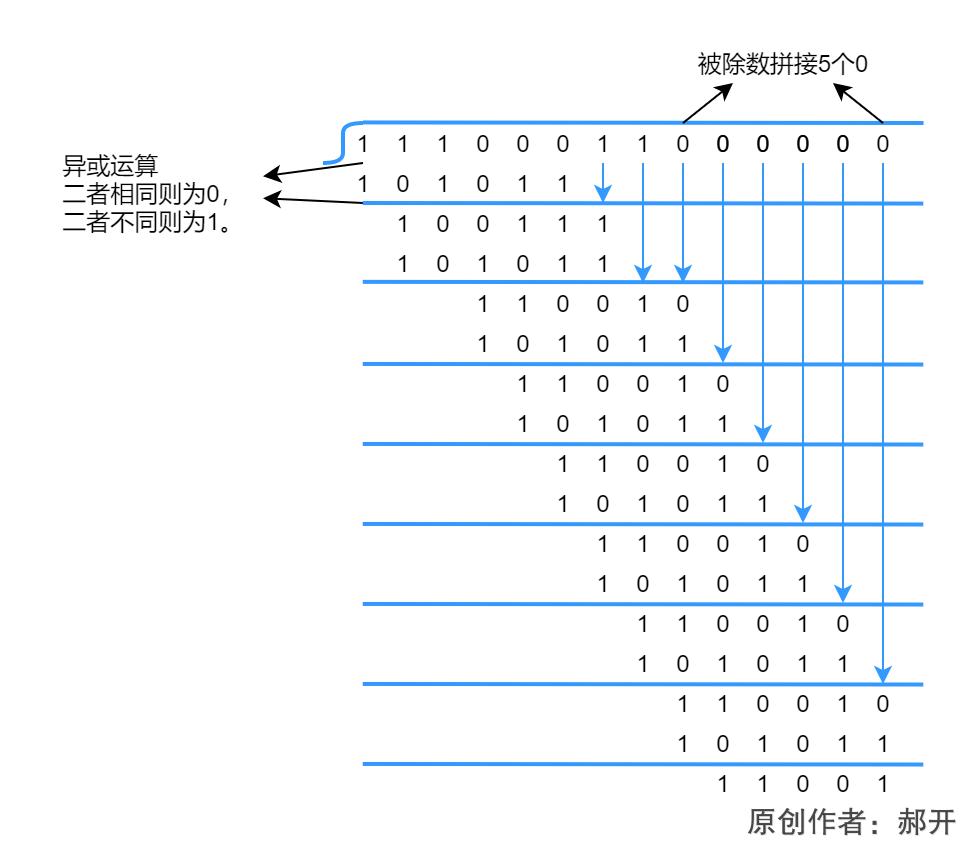
2020年爆火的Nerf(神经辐射场)横空出世,据说只要用手机拍照,然后喂给模型,就可以生成3D模型了,我试过了,确有此事!
那我们有想过,为什么可以从二维的图片里面获取物体三维的信息吗?
接下来,我们就追根溯源,先从数学和物理的角度来看下三维世界的物体如何通过照相机变成二维的图像信息。
稍微插播:大家支持的话可以关注公众号 AI知识物语(周更三维重建相关文章), B站 出门吃三碗饭,不定期更新视频讲解
接下来我们将依次介绍下面几个坐标
世界坐标,相机坐标,归一化坐标,像素坐标。

首先我们引入一个最简单的相机模型——针孔相机模型
P:真实世界中的一个点
O:相机的光心,处在相机平面上
P‘:真实世界的点通过光心在成像平面上形成的一个点
在左边的平面看作是相机内部的成像平面
光心O到成像平面O‘的距离叫f 焦距
P到光心O的距离w设为z
设P坐标 [X,Y,Z]^T
设P’坐标 [X‘,Y‘,Z‘]^T
z和f的距离可以见右图,通过相似三角形可以得出

我们知道成像平面最终呈现给我们是一张图片,也就是只有2维的信息,于是我们在 成像平面上引入 像素平面,并在其左上角顶点设立起点坐标系,设P’的像素坐标为 [u,v]^T
像素坐标系相对于成像平面,可看做在u、v轴分别缩放了α和β倍,同时原点平移了
[Cx,Cy]^T,像素坐标推导如下图:


为了更加美观,我们把像素坐标变为齐次形式,并写为以上形式
Z:世界空间点到光心距离
K:相机内参矩阵(可以问厂家or自己测;相机如果碰损会影响值)
P:世界空间点的坐标
现在我们已经成功实现了一个数学模型,输入空间的一个点,就输出其通过相机的像素点,是不是很神奇?如果输入的是很多个点,那么最终就会输出一幅色彩丰富的图片啦。
但是,现在我们还有一点要考虑。在上面我们输入的P是相机坐标下的点坐标,但因为相机的运动关系,P的相机坐标应该是其世界坐标P_world,简称P_w ,根据相机位姿变化的结果。
(也就是说如果需要使用P相机坐标,我们需要知道他的值,可以通过P_w推出)
相机的位姿由他的旋转矩阵R和平移向量t来确定,将其代入上述公式,代替P

现在,我们得到了式子,他的含义是:
输入 世界坐标下的点P_w, 先左乘 相机内参矩阵,再右乘 相机外参矩阵T,
值=空间点坐标距离光心距离 右乘 像素坐标
输出:(Z已知)可以得到其 像素坐标
这样,我们的空间点在相机的成像过程就顺利理顺了!
从另一个角度再看,
我们先把世界坐标点P_w转为P相机坐标系点,再除去其最后一维值,也就是Z(该点距离相
机成像平面的深度),这样相当于对最后一个维度归一化(最后一维经过上面操作后变为1),于是我们得到 相机坐标系的点P在 相机归一化平面上的投影点。

归一化坐标可以看作相机前面z=1处的平面有一个点,z=1的平面可以看作归一化平面,归一化坐标左乘内参就得到了像素坐标,因此,我们可以把像素坐标看作是对归一化平面上点量化测量的结果。
这里,如果我们对相机坐标P乘任意非0常数,其归一化坐标都是一样的,也即该点的深度在投影失去了信息。因此单目视觉(针孔成像)没法得到像素点的深度值。该任务需要双目模型来完成。
另外,本篇文章参考借鉴了高翔的视觉SLAM14讲,第5章节,想了解更多细节请自行搜索。
最后,觉的有帮助的话可以关注公众号 AI知识物语, B站 出门吃三碗饭,不定期更新视频讲解。
好了,我去复习明天下午的操作系统考试了,我真的会谢!
![[数据结构]:04-循环队列(数组)(C语言实现)](https://img-blog.csdnimg.cn/52129f2a56b64309beae7d0ff41131f9.png)