程序设计语言部分
- 一、高级语言与低级语言
- 1、低级语言(面向机器)
- 2、高级语言(面向对象)
- 二、编译程序与解释程序
- 1、区别
- 2、流程(加粗点为不可省略过程,顺序不可变)
- (1)词法分析
- (2)语法分析
- (3)语义分析
- (4)目标代码生成
- (5)中间代码生成
- (6)词法分析工具:正规式(做题)
- (7) 词法分析工具:有限自动机(做题)
- 三、程序设计语言
- 1、数据成分
- (1)划分数据类型的作用
- 2、控制成分
- 3、知识点
- 四、传值调用与传地址调用(这里要多做题)
- 1、函数定义
- 2、传值调用
- 3、传地址调用(传引用调用)
- 4、符号表(贯穿于编译过程)
- 5、知识点
- 五、上下文无关文法(做题)
- 六、语法树的中缀式、后缀式(逆波兰式)
注意:该笔记是根据zst_2001的学习路线记录的,所以和书本上面的有偏差
一、高级语言与低级语言
1、低级语言(面向机器)
- 机器语言:计算机只能识别由0、1组成的机器指令序列,所以最基本的计算机语言就是机器语言。
- 汇编语言:因为机器指令序列可读性差,所以出现了使用容易记忆的符号代替指令的汇编语言,比如ADD(加法),SUB(减法),MOV(赋值)…
2、高级语言(面向对象)
- C
- C++
- java
- js
- python
…
二、编译程序与解释程序
由于计算机只能识别1/0构成的指令,所以对于汇编语言、高级语言需要进行翻译,这一程序称为语言处理程序。翻译的基本方式为汇编、编译、解释。
汇编:针对汇编语言翻译成机器指令。
解释:解释器,一般是解释脚本语言(PHP、Python、js)。有两种方式:1、直接将源程序解释执行。2、将源程序解释成一种中间代码后执行。
编译:编译器,将源程序翻译成目标语言程序,在计算机上执行目标程序。
1、区别
解释器
翻译源程序时不生成独立的目标程序;
解释程序与源程序参与目标程序的执行;
编译器
翻译源程序时生成与源程序对等的独立保存的目标程序;
编译程序与源程序不参与目标程序的执行;
2、流程(加粗点为不可省略过程,顺序不可变)
解释器:词法分析、语法分析、语义分析
编译器:词法分析、语法分析、语义分析、中间代码生成、代码优化、生成目标代码
(1)词法分析
输入:源程序
输出:记号流
分析构成程序的字符及由字符按照字符规则构成的符号是否符合程序语言的规定
(2)语法分析
输入:记号流
输出:语法树(分析树)
语法分析可以找出所有的语法错误
分析代码的结构是否有问题,比如:int a= 3 其后不带分号就会报错
(3)语义分析
输入:语法树
语义分析只能找出静态语义错误,动态语义错误只能在运行时发现。
分析代码的类型
静态语义错误:比如 int a = “11”;
动态语义错误:无语法错误和静态语义错误,运行时的死循环、除数为0
(4)目标代码生成
目标代码生成阶段与具体的机器密切相关,寄存器的分配与使用也需考虑
(5)中间代码生成
常见的中间代码有:后缀式、三地址码、四元式、树(图)等
生成中间代码提高了编译程序的可移植性,且与具体的机器无关,可做与机器无关的优化处理;可将不同高级程序语言翻译成同一种中间代码,中间代码可以跨平台
(6)词法分析工具:正规式(做题)
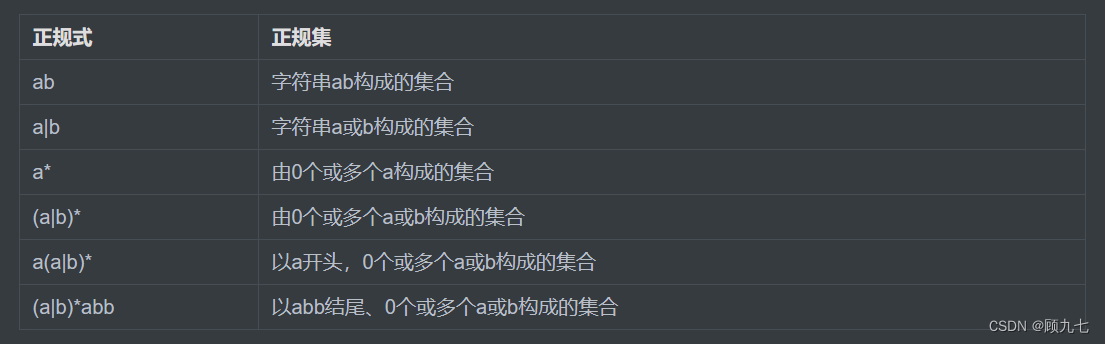
当选择都符合题意时,选择可表示的最大的集合
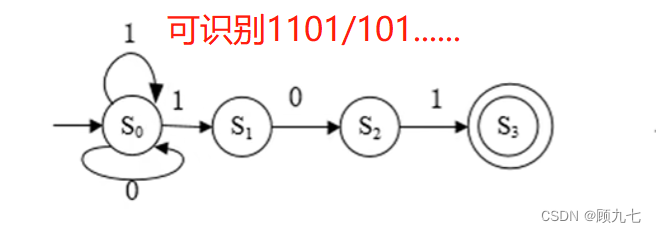
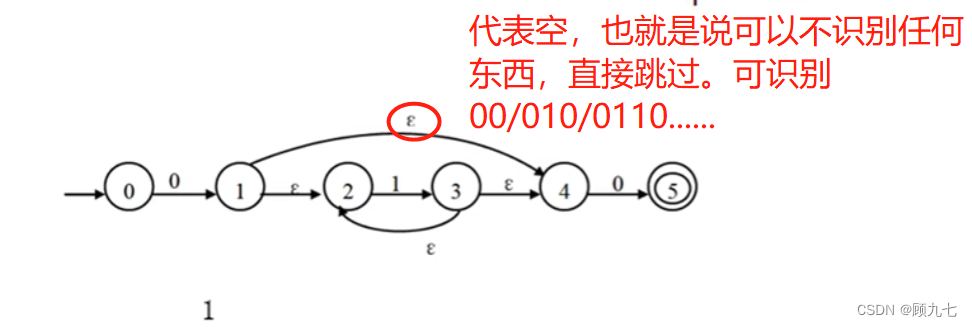
(7) 词法分析工具:有限自动机(做题)
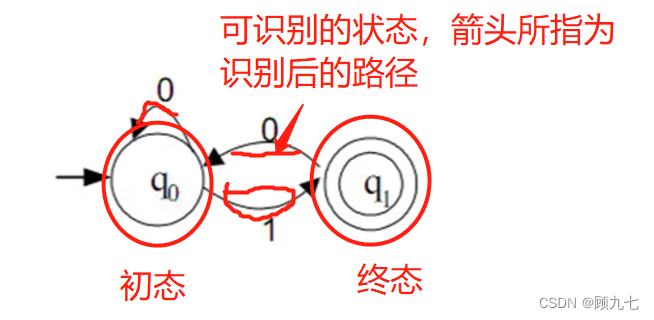
有限自动机可正确识别正规集,推导正规式。
分为确定的有限自动机DFA(每种状态的转移只有一个选择)和不确定的有限自动机NFA(一种状态的转移可以有多种)。
状态分为初态和终态,初态也可为终态,可以有多个终态。最终都要停留在终态
三、程序设计语言
程序设计语言的基本成分包含数据、运算、控制和传输等
1、数据成分
- 常量和变量
- 全局量和局部量
- 数据类型
(1)划分数据类型的作用
- 便于为数据合理分配存储单元
- 便于对参与表达式计算的数据对象进行检查
- 便于规定数据对象的取值范围与可执行的运算
2、控制成分
- 顺序
- 选择
- 循环
3、知识点
- 变量具有对应的存储单元,常量没有(这个地方疑惑),它是放在常量区的
- 常量不可被赋值
- 短路运算(假&?:不用确认右侧?的假与真,其结果一定是假;真||?:不用确定右侧的?的假与真,其结果一定是真)
- 左结合:从左向右算;右结合:从右向左算
四、传值调用与传地址调用(这里要多做题)
1、函数定义
返回值类型 函数名f(形参) {
函数体
}
调用时:f(实参)
2、传值调用
- 将实参的值传给形参,实参可以是常量、变量、表达式
- 不会实现实参与形参之间的双向的数据传递
3、传地址调用(传引用调用)
- 将实参的地址传给形参,实参不能是常量、表达式
- 会实现实参与形参之间双向的数据传递,改变了形参的值也就相当于改变了实参的值
4、符号表(贯穿于编译过程)
不断收集、记录和使用源程序中一些相关符号的类型和特征信息,并将其存入符号表;记录源程序中各字符的必要信息,以辅助语义的正确性检查和代码生成
5、知识点
- 声明语句存入符号表,执行语句是翻译成中间代码或目标代码
五、上下文无关文法(做题)
大多数程序设计语言的语法规则用上下文无关文法描述其语法。
包含开始符号和终止符号,每一部分称为产生式。一般的题目都是根据下面的产生式,可以推导出什么公式…

六、语法树的中缀式、后缀式(逆波兰式)
语法树根据中序遍历遍历出来的树为中缀式,根据后序遍历遍历出来的树为后缀式。
语法树其实就是二叉树,最顶部为根节点,左边为左子树、右边为右子树,既无左子树又无右子树的节点称为叶子结点。
中序遍历语法树的规则是:左中右
后序遍历语法树的规则是:左右中
(啧,不好表示,后面增加动画演示)
我们经常见的式子就是中缀式,题目一般是给你中缀式,求后缀式,或者给你语法树,求后缀式(或者反着)。
当提供了后缀式时,可借助**栈(先入后出)**来表现语法树或者求中缀式。将数字挨个放入栈中,一旦遇到运算符号,就将栈中的两位取出,分别放在运算符的右边和左边,然后将其看做一个整体,放入栈中。
当提供了中缀式,要求后缀式时,按照优先级大小遍历,当优先级相同时,从右向左遍历。




![[创业之路-56] :职场真相:越便宜的员工其实越贵](https://img-blog.csdnimg.cn/img_convert/3a2ca17bab2fc72f918cd170236d0d68.jpeg)