文章目录
- 1.TCP底层三次握手详细流程
- 2.TCP洪水攻击介绍和ss命令浅析
- 3.Linux服务器TCP洪水攻击入侵案例
- 4.TCP洪水攻击结果分析和解决方案
- 5.TCP底层四次挥手详细流程
1.TCP底层三次握手详细流程

- TCP的可靠性传输机制:TCP三次我手的流程
- 一次握手:客户端发送一个SYN数据包到服务端,用来请求建立连接,状态变为SYN_SEND。
- 报文首部中的同位置SYN=1,同时生成随机序列号seq=x。
- 二次握手:服务端收到客户端的SYN数据包,并回复一个SYN+ACK数据包,用来确认连接,状态变为SYN_RECEIVED。
- 确认报文中应该ACK=1,SYN=1,确认号是ack=x+1,同时随机初始化一个序列号seq=y。
- 三次握手:客户端收到服务端的SYN+ACK数据包,并且回复一个ACK数据包,用来确认连接建立完成,状态变为ESTABLISHED。
- 确认报文的ACK =1,ack=y+1,seq=x+1。
- 出于安全的考虑,第一次握手不能携带数据,第三次我手是可以携带数据的。
- 一次握手:客户端发送一个SYN数据包到服务端,用来请求建立连接,状态变为SYN_SEND。

-
TCP三次握手的状态变化
- 客户端:CLOSE->SYN_SEND->ESTABLISHED
- 服务端:CLOSE->LISTEN->SYN_RECEIVED->ESTABLISHED
-
TCP连接的数据结构
-
TCP是有状态的协议,有多个连接存在时通过TCP的控制块 TCB (Transmission Control Block)来记录每一个连接的状态
- 通常一个TCB至少需要280个字节
-
通过 四元组区分不同的TCP数据报属于哪一个连接 源IP地址、源端口、目的ip、目的端口
-
连接对象信息存在一个容器中,每次接收到报文后从容器中取出对应的控制块来处理
-
struct tcb // tcp 控制块
{
_u32 remote_ip; // 远端ip
_u32 local_ip; // 本地ip
_u16 remote_port; // 远端端口号
_u16 local_port; // 本地端口号
int status; // 连接状态
...
}
思考:为什么要三次握手呢,不是二次或者四次?
两次握手案例一: 两端同步确认序列号
第一步:客户端发送一个起始序列号seq = x的 报文段给服务器。
第二步:服务器端返回向客户端发送确认号 ack = x+1,表示对客户端的起始序列号x 表示确认,并告诉客户端,他的起始序列号是 seq = y,但不一定成功发给客户端,导致服务端序列号可能丢失
两次握手,只有服务器对客户端的起始序列号做了确认,但客户端却没有对服务器的起始序列号做确认,不能保证可靠性
两次握手案例二:防止失效的连接请求报文段被服务端接收
若客户端向服务端发送的连接请求阻塞,客户端等待应答超时,就会再次发送连接请求,此时上一个连接请求就是"失效的"
如果建立连接只需两次握手,此时如果网络拥塞,客户端发送的连接请求迟迟到不了服务端,客户端便超时重发请求,如果服务端正确接收并确认应答,双方便开始通信,通信结束后释放连接。
这时如果那个阻塞的连接请求抵达了服务端,由于只有两次握手,服务端收到请求就会进入ESTABLISHED状态,等待发送数据或主动发送数据,但客户端早已进入CLOSED状态,服务端将会一直等待下去,浪费服务端连接资源
如果 TCP 是三次握手,那么客户端在接收到服务器端 seq+1 的消息之后,可以判断当前的连接是否为历史连接
如果判断为历史连接的话就会发送终止报文(RST)给服务器端终止连接
如果判断当前连接不是历史连接的话就会发送指令给服务器端来建立连接。
TCP 连接可以四次握手,甚至是五次握手能实现 TCP 连接的稳定性,但三次握手是最节省资源的连接方式
2.TCP洪水攻击介绍和ss命令浅析
-
ss命令-
Socket Statistics 是Linux中的一条网络工具命令,用于显示当前系统的各种网络连接状态,包括TCP、UDP以及Unix套接字等
-
显示的内容和 netstat 类似, 但ss能够显示更多更详细的有关 TCP 和连接状态的信息
-
使用格式:ss [OPTIONS] ,常用选项如下
-
| 参数 | 说明 |
|---|---|
| -s | 显示概要信息 |
| -a | 显示所有网络连接状态 |
| -l | 显示正在监听的网络连接 |
| -n | 显示IP地址和端口号 |
| -t | 显示TCP状态 |
| -u | 显示UDP状态 |
-
洪水攻击SYN Flood
-
是一种网络攻击,它使用伪造的TCP连接请求来淹没服务器的资源,从而使服务器无法响应正常的用户请求
-
这种攻击通过不断地发送同步(SYN)连接请求到服务器,而服务器会尝试建立连接,
-
当服务器回复 SYN+ACK 报文后,攻击者不会发送确认(ACK)
-
那SYN队列里的连接则不会出对队,逐步就会占满服务端的 SYN半连接队列
-
服务器会一直等待,耗尽服务器的资源,最终就是服务器不能为正常⽤户提供服务
-
攻击的背景来源
- TCP 进入三次握手前,服务端会从内部创建了两个队列
- 半连接队列(SYN 队列)
- 全连接队列(ACCEPT 队列)
- TCP 进入三次握手前,服务端会从内部创建了两个队列
-
半连接队列(SYN 队列)
-
存放的是三次握手未完成的连接,客户端发送 SYN 到服务端,服务端收到回复 ACK 和 SYN
-
状态由 LISTEN 变为 SYN_RCVD,此时这个连接就被放进 SYN 半连接队列
-
半连接队列的个数一般是有限的,在SYN攻击时服务器会打开大量的半连接,分配TCB耗尽服务器的资源,使得正常的连接请求无法得到响应
- 服务器会给每个待完成的半连接设一个定时器,如果超过时间还没有收到客户端的ACK消息
- 则重新发送一次SYN-ACK消息给客户端,直到重试超过一定次数时才会放弃
- 这个操作服务器需要分配内核资源维护半连接状态
-
-
-
系统最大半队列大小 (半连接队列的最大长度不一定由 tcp_max_syn_backlog 值决定的,Linux 内核版本实现不一样)
sysctl -a|grep max_syn

cat /proc/sys/net/ipv4/tcp_max_syn_backlog

- 查看系统当前半队列大小
方式一:
ss -s
结果的 synrecv 0 就是
方式二:
netstat -natp | grep SYN_RECV | wc -l

- 查看 SYN队列是否有溢出
间隔执行下面命令,如果有持续大量递增则是溢出
netstat -s|grep LISTEN
-
全连接队列(ACCEPT 队列)
-
存放的是完成三次握手的连接,客户端回复 ACK, 并且服务端接收后,三次握手就完成了
-
连接会等待被的应用取走,在被取走之前,它被放进 ACCEPT全连接队列
-
系统最大全连接队列大小
-
cat /proc/sys/net/core/somaxconn
长度由 net.core.somaxconn 和 应用程序使用 listen 函数时传入的参数,二者取最小值,默认为 128,表示最多有 129 的 ESTABLISHED 的连接等待accept

- 查看系统当前全连接队列大小
ss -lnt 如果是指定端口 可以用 ss -lnt |grep 80
# -l 显示正在Listener的socket
# -n 不解析服务名称
# -t 只显示tcp
常规可以通过port端口看是哪类应用, 80端口这一行
state 在LISTEN 状态下
Send-Q表示listen端口上的全连接队列最大为128
Recv-Q为全连接队列当前使用了多少

- 查看 Accept 队列 是否有溢出
间隔执行下面命令,如果有持续大量递增则是溢出
netstat -s | grep TCPBacklogDrop
- 全连接队列满后发生什么
cat /proc/sys/net/ipv4/tcp_abort_on_overflow
系统会根据 net.ipv4.tcp_abort_on_overflow 参数决定返回,有两个值分别是 0 和 1(常规推荐是0)
- 0 如果全连接队列满了,那么 server 扔掉 client 发过来的 ack ;
- 1 如果全连接队列满了,server 发送一个
reset包给 client,表示废掉这个握手过程和这个连接- 客户端连接不上服务器,判断是否是服务端 TCP 全连接队列满的原因,可以把 tcp_abort_on_overflow 设为 1
- client异常中会报
connection reset by peer,大概率是由于服务端 TCP 全连接队列溢出导致的问题
-
TCP洪水攻击 基础缓解方案:TCP SYN Cookies (延缓TCB分配)
- 使用连接信息(源地址、源端口、目的地址、目的端口等)和一个随机数,计算出一个哈希值(SHA1)
- SYN-Cookie避免内存空间被耗尽,但是加密会消耗CPU
- 攻击者发送大量的ACK包过来,被攻击机器将会花费大量的CPU时间在计算Cookie上,造成正常的逻辑无法被执行
- 哈希值 被用作序列号 应答 SYN+ACK 包,客户端发送完三次握手的最后一次 ACK ,
- 服务器就会重新计算这个哈希值,确认是之前的 SYN+ACK 的返回包,则进入 TCP 的连接状态。
- 当开启了 syncookies 功能就可以在不使用 SYN 半连接队列的情况下成功建立连接,不需要维护半连接数的限制
- 如果是DDOS则难解决,需要花钱购买流量设备
- 使用连接信息(源地址、源端口、目的地址、目的端口等)和一个随机数,计算出一个哈希值(SHA1)
# 开启syncookies 阿里云ECS默认开启
# vim /etc/sysctl.conf
net.ipv4.tcp_syncookies = 1
0 值,表示关闭该功能;
1 值,表示仅当 SYN 半连接队列放不下时,再启用它;
2 值,表示无条件开启功能
3.Linux服务器TCP洪水攻击入侵案例
(1)TCP洪水攻击环境准备
- 准备hping3工具:hping3是一款开源的网络扫描和测试工具,可用于模拟tcp洪水攻击
- hping3 命令安装
# 依赖库
yum -y install libpcap
yum -y install libpcap-devel
yum -y install tcl-devel
#安装
yum -y install hping3
- 参数说明
| 参数 | 说明 |
|---|---|
| -S | 表示发送SYN数据包 |
| -U | 发送UDP包 |
| -A | 发送ACK包 |
| -p | 表示攻击的端口 |
| -i u100 | 表示每隔100微秒发送一个网络帧 |
| –flood | 和洪水一样不间断攻击 |
| –rand-source | 随机构造发送方的IP地址 |
- 使用hping3模拟tcp洪水攻击:通过hping3指令,向攻击目标发送大量tcp数据包,从而模拟tcp洪水攻击。
(2)实验环境机器准备
-
机器A 部署Nginx 作为常规服务(192.168.159.110)
- 阿里云服务需要关闭 syn_cookie ,即
net.ipv4.tcp_syncookies = 0
- 阿里云服务需要关闭 syn_cookie ,即
vim /etc/sysctl.conf
修改完之后,需要执行 sysctl -p 配置才能生效。
- docker部署nginx. (自行安装docker)
docker run --name nginx -p 80:80 -d nginx:1.23.3

- 机器B安装hping3 ,模拟 SYN 攻击(192.168.159.170)
hping3 -S -p 80 --flood 192.168.159.110
#-S是发送SYN数据包,-p是目标端口,192.168.159.110是目标机器ip

(3)服务器出现的现象
- 攻击前 访问192.168.159.110 机器的Nginx可以成功。
- 攻击时 机器192.168.159.110 服务访问超时失败(使用谷歌浏览器开启隐身模式,或者 curl -v 地址)
- 查看内存占用率不高、CPU平均负载和使用率等比较低,CPU耗在
si 软中断消耗时间比例升高

(4)流程浅析
- 网卡收到数据包后,通过硬件中断的方式,通知内核有新的数据,内核调用中断处理程序,把网卡的数据读取到内存中。
- 更新一下硬件寄存器的状态,在发送一个软中断信号,通知从内存中找到网络数据。
- 按照网络协议栈对数据进行逐层解析和处理,然后把数据交给应用程序处理。
- 前部分处理硬件请求,属于硬中断,特点是快速执行。
- 后部分处理内核触发,属于软中断,特点是延迟执行。
-
CPU主要用在软中断上,从进程列表上看到CPU 使用率最高的也是软中断进程 ksoftirqd
- ksoftirqd是运行在Linux的进程,专门处理系统的软中断的,格式是 “ksoftirqd/CPU 编号
- 在多核服务器上每核都有一个ksoftirqd进程,经常看到ksoftirqd/0表示这是CPU0的软中断处理程序
-
所以软中断过多比较大可能导致问题,通过文件系统 /proc/softirqs 看是哪类下软中断导致
- /proc/softirqs 提供了软中断的运行情况
- /proc/interrupts 提供了硬中断的运行情况
-
命令
watch -d cat /proc/softirqs
Every 2.0s: cat /proc/softirqs Sat Jan 7 12:15:45 2023
CPU0 CPU1 CPU2 CPU3
HI: 0 0 0 1
TIMER: 346771437 154363606 304924440 150269528
NET_TX: 148 7395 91 53
NET_RX: 203887543 25629878 37152669 27395828
BLOCK: 11007513 0 0 0
BLOCK_IOPOLL: 0 0 0 0
TASKLET: 9798 38 15 7
SCHED: 165941548 77615785 144222611 74794157
HRTIMER: 0 0 0 0
RCU: 184530769 93465836 167240016 91974099
说明
HI 高优先级软中断
TIMER表示定时器软中断,用于定时触发某些操作
NET_TX表示网络发送软中断,用于处理网络发送的数据包
NET_RX表示网络接收软中断,用于处理网络接收的数据包
BLOCK表示块设备软中断,用于处理磁盘读写请求。
TASKLET:任务中断,用于处理任务的中断任务。
SCHED 表示内核调度软中断
HRTIMER:高精度定时器中断,用于处理高精度定时任务。
RCU:Read-Copy Update中断,用于处理读写锁的内核操作。
-
现象:
-
几个指标都在变化中,但是NET_RX 是变化最多的
-
推断是网络接收软中断,用于处理网络接收的数据包 导致出现问题
-
-
查看网络流量命令 sar
sar -n DEV 1 -h
#-n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据 -h人类可读方式

-
分析网卡数据包
- ens33:接收的网络帧(包) PPS较大为20387, 而每秒收到的数据包大小BPS为1194。
-
进一步抓包分析
tcpdump -i ens33 -n tcp port 80
| 参数 | 说明 |
|---|---|
| -i | 指定抓哪个网卡接口的数据包 |
| -n | 不解析协议名和主机名,避免DNS解析 |
| tcp port 80 | 只抓取tcp协议并且端口号位80 的网络帧 |
| -e | 显示mac地址 |
| -w | write写入保存到文件 |
| -r | read读取文件中的数据 |
| -c | 在收到指定包数目之后,tcpdump就会停止 |

对输出结果进行分析:
第一列:时分秒毫秒
第二列:网络协议 IP
第三列:发送方的ip地址
第四列:箭头 > 表示数据流向
第五列:接收方的ip地址
第六列:冒号
第七列:数据包内容,包括Flags 标识符,seq 号,ack 号,win 窗口,数据长度 length
更多标识符:使用 tcpdump 抓包后,会遇到的 TCP 报文 Flags,有以下几种:
[S] : SYN(开始连接)
[P] : PSH(推送数据)
[F] : FIN (结束连接)
[R] : RST(重置连接)
[.] : 没有 Flag (意思是除上面四种类型外的其他情况,有可能是 ACK 也有可能是 URG)
-
分析
-
大部分数据都是从192.168.159.170 > 192.168.159.110.http: Flags [S] ,数据包是SYN
-
确认是 SYN FLOOD 洪水攻击
-
4.TCP洪水攻击结果分析和解决方案
(1)分析洪水攻击结果现象
- 查看系统最大半连接队列大小
cat /proc/sys/net/ipv4/tcp_max_syn_backlog

- 查看SYN半连接队列大小
方式一:
ss -s
结果的 synrecv 0 就是
方式二:
netstat -natp | grep SYN_RECV | wc -l

- 查看 SYN半连接队列是否有溢出
netstat -s|grep LISTEN

- 攻击时也可以查看 SYN_RECV 状态的连接数
netstat -n -p | grep SYN_RECV | wc -l

(2)缓解TCP洪水攻击方案
- 开启tcp_cookie
vim /etc/sysctl.conf
net.ipv4.tcp_syncookies = 1
修改完之后,需要执行 sysctl -p 配置才能生效。
现象:开启tcp_cookie之后,再次攻击,发现机器服务(192.168.159.110)可以访问成功,但是会有卡顿,如果是多节点DDOS攻击,仍然会造成服务不可用
-
增大半连接队列和全连接队列
-
半连接队列的最大长度不一定由 tcp_max_syn_backlog 值决定的
-
测试发现服务端最多只有 256 个半连接队列而不是 1024,Linux 内核版本实现不一样,和somaxconn全连接队列也有关系
-
增加半连接队列大小不能只增大 tcp_max_syn_backlog 的值,还要一同增大 somaxconn 即增大全连接队列
-
#增大 tcp_max_syn_backlog(半连接队列)
echo 2048 > /proc/sys/net/ipv4/tcp_max_syn_backlog
#增大 somaxconn(全连接队列)
echo 2048 > /proc/sys/net/core/somaxconn
- 减少 SYN+ACK 重传次数(减小tcp_synack_retries的值)
# 减少SYN+ACK 的重传次数为1,加快处于SYN_REVC 状态的 TCP 连接断开
echo 1 > /proc/sys/net/ipv4/tcp_synack_retries
- 现象和思路总结
当发现服务器或者业务卡顿的时候,通过top命令来查看服务器负载和cpu使用率,然后排查cpu占用较高的进程。
如果发现cpu的使用率并不高,但是si 软中断很高,且ksoftirqd进程cpu占用率高,则说明服务器持续发生软中断。
通过cat /proc/softirqs来分析是哪个类型的软中断次数最多,watch命令查看变化快速的值。
多数情况下网络发生中断的情况会比较多,通过sar命令来查看收包速率和收发包数据量。验证是否是网络收发包过多导致。
通过tcpdump来抓包,分析数据包来源ip和抓包数据中的Flags来分析数据包类型。
如果是Flood洪水攻击,可以通过调整tcp链接参数策略和防火墙封禁异常的IP。
如果是大规模的DDOS攻击,则花钱招运营商购买流量封堵。
5.TCP底层四次挥手详细流程
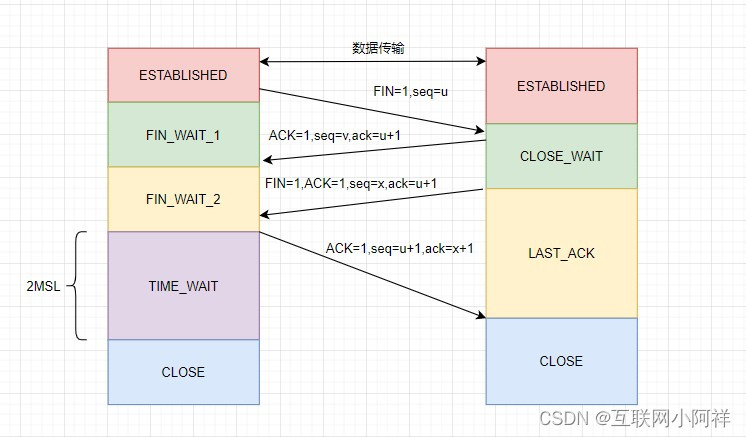
- TCP通过三次握手建立连接,而断开连接则是通过四次挥手,详细流程如下:
- 第一次
- 客户端发送FIN(Finish)报文段,用于关闭客户端到服务端的数据传输,表示客户端数据发送完毕。
- 客户端进入FIN_WAIT_1状态。
- 第二次
- 服务端收到客户端的FIN报文后,发送ACK报文段,确认收到了客户端的FIN报文段。
- 服务端进入CLOSE_WAIT状态,客户端接收到这个确认包后进入FIN_WAIT_2状态。
- 第三次
- 服务端发送FIN报文段,用于关闭服务端到客户端的数据传输,表示服务端的数据发送完毕。
- 服务端进入LAST_ACK状态,等待客户端的最后一个ACK。
- 第四次
- 客户端收到服务端的FIN报文段后,发送ACK报文段,确认收到了服务端的FIN报文段。
- 客户端接收后进入TIME_WAIT状态,在此阶段下等待2MSL时间(两个最大段生命周期)
- 如果这个时间间隔内没有收到服务端的请求,进入CLOSED状态,服务端收到ACK确认包之后,也进入到CLOSED状态。
- 第一次
-
思考:为啥TIME_WAIT要等待2MSL时间?
-
2MSL是报文最大生存时间,是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
-
假如最后一次客户端发送ACK给服务端没有收到,超时后 服务端重发FIN,客户端响应ACK,来回就是2个MSL。
-
等待2MSL,可以让本次连接持续的时间内所产生的所有报文都从网络中消失,避免旧的报文段。
-
-
思考:CLOSE-WAIT 和 TIME-WAIT 的区别?
-
CLOSE-WAIT是等待关闭
- 服务端收到客户端关闭连接的请求并确认之后,进入CLOSE-WAIT状态。
- 但服务端可能还有一些数据没有传输完成,不能立即关闭连接
- 所以CLOSE-WAIT状态是为了保证服务端在关闭连接之前将待发送的数据处理完
-
TIME-WAIT是在第四次挥手
- 当客户端向服务端发送ACK确认报文后进入TIME-WAIT状态,主动关闭连接的,才有time_wait状态
- 在HTTP请求中,如果connection头部的取值设置为close,那么多数都由服务端主动关闭连接
- 服务端处理完请求后主动关闭连接,所以服务端出现大量time_wait状态
- 防⽌旧连接的数据包
- 如果客户端收到服务端的FIN报文之后立即关闭连接,但服务端对应的端口并没有关闭
- 客户端在相同端口建立新的连接,可能导致新连接收到旧连接的数据包,从而产生问题
- 保证连接正确关闭
- 假如客户端最后一次发送的ACK包在传输的时候丢失,由于TCP协议的超时重传机制,服务端将重发FIN报文
- 如果客户端不是TIME-WAIT状态而直接关闭的话,当收到服务端重送的FIN包时,客户端会用RST包来响应服务端
- 导致服务端以为有错误发生,但实际是关闭连接是没问题的
- 当客户端向服务端发送ACK确认报文后进入TIME-WAIT状态,主动关闭连接的,才有time_wait状态
-
-
思考:TIME-WAIT状态有啥坏处?
-
过多TIME-WAIT状态 会占用文件描述符/内存资源/CPU 和端口,占满所有端口,则会导致无法创建新连接
-
高并发短连接的TCP服务器上
-
当服务器处理完请求后立刻主动正常关闭连接,会出现大量socket处于TIME_WAIT状态
-
端口有个0~65535的范围,排除系统和其他服务要用的,剩下的很少
-
查看time_wait状态连接数
netstat -an |grep TIME_WAIT|wc -l
-
-
解决方案
- 调整短链接为长链接,HTTP 请求的头部,connection 设置为 keep-alive,减少TCP的连接和断开
- 目前版本的http协议基本上都是支持长连接
- 配置**
SO_REUSEADDR**,在 端口不够用时,TCP连接位于TIME_WAIT状态时可以重用端口- 对应linux系统配置
net.ipv4.tcp_tw_reuse=1
- 对应linux系统配置
- 导致服务端以为有错误发生,但实际是关闭连接是没问题的
- 调整短链接为长链接,HTTP 请求的头部,connection 设置为 keep-alive,减少TCP的连接和断开
-
-
-
思考:TIME-WAIT状态有啥坏处?
-
过多TIME-WAIT状态 会占用文件描述符/内存资源/CPU 和端口,占满所有端口,则会导致无法创建新连接
-
高并发短连接的TCP服务器上
-
当服务器处理完请求后立刻主动正常关闭连接,会出现大量socket处于TIME_WAIT状态
-
端口有个0~65535的范围,排除系统和其他服务要用的,剩下的很少
-
查看time_wait状态连接数
netstat -an |grep TIME_WAIT|wc -l
-
-
解决方案
- 调整短链接为长链接,HTTP 请求的头部,connection 设置为 keep-alive,减少TCP的连接和断开
- 目前版本的http协议基本上都是支持长连接
- 配置**
SO_REUSEADDR**,在 端口不够用时,TCP连接位于TIME_WAIT状态时可以重用端口- 对应linux系统配置
net.ipv4.tcp_tw_reuse=1
- 对应linux系统配置
- 缩减 time_wait 时间,设置为 1 MSL
- 调整短链接为长链接,HTTP 请求的头部,connection 设置为 keep-alive,减少TCP的连接和断开
-
-