A novel image super-resolution algorithm based on multi-scale dense recursive fusion network
(基于多尺度密集递归融合网络的图像超分辨率算法)
随着卷积神经网络(CNN)技术的成熟度,超限分辨的图像重建(SR)方法基于CNN正在蓬勃发展,取得了许多显著的成果。毫无疑问,SR已经成为图像重建技术的主流方向。然而,大多数现有的SP方法提高重建的性能通过增加网络的深度,也增加参数的数量,数量的网络计算和困难的训练网络。为了解决随机共振中的性能复杂度问题,提出了一种多尺度稠密递归融合网络(MSDRFN)。该网络由三部分组成:初始特征提取模块、多尺度稠密融合分组模块和递归重建模块。具体地,首先通过浅层特征提取模块提取粗特征,然后将粗特征输入到多尺度密集融合块(MSDFB)组。每个MSDFB充分利用不同大小卷积核中的图像特征获得不同的层次特征,并将这些输出特征输入到信道关注机制中学习其对应的权重。所有MSDFB输出将通过递归重建模块恢复为高分辨率图像。此外,网络通过残差学习来补充信息损失,这体现在一个长跳连接和多个短跳连接上。
介绍
图像超分辨率重建(SR)可以提高计算机视觉应用中的图像和视频质量。SR将观察到的低分辨率图像或视频转换为相应的高分辨率图像或视频。这样的图像处理技术对于目标检测、医学成像、卫星遥感和其他应用是重要的。然而,图像SR是多解问题,因为在低分辨率(LR)图像和其对应的高分辨率(HR)图像之间存在多个映射。当上采样因子较大时,难以获取用于恢复SR的高频信息。在这种情况下,SR必须通过图像的一些先验知识来发现LR和HR图像之间的内在相互作用。可以通过基于CNN的深度学习来学习描述LR和HR图像之间的内在交互的非线性映射。
尽管现有的基于CNN的SR模型已经取得了相对较好的结果,但是它们的训练受到大量参数和计算的阻碍。大部分研究都集中在结构和算法较为复杂的深度网络上,没有考虑不同层次的特征,浪费了大量的时间和存储空间。
为了有效解决复杂度问题,本文提出了一种多尺度稠密递归融合网络(MSDRFN),可以实现图像的超分辨率重建。与现有的基于神经网络的随机共振方法相比,该模型在不消耗过多计算资源和时间的前提下提高了图像重建性能。该方法的特点是充分利用了不同尺度下的卷积核,并在网络中嵌入多尺度稠密融合块(MSDFB)以提取更多的信息。此外,对于大量具有冗余信息的要素,1×1卷积核进行降维,去除冗余特征,获取有用信息。最后,通过递归重建模块将所有MSDFB的输出恢复为高分辨率图像。利用残差学习来补充信息损失,并将细节特征和轮廓特征相结合,形成丰富的特征。总之,我们建立了一个具有三尺度卷积特征提取分支和多个残差学习结构的MSDRFN。该方法使用减少数量的参数以令人满意的性能实现单个图像的超分辨率重建。
贡献
1)提出了一种新的平衡两阶段结构的MSDFB,该结构利用残差学习、多尺度深度递归融合和信道注意机制在网络中的信息流动中发挥作用。
2)学习图像的层次特征信息,利用递归思想将每个层次特征连接到图像重构模块,适当平衡了图像重构性能、计算资源和时间。
3)在MSDFB群的基础上,提出了一种新的MSDRFN网络,该网络不同于大多数现有方法,直接从LR图像中提取特征,并利用多个MSDFB提取最有用的信息。
4)多个亚像素卷积递归重建网络(SpCRNets)用于恢复分层特征。增加了HR图像特征的数量,达到了更好的重建效果。我们提出的MSDRFN上级其他SR方法。
相关工作
Image super-resolution based on CNN
大多数现有SR方法分为三类:插值法、重建法]和学习法。基于插值的算法是一种相对简单、复杂度较低的图像重建方法,但其有效性有限,且图像中的高频细节不易修复,导致重建过程中计算复杂、图像模糊、实时性差。因此,基于插值的方法不适合具有大放大因子的图像重建(例如×3和×4)。
基于卷积神经网络(CNNs)的深度学习技术已经克服了这个问题。在深度学习中,使用CNN的主动学习优于其他方法。2014年,Dong等人引入了第一个基于CNN的SR方法,称为SRCNN,该方法使用3层CNN直接学习从LR到HR图像的端到端映射。尽管SRCNN优于以往的方法,但SRCNN中的插值会引入噪声,影响网络性能。随着网络层次的加深,网络速度变慢,网络训练难度加大。Dong等人的工作引发了对具有深度学习的SR方法的极大兴趣。基于SRCNN的两个相对浅的网络是快速超分辨率CNN(FSRCNN)和高效亚像素CNN(ESPCN)。两种网络在速度和准确性上都优于SRCNN。FSRCNN通过采用更少参数的更快模型和放大图像的去卷积层来改进SRCNN。因此,网络可以输入非插值的小图像。ESPCN提出了一种亚像素卷积上采样方法,通过通道数扩展和像素点重排实现图像放大。
这些浅网络不能满足重建性能的要求。此后,连续开发的基于CNN的模型克服了上述网络的局限性,其中大多数模型通过深化网络来改善性能。2016年,研究学者分别提出了两种非常深的神经网络,表示为VDSR和DRCN。两种网络均采用全局残差学习(GRL),并通过深度神经网络获得了成功的SR。人们可能认为深度CNN是图像SR的必要条件,GRL可以减轻训练深度,但不能消除多参数问题。为了减少参数的数量,Tai等人提出了一种深度递归残差网络(DRRN),它共享在深度网络中扩散的参数。他们还加入了局部残差学习,减轻了图像信息通过深度网络时的损失。为了获得大倍数(大于8倍)的上采样因子,Lai等人设计了一个金字塔结构的网络模型,记为LapSRN。LapSRN结构的每一级仅产生原始图像的两倍放大的结果。EDSR是赢得NTIRE2017锦标赛挑战的超分辨率方案。如文中所述,对EDSR模型进行了改进,主要是去除了一些冗余模块,提高了模型的通用性。
但这些方法大多没有充分利用LR图像的特征信息,而是通过加深网络来提高性能。随着网络层数的增加,图像特征信息会在传输过程中逐渐消失。现阶段,如何充分利用网络中已有的特征,已成为高质量图像重建的关键问题。这个问题已经被两个具有多尺度卷积模块的网络解决,即级联交叉网络(CMSC)和多尺度残差网络(MSRN)。CMSC以由粗到细的方式捕获图像中的高频细节信息,而MSRN通过重构多尺度残差块来恢复高质量图像。
一些研究者提出了深度反投影网络(Deep Back-Projection Networks,DBPN),构造了相互依赖的上下采样模块。每个采样模块代表不同的图像退化和高分辨率分量。Qin等人提出了一种深度自适应双网(Deep Adaptive Dual-network,DADN)双向SR网络,其中网络的一个分支被训练用于聚焦简单图像区域,另一个分支被训练用于处理硬图像区域。2020年,Liu等人在中提出了两种轻量级、有效的图像超分辨率网络,分别称为基于注意力的多尺度残差网络(AMSRN)和改进的双尺度残差网络(IDSRN)。这两种网络主要是基于注意机制的多尺度特征捕获方法。但它们没有考虑层次特征信息。不久之后,Zhang等人充分利用了残差分支的层次特征,将多个残差块合并在一起,通过加入跳跃连接来促进每个残差分支特征的前向传播。
上述许多方法都存在一些问题。由于HR和LR图像之间潜在的较大分布差异,影响了信息利用的有效性。为了解决这一问题,Lu等人提出了基于参考的图像超分辨率(MASA)网络的匹配加速和空间自适应,其中设计了两个新模块来解决这些问题。匹配提取模块采用由粗到细的相应匹配方案,大大降低了计算成本。空间自适应模块学习LR和HR图像的分布差异,并以空间自适应的方式将特征分布重新映射为LR特征分布。该方案使得网络在处理不同参考图像时具有鲁棒性。
最近,Li等人提出了一种区域感知的对抗学习策略,以引导模型专注于纹理区域细节的自适应生成。Lu等人提出了一种新的高效超分辨率变换器(ESRT),用于快速和准确的图像超分辨率。ESRT是一种混合变压器,其中基于CNN的SR网络被设计在前端以提取深层特征。面对多域图像超分辨率,Rao等人提出了一种深度超分辨率残差StarGAN,这是一种新颖的、可扩展的方法,仅使用单个模型就可以对多个LR域的LR图像进行分辨率。Ahn等人[64]介绍了一种神经结构搜索(NAS)方法,以实现结构构建过程的自动化。他们将NAS扩展到了超分辨率领域,发现了一个轻量级的、高密度连接的网络,称为DeCoNASNet,并定义了一个基于复杂性的惩罚来解决图像的超分辨率问题。Villar-corrales等人认为,一些算法可能会在上采样步骤中放大噪声,并且通常无法从低分辨率图像的噪声版本重建高分辨率图像。因此,他们提出了一种联合去噪和超分辨率的方法。Tran等人[66]提出了一种基于学习的方法,应用于3D核线图像(EPI)以重建高分辨率。该方法通过两阶段超分辨率框架,有效地解决了各种超分辨率问题,提高了高分辨率EPI体的质量。Sun等人提出了加权多尺度残差网络,以更好地平衡SR性能和计算效率。Liu等人提出了一种基于多尺度特征融合的交叉卷积边缘检测方法,用于定位和表示超分辨率图像的边缘特征。因此,他们提出了一种联合去噪和超分辨率的方法。Tran等人[66]提出了一种基于学习的方法,应用于3D核线图像(EPI)以重建高分辨率。该方法通过两阶段超分辨率框架,有效地解决了各种超分辨率问题,提高了高分辨率EPI体的质量。Sun等人提出了加权多尺度残差网络,以更好地平衡SR性能和计算效率。Liu等人提出了一种基于多尺度特征融合的交叉卷积边缘检测方法,用于定位和表示超分辨率图像的边缘特征。
Residual learning
略
Feature extraction block
为了避免训练过程中梯度的消失或爆炸,He等人提出了一种带残差块的学习框架(图2(a)),保留了大量重要的输入信息。初始块(图2(b))的主要作用是使用不同大小的卷积核从图像中提取更丰富的特征。密集块(图2©)用于单一大小的卷积核。通过致密块后,网络深度增加,增加量为致密块的厚度乘以致密块的数量。Zhang和Tian 提出了一种由残差块和稠密块组成的残差稠密块(图2(d)),它充分提取了局部和全局特征。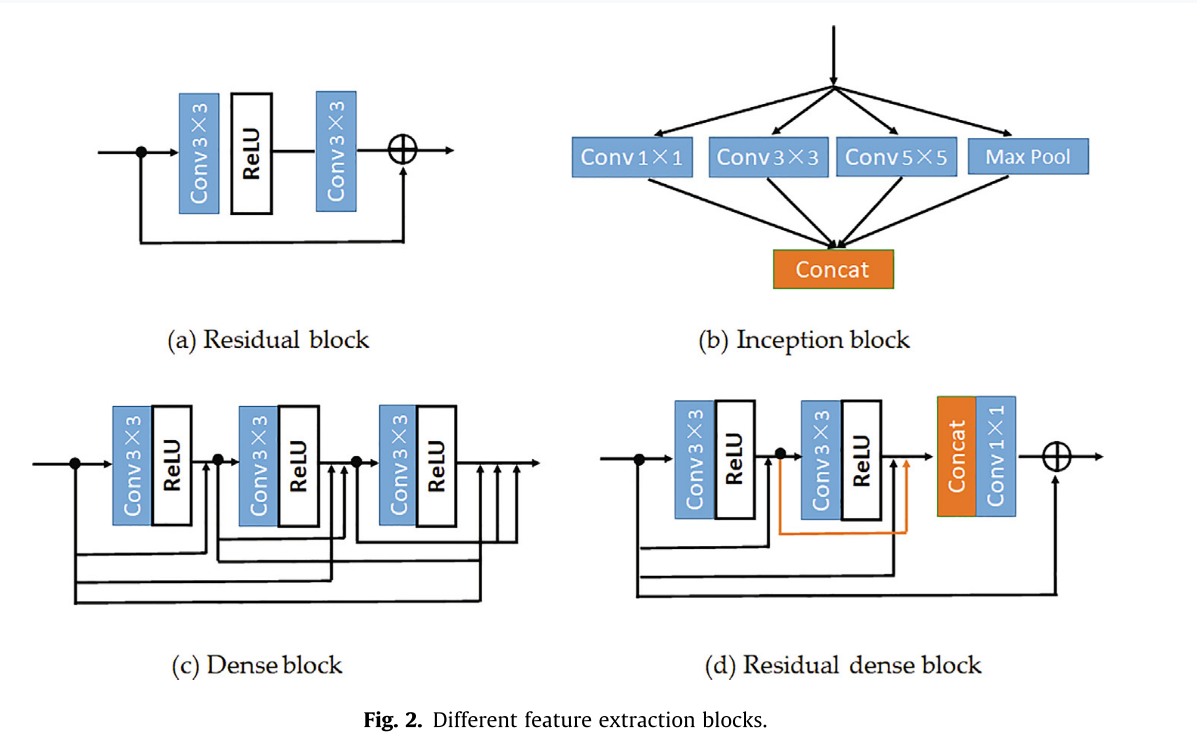
Channel attention
当面对图像时,人眼可以快速扫描全局图像并找到需要关注的目标,并聚焦于关键目标区域,而选择性地忽略其他非关键目标区域。生活中也存在这种现象。人的眼睛总是首先关注需要注意的物体,其他无关的物体会被忽略。鉴于人类视觉的这种能力,研究人员希望计算机也能拥有这种形式的注意力,能够从海量数据中选择对眼前目标更有价值的信息,并持续关注。
2018年,Hu等人引入了挤压激励网络,通过学习各通道对图像的贡献度自适应地调整通道权重。同年,Zhang等人将残差网络与信道注意机制相结合,提出了残差信道注意网络(residual channel attention,RCAN)。为了消除无用信息,网络计算不同信道分量之间的相关性,将相关性作为权值分配给初始信道,并使用残差学习来补充网络的信息损失。实验表明,信道注意机制可以提高网络图像处理的性能。
方法
Network model architecture
现有的基于神经网络的模型虽然在一定程度上满足了性能要求,但模型中参数和计算量大,浪费了较多的时间和存储空间,极大地阻碍了模型的训练。目前的研究主要集中在结构复杂的深层网络上,没有考虑不同层次的特征。为了有效解决超分辨率图像重建的复杂性问题,提出了一种多尺度稠密递归融合网络(MSDRFN),该网络能够在不消耗过多计算资源和时间的前提下提高图像重建的性能。
该方法的独特之处在于提出了一种新的平衡两阶段MSDFB算法,该算法利用残差学习、多尺度深度递归融合和信道注意机制在网络信息流中发挥作用。通过学习图像的层次特征信息,利用递归连接将每个层次特征链接到图像重建模块,合理平衡图像重建的性能和计算资源与时间。图3示出了所提出的网络的架构,该网络输入LR图像并输出HR图像。该网络由三个主要图像处理模块组成:初始特征提取模块、多尺度稠密融合分组模块和递归重建模块。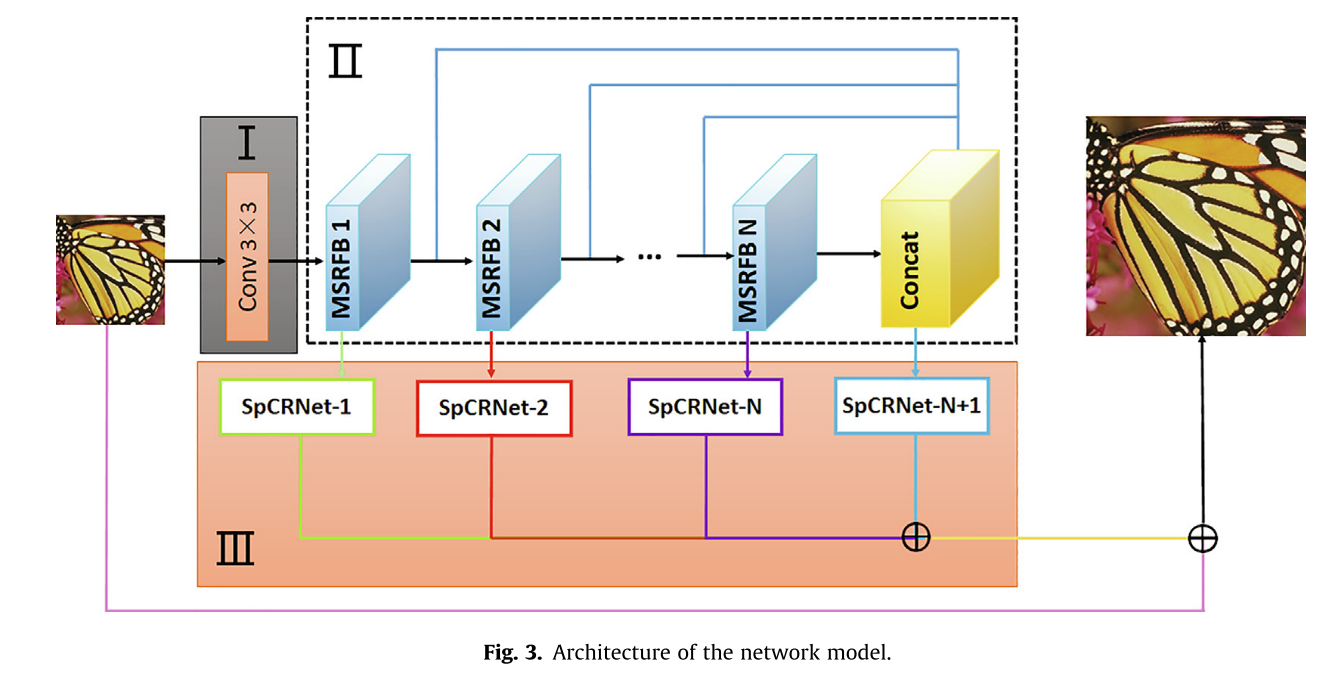
Initial feature extraction module:从原始输入LR,使用3×3卷积核捕获初始特征映射P1:
Multi-scale dense fusion group module:使用多个多尺度密集融合块从初始特征中提取丰富的特征。因此,我们有
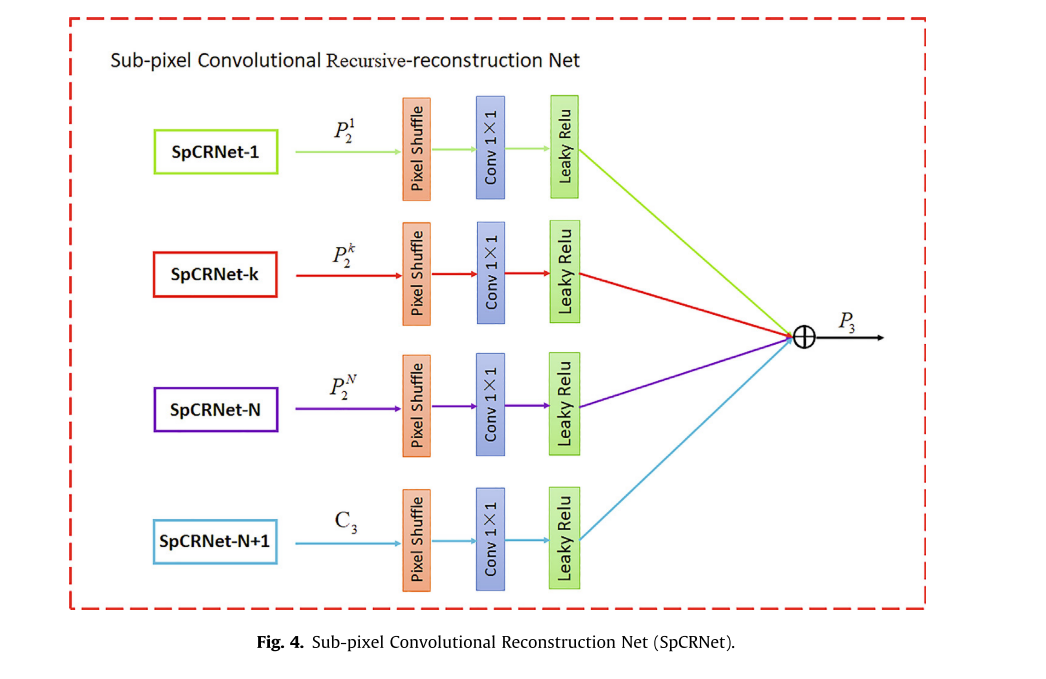
Recursive reconstruction module:为了充分利用深度学习提高图像分辨率,我们提出了一种如图4所示的重建模块,称为亚像素卷积递归重建网络(SpCRNet),它采用1×1卷积层和亚像素卷积层,可以学习不同层次的信息特征。将多尺度融合块中学习到的特征图
P
1
P^1
P12,
P
k
P^k
Pk2,
P
N
P^N
PN2,C1分别输入SpCRNet的相应子模块,得到更好的图像。然后,融合重构模块得到的所有层次特征。最后,通过双三次插值将初始图像与在此阶段获得的高分辨率图像相加,并将结果作为网络的最终输出。该阶段简单地实现为:
Multi-scale dense fusion block
本小节描述具有三个不同尺度卷积核的MSDFB的完整分支(图5)。MSDFB采用局部残差学习、多尺度密集融合和信道注意机制来获取特征信息。MSDFB分为两部分:多尺度特征提取、挤压和激励机制。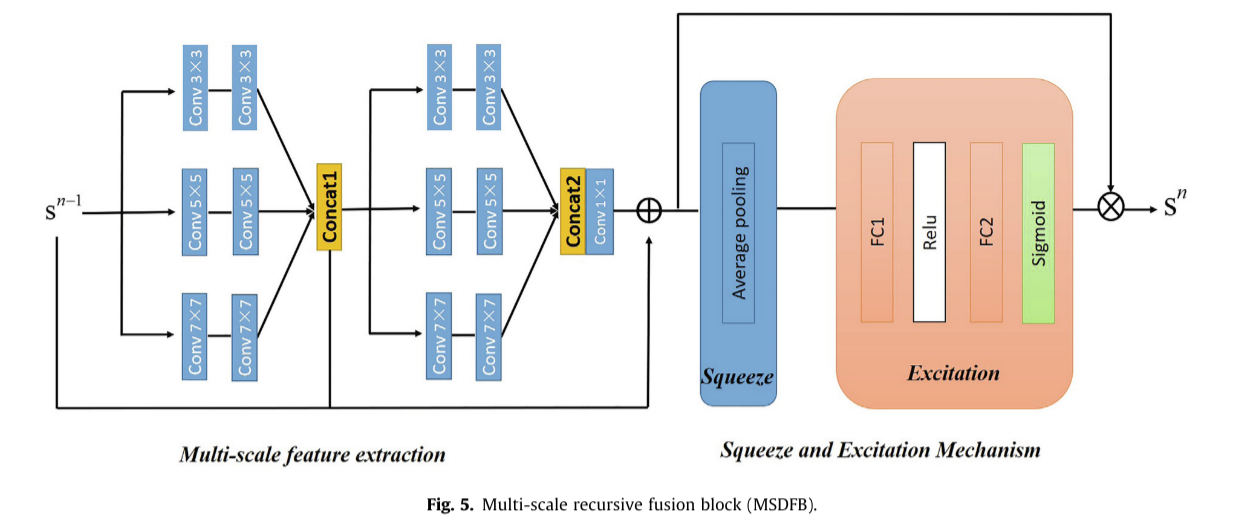
Multi-scale feature extraction:如图5所示,该部分由两个结构相同的多尺度卷积相位组成。在每个阶段中,不同尺度的三个卷积核(7×7、5×5、3×3)并行排列进行特征提取。在每个并行路径中,第二层卷积核之后是LReLU。总体上,利用跳连接将初始特征与这一阶段提取的特征进行融合,获得多尺度特征信息。MSDFB输入和输出表示为Sn-1和Sn组成。第一阶段的实施情况如下: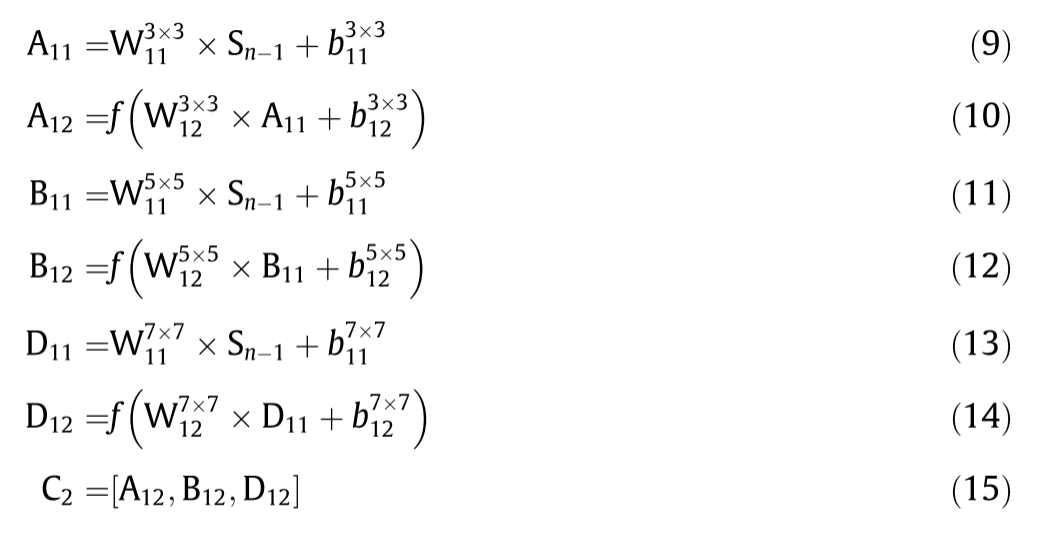
同样,我们可以得到:
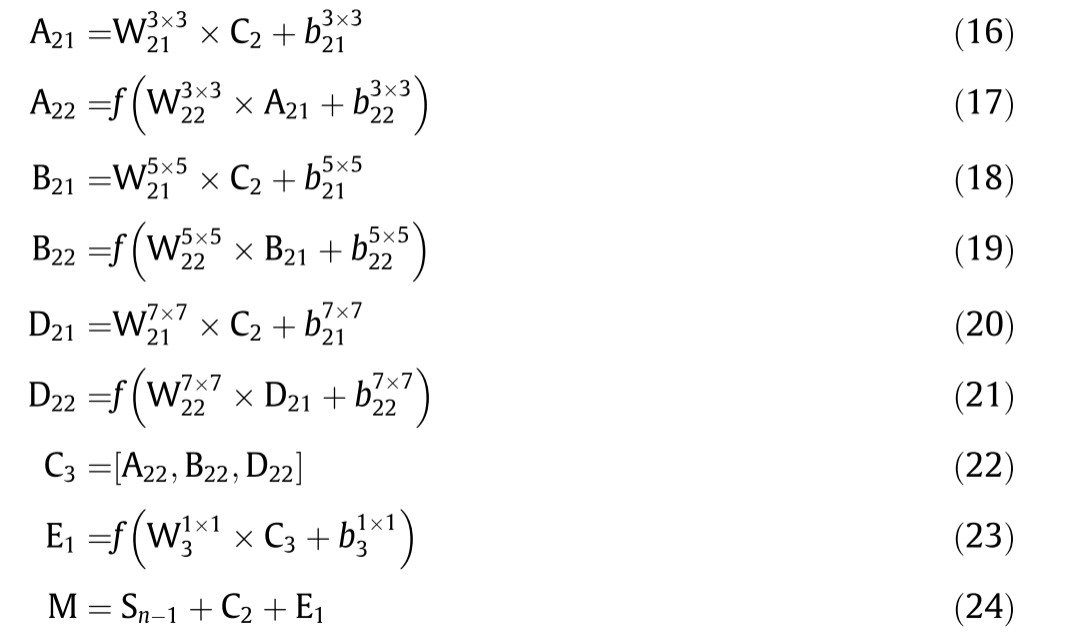
其中A、B和D分别表示3的三个分支的中间结果7×7、5×5和3×3卷积运算。C表示与A连接的特征;B和D; W和b分别表示神经元的权重和偏置。E1表示通过1×1卷积运算。这些符号的下标和上标分别表示卷积核的层位置和大小。M表示多尺度特征提取的输出。f(·)LReLU函数。LReLU负域的斜率设定为0.05。方程式(15)以及(22)表示级联操作。
Squeeze and excitation mechanism:该部分用于根据损失学习特征图通道的权值,使得有效特征图的权值显著,无效特征图的权值较小。整个MSDFB表示多尺度密集融合特征,不仅提供丰富的上下文信息,而且学习通道的权重。
第二部分具体实现如下:
Training and loss functions
当训练网络时,通常的优化目标是均方误差(MSE),其预测所获得的HR图像与真实的HR图像之间的差异。实际上,MSE返回的是许多可能场景的平均值,因此输出图像在视觉上是模糊的和不可靠的。平均绝对误差(MAE)较好地反映了预测误差的实际情况。因此,我们采用MAE作为优化目标函数。此外,为了更好地收敛网络,我们使用L1正则化通过在MAE损失之后添加惩罚来平衡拟合训练的目标。θ、λ分别表示所提出的网络的参数和正则化系数。然后,优化目标函数被定义为: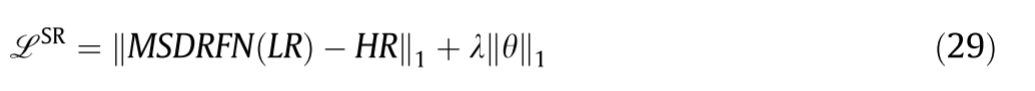
我们的主要目标是解决以下优化问题: