目录
一、ClickHouse高可用之ReplicatedMergeTree引擎
二、 ClickHouse高可用架构准备-环境说明和ZK搭建
三、高可用集群架构-ClickHouse副本配置实操
四、ClickHouse高可用集群架构分片
4.1 ClickHouse高可用架构之两分片实操
4.2 ClickHouse高可用架构之两分片建表实操
一、ClickHouse高可用之ReplicatedMergeTree引擎
什么是CK的副本引擎:
两个相同数据的表, 作用是为了数据备份与安全,保障数据的高可用性。
副本是表级别的,不是整个服务器级的,服务器里可以同时有复制表和非复制表。
副本不依赖分片,每个分片有它自己的独立副本。
副本写入的流程和注意事项:(这是重点-面试问的多 哈哈)
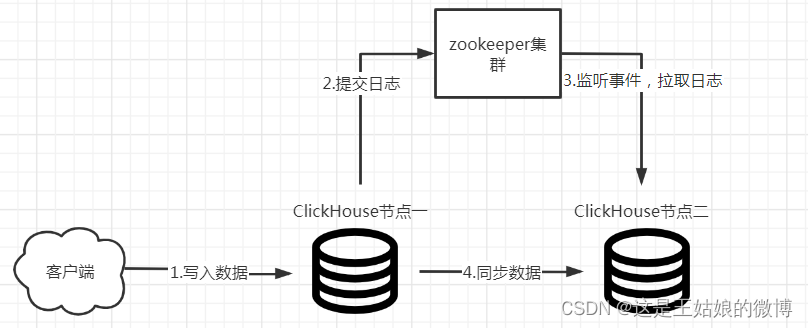
数据传输是不经过ZK的,ZK只是一个协调者的身份。
副本写入流程和注意事项:
复制是多主异步
1.数据会先插入到执行该语句的服务器上,然后被复制到其他服务器。(复制是多主异步的,客户端写完之后就可以返回)
2.由于它是异步的,在其他副本上最近插入的数据会有一些延迟。当部分副本挂了的时候,数据会在该副本恢复正常的时候,再继续进行同步
其中副本可用的情况下,会有些许延迟,那延迟的时长就是通过网络传输、压缩数据块所需的时间。
3.默认情况下,INSERT 语句仅等待一个副本写入成功后返回,如果数据只成功写入一个副本后该副本所在的服务器不再存在,则存储的数据会丢失
4.要启用数据写入多个副本才确认返回,使用 insert_quorum 进行配置,但是会影响性能
5.对于 INSERT 和 ALTER 语句操作数据的会在压缩的情况下被复制,而 CREATE,DROP,ATTACH,DETACH 和 RENAME 语句只会在单个服务器上执行,不会被复制。
副本合并树引擎ReplicatedMergeTree
如果有两个副本的话,相当于分布在两台clickhosue节点中的两个表,
这个两个表具有协调功能, 无论是哪个表执行insert或者alter操作,都会同步到另外一张表,副本就是相互同步数据的表
副本同步需要借助zookeeper实现数据的同步, 副本节点会在zk上进行监听,但数据同步过程是不经过zk的
zookeeper要求3.4.5以及以上版本
建表:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = ReplicatedMergeTree('{zoo_path}', '{replica_name}')
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
语句:
CREATE TABLE tb_order
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/tb_order', 'tb_order_01')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)ReplicatedMergeTree 参数
zoo_path — zk 中该表的路径,可自定义名称,同一张表的同一分片的不同副本,要定义相同的路径;
replica_name — zk 中的该表的副本名称,同一张表的同一分片的不同副本,要定义不同的名称;
«ZooKeeper 中该表的路径»对每个可复制表都要是唯一的,不同分片上的表要有不同的路径
推荐格式 即 【通用前缀】【分片标识部分】/clickhouse/tables/{shard}/{table_name}
大括号的部分的可以用参数替代
二、 ClickHouse高可用架构准备-环境说明和ZK搭建
高可用架构需要ZK
副本同步需要借助zookeeper实现数据的同步, 副本节点会在zk上进行监听,但数据同步过程是不 经过zk的,zk是个协调者
zookeeper要求3.4.5以及以上版本
使用Docker部署即可
机器准备
机器一:(Docker安装ZK) 112.xxx.xxx.240
机器二:(RPM安装ClickHouse) 120.xxx.xxx.49
机器三:(RPM安装ClickHouse) 120.xx.xxx.202
第一步:在机器一上面安装zk
Docker部署ZK
docker run -d --name zookeeper -p 2181:2181 -t zookeeper:3.7.0
第二步 :在机器二/三上面 通过RPM方式部署CK 版本:ClickHouse 22.1.2.2
安装文档地址:安装 | ClickHouse Docs
#各个节点上传到新建文件夹
/usr/local/software/*#安装
sudo rpm -ivh *.rpm#启动
systemctl start clickhouse-server#停止
systemctl stop clickhouse-server#重启
systemctl restart clickhouse-server#状态查看
sudo systemctl status clickhouse-server#查看端口占用,如果命令不存在 yum install -y lsof
lsof -i :8123
#查看日志
tail -f /var/log/clickhouse-server/clickhouse-server.log
tail -f /var/log/clickhouse-server/clickhouse-server.err.log
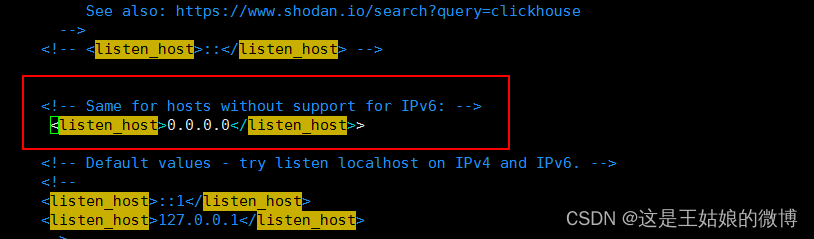
#开启远程访问,取消下面的注释
vim /etc/clickhouse-server/config.xml#编辑配置文件
<listen_host>0.0.0.0</listen_host>#重启
systemctl restart clickhouse-server
实操:
1. 先把几个rpm文件上传到/usr/local/software目录下
2.cd /usr/local/software sudo rpm -ivh *.rpm进行安装

中间会停顿下让你输入密码,直接回车即可。
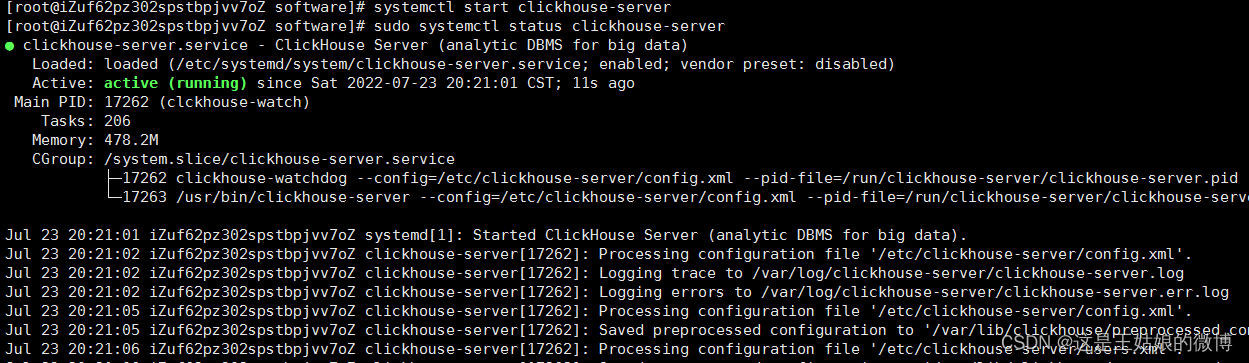
3.安装后需要启动 systemctl start clickhouse-server
查看启动状态:sudo systemctl status clickhouse-server
4.查看端口占用
 5.查看日志
5.查看日志
tail -f /var/log/clickhouse-server/clickhouse-server.log

6.取消下面的注释 开启远程访问
vim /etc/clickhouse-server/config.xml
7.重启ck
systemctl start clickhouse-server
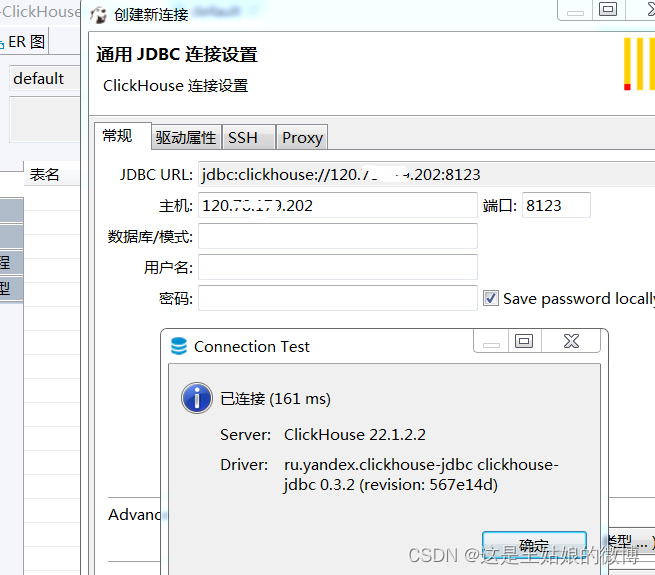
8.远程工具连接

到这就完成RPM形式的单机部署~将机器三,也按照这种形式部署起来 然后继续下面的副本配置操作
注意:阿里云部署时,报错 <Error> DNSResolver: Cannot resolve host (iZwz9bg08mzvexxkzyu7iiZ), error 0: iZwz9bg08mzvexxkzyu7iiZ
DB::Exception: Not found address of host
解决:增加ip和host域名
sudo vim /etc/hosts
在集群副本的hosts文件中,增加局域网ip和hostname即可
三、高可用集群架构-ClickHouse副本配置实操
第一步:机器二、机器三都需要配置
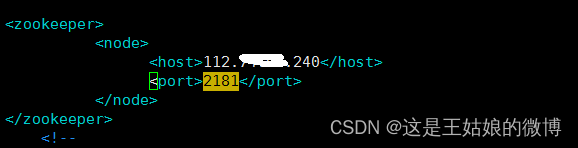
vim /etc/clickhouse-server/config.xml
<zookeeper>
<node>
<host>112.xx.xxx.240</host>#一开始使用docker安装的那个zk公网IP地址
<port>2181</port>
</node>
</zookeeper><interserver_http_host>120.xx.xx.202</interserver_http_host>#当前机器的IP地址
wq!保存退出
重启:
实操 -->2台机器都要更改后重启:
更改1
更改2

第二步:在每个机器上创建表
副本同步,同步的是数据,表结构是不会同步的
#节点一,zk路径一致,副本名称不一样
CREATE TABLE tb_product
(
userId UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/tb_product', 'product-replica-1')
ORDER BY (userId)#节点二,zk路径一致,副本名称不一样
CREATE TABLE tb_product
(
userId UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/tb_product', 'product-replica-2')
ORDER BY (userId)#查询zk配置
select * from system.zookeeper where path='/'
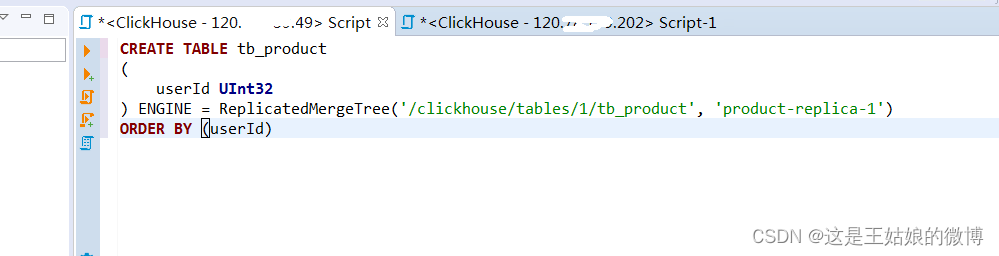 注意:副本只能同步数据,不能同步表结构,需要在每台机器上手动建表
注意:副本只能同步数据,不能同步表结构,需要在每台机器上手动建表
演示:在其中任何一个节点插入数据,然后去另外一个节点上面查看

在202机器上可以查看到结果 
四、ClickHouse高可用集群架构分片
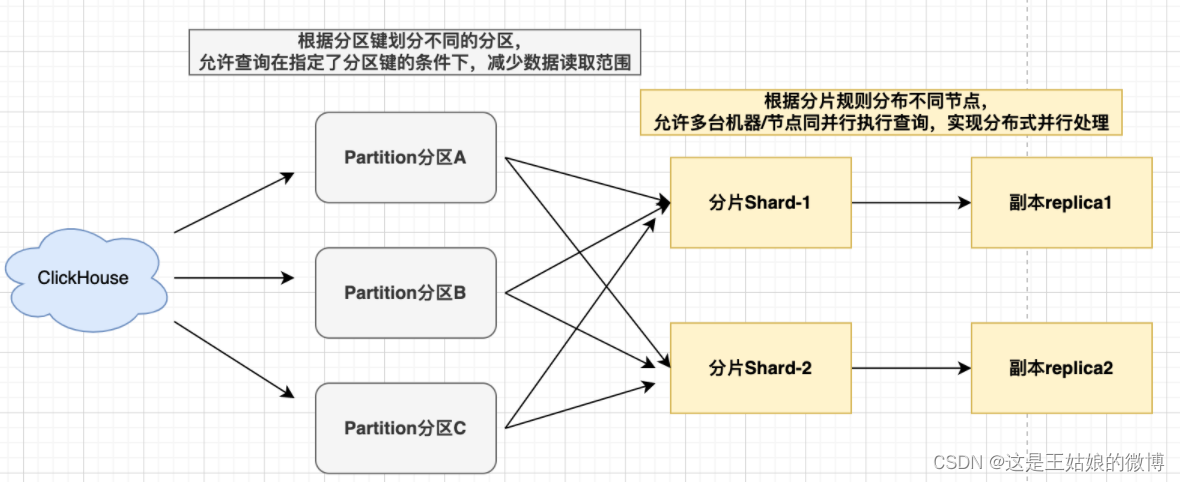
什么是ClickHouse的分片
数据分片-允许多台机器/节点同并行执行查询,实现了分布式并行计算
分片间的数据是不同的,不同的服务器存储同一张表的不同部分,作用是为了水平切分表,缓解单节点的压力
分布式表引擎Distributed
官方文档:分布式引擎 | ClickHouse Docs
分布式表引擎Distributed:Distributed表引擎主要是用于分布式,自身不存储任何数据,数据都分散存储在某一个分片上,能够自动路由数据至集群中的各个节点,需要和其他数据表引擎一起协同工作.主要起汇总返回的作用。
一张分布式表底层会对应多个分片数据表,由具体的分片表存储数据,分布式表与分片表是一对多的关系。分布式表主要有本地表(xxx_local)和分布式表(xxx_all)两部分组成

建表语法:
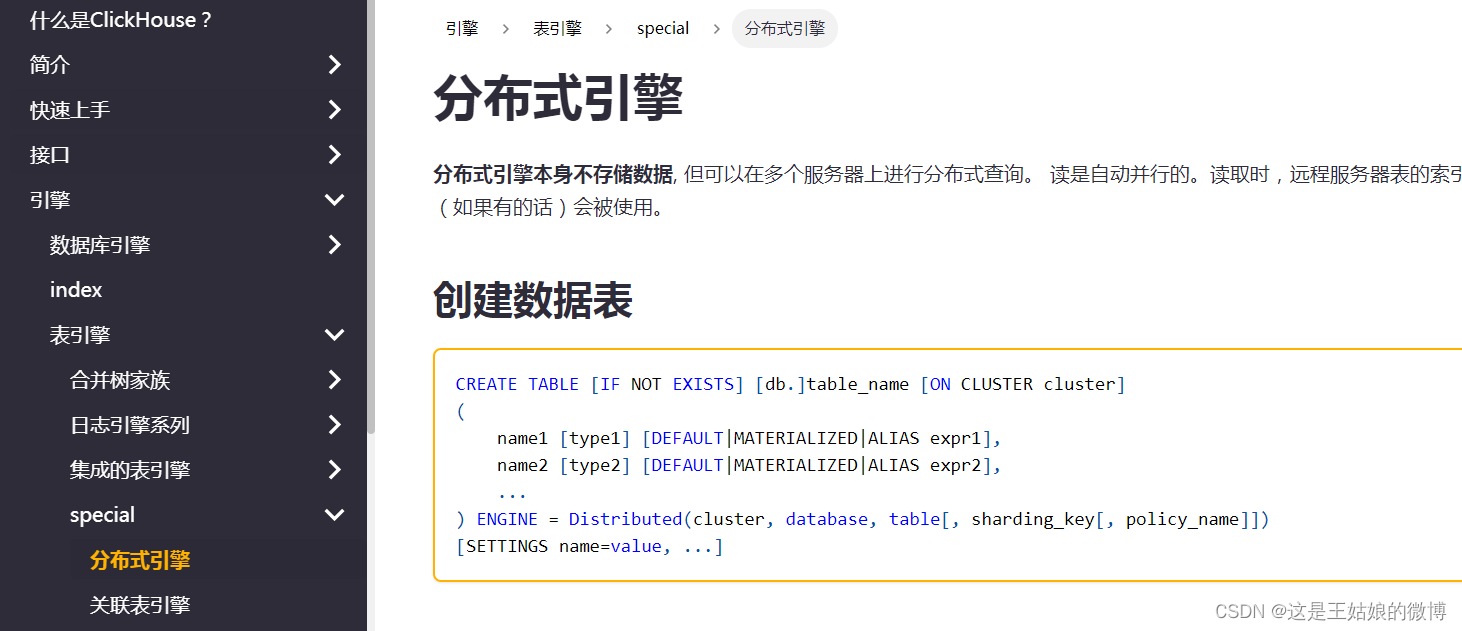
参数:
cluster:集群名称,与集群配置中的自定义名称相对应,比如 wnn_shard。
database:数据库名称
**table:本地表名称
sharding_key:可选参数,用于分片的key值,在写入的数据Distributed表引擎会依据分片key的规则,将数据分布到各个节点的本地表
user_id等业务字段、rand()随机函数等规则
参数详细说明,见官方文档 分布式引擎 | ClickHouse Docs
多分片表查询方式:
本着谁执行谁负责的原则,向ClickHouse发起分布式表执行SELECT * FROM distributed_table
它会转为如下形式SELECT * FROM local_table,先执行本地分片,再发送远端各分片执行
合并结果为临时表返回
4.1 ClickHouse高可用架构之两分片实操
第一步:在[每个ClickHouse机器上]做配置
#进入配置目录
cd /etc/clickhouse-server
#编辑配置文件
sudo vim config.xml
<!-- 2shard 1replica -->
<cluster_2shards_1replicas>
<!-- shard1 -->
<shard>
<replica>
<host>120.xx.xxx.49</host>
<port>9000</port>
</replica>
</shard>
<!-- shard2 -->
<shard>
<replica>
<host>120.xxx.xxx.202</host>
<port> 9000</port>
</replica>
</shard>
</cluster_2shards_1replicas>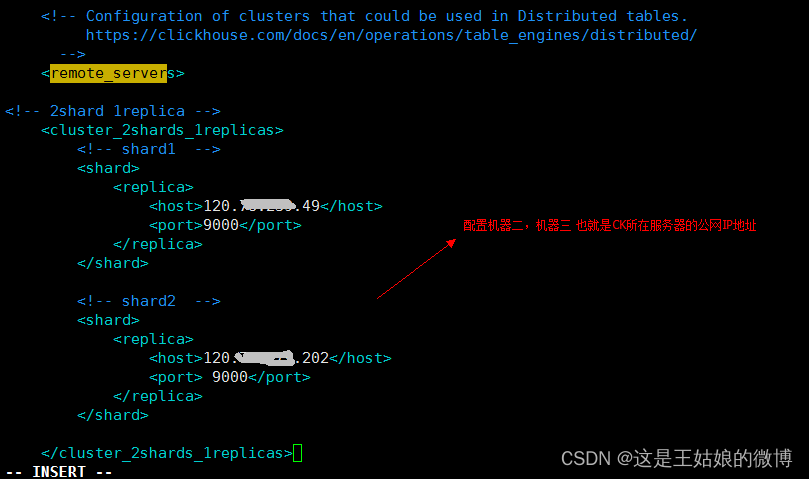
保存退出后,重启服务systemctl restart clickhouse-server
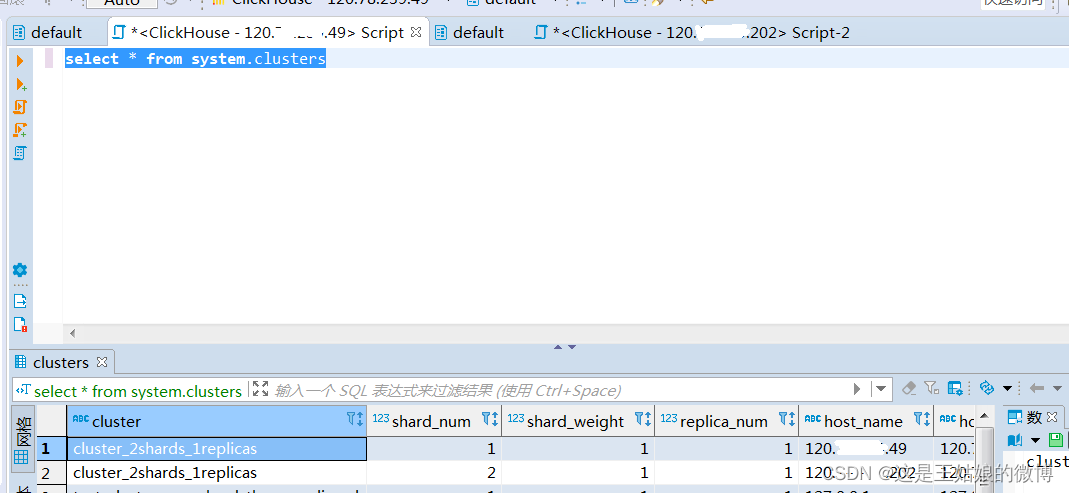
然后查询下分片是否成功:select * from system.clusters
可以看到集群名称 分片个数以及分片后的IP地址
每个节点重启ClickHouse
#重启
systemctl restart clickhouse-server
判断是否配置成功
重启ClickHouse前查询,查不到对应的集群名称,重启ClickHouse后能查询到
select * from system.clusters
4.2 ClickHouse高可用架构之两分片建表实操
分布式ddl指的是在一台服务器上执行sql,其他服务器同步执行,需要借助于cluster
建表实操:
#【选一个节点】创建好本地表后,在1个节点创建,会在其他节点都存在
create table default.wnn_order on cluster cluster_2shards_1replicas
(id Int8,name String) engine =MergeTree order by id;
#【选一个节点】创建分布式表名 wnn_order_all,在1个节点创建,会在其他节点都存在
create table wnn_order_all on cluster cluster_2shards_1replicas (
id Int8,name String
)engine = Distributed(cluster_2shards_1replicas,default, wnn_order,hiveHash(id));
#分布式表插入
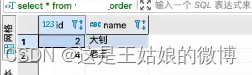
insert into wnn_order_all values(1,'冰冰'),(2,'大钊'),(3,'小D'),(4,'老王');
#【任意节点查询-分布式,全部数据】
SELECT * from wnn_order_all
#【任意本地节点查询,部分数据】
SELECT * from wnn_order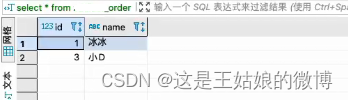
如何往集群中写入数据,方法有两种:
方式一:
自已指定要将哪些数据写入哪些服务器,并直接在每个分片上执行写入。
在分布式表上«查询»,在数据表上 INSERT
可以使用任何分片方案,对于复杂业务特性的需求,数据可以完全独立地写入不同的分片。
方式二
在分布式表上执行 INSERT。在这种情况下,分布式表会跨服务器分发插入数据。
为了写入分布式表,必须要配置分片键(最后一个参数)
如果只有一个分片,则写操作在没有分片键的情况下也能工作,这种情况下分片键没有意义
每个分片都可以在配置文件中定义权重。默认情况下,权重等于1。数据依据分片权重按比例分发到分片上
如果有两个分片,第一个分片的权重是9,而第二个分片的权重是10,则发送 9 / 19 的行到第一个分片, 10 / 19 的行到第二个分片。
注意:
每个clickhouse-server实例只能放一个分片的一个备份,3分片2备份需要6台机器,1个机器不能存放两个副本










![交换字符使得字符串相同[贪心]](https://img-blog.csdnimg.cn/2697794abadd4002bd7f0c3f9f4c2149.png)