问题说明
之前extension版的app工程都是用的软浮点编译的,在增加姿控算法库后,统一改用硬浮点运行,发现之前一个浮点数解析不对了,排查发现和工程编译选项有关,为软浮点时正常,硬浮点时异常。该问题脱离业务程序环境直接用test工程测试可复现。
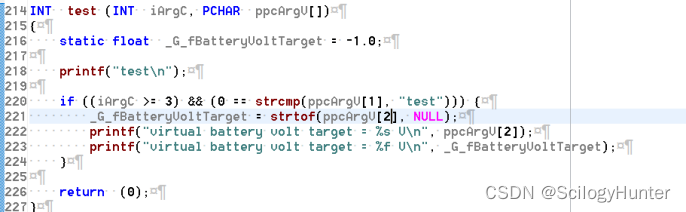
软浮点编译运行
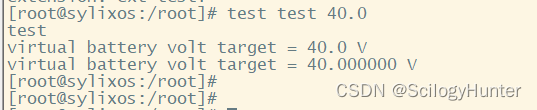
硬浮点编译运行

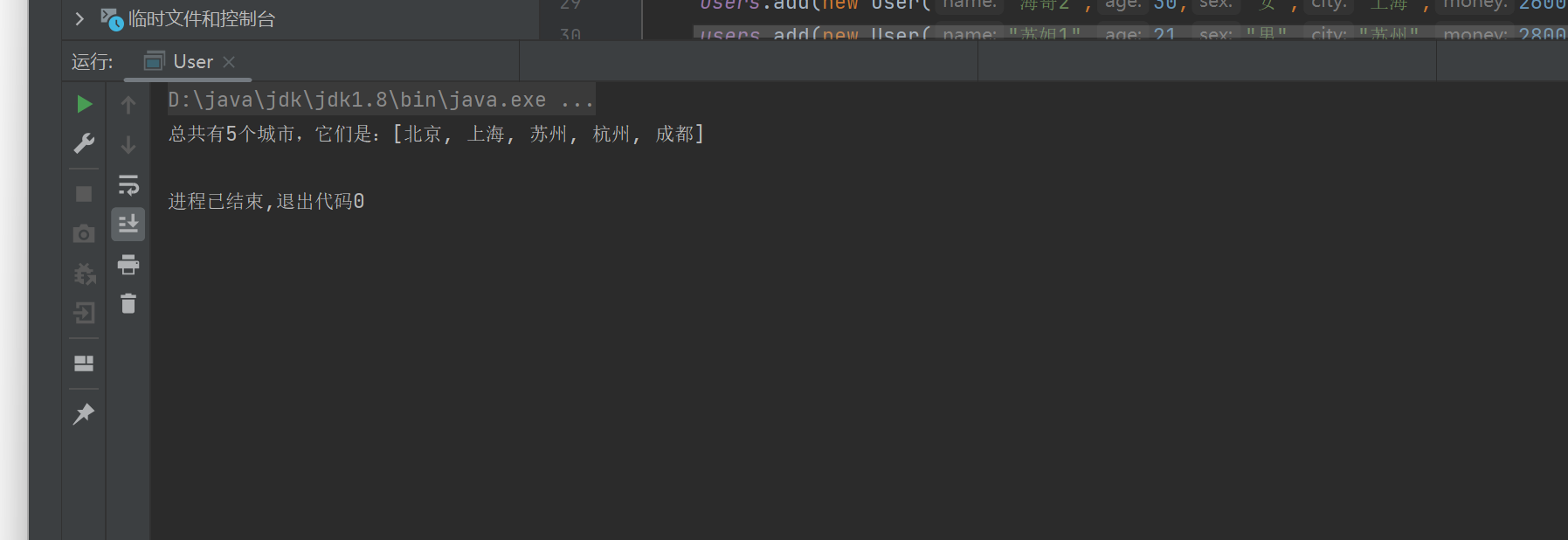
命令行输入字符串“40.0”程序解析出0.0。显然出错了,单系统并未奔溃。
初步分析
之前在该硬件平台(sparc V8体系结构)下专门测试过软硬浮点速度差异,计算结果都是正常的,硬浮点速度也显著提升。说明硬浮点本身运算没问题,怀疑是浮点二进制接口上出现了不匹配。
ABI汇编分析
脱离C库的浮点相关接口,只研究浮点二进制接口特性。
测试条件:
1.sparc V8体系结构,处理器无MMU
2. lite版Sylixos,app可独立开发,加载,运行但本质是静态链接的。
3. base和bsp都是软浮点编译,静态库硬浮点编译,app软浮点和硬浮点编译。
4. 都采用-O0编译,避免编译器优化,便于汇编分析
静态库函数源码如下:
float testfloat(float a, float b)
{
return (a + b);
}
软浮点编译,反汇编如下:
401b917c <testfloat>:
401b917c: 9d e3 bf a0 save %sp, -96, %sp
401b9180: f0 27 a0 44 st %i0, [ %fp + 0x44 ]
401b9184: f2 27 a0 48 st %i1, [ %fp + 0x48 ]
401b9188: d0 07 a0 44 ld [ %fp + 0x44 ], %o0
401b918c: d2 07 a0 48 ld [ %fp + 0x48 ], %o1
401b9190: 7f fe c6 a4 call 4016ac20 <__addsf3>
401b9194: 01 00 00 00 nop
401b9198: 82 10 00 08 mov %o0, %g1
401b919c: b0 10 00 01 mov %g1, %i0
401b91a0: 81 e8 00 00 restore
401b91a4: 81 c3 e0 08 retl
401b91a8: 01 00 00 00 nop
硬浮点编译,反汇编如下:
401b8e48 <testfloat>:
401b8e48: 9c 03 bf b0 add %sp, -80, %sp
401b8e4c: d0 23 a0 4c st %o0, [ %sp + 0x4c ]
401b8e50: d1 03 a0 4c ld [ %sp + 0x4c ], %f8
401b8e54: d2 23 a0 4c st %o1, [ %sp + 0x4c ]
401b8e58: d3 03 a0 4c ld [ %sp + 0x4c ], %f9
401b8e5c: 9c 03 a0 50 add %sp, 0x50, %sp
401b8e60: 81 c3 e0 08 retl
401b8e64: 81 a2 08 29 fadds %f8, %f9, %f0
app调用静态库函数源码:
extern float testfloat(float a, float b);
float floattest (float a, float b)
{
return (testfloat(a,b));
}
软浮点编译,反汇编如下:
401b5c20 <floattest>:
401b5c20: 9d e3 bf a0 save %sp, -96, %sp
401b5c24: f0 27 a0 44 st %i0, [ %fp + 0x44 ]
401b5c28: f2 27 a0 48 st %i1, [ %fp + 0x48 ]
401b5c2c: d0 07 a0 44 ld [ %fp + 0x44 ], %o0
401b5c30: d2 07 a0 48 ld [ %fp + 0x48 ], %o1
401b5c34: 40 00 0c 85 call 401b8e48 <testfloat>
401b5c38: 01 00 00 00 nop
401b5c3c: 82 10 00 08 mov %o0, %g1
401b5c40: b0 10 00 01 mov %g1, %i0
401b5c44: 81 e8 00 00 restore
401b5c48: 81 c3 e0 08 retl
401b5c4c: 01 00 00 00 nop
硬浮点编译,反汇编如下:
401b2f18 <floattest>:
401b2f18: 9d e3 bf a0 save %sp, -96, %sp
401b2f1c: f0 27 a0 44 st %i0, [ %fp + 0x44 ]
401b2f20: f2 27 a0 48 st %i1, [ %fp + 0x48 ]
401b2f24: d0 07 a0 44 ld [ %fp + 0x44 ], %o0
401b2f28: d2 07 a0 48 ld [ %fp + 0x48 ], %o1
401b2f2c: 40 00 0c 85 call 401b6140 <testfloat>
401b2f30: 01 00 00 00 nop
401b2f34: 91 a0 00 20 fmovs %f0, %f8
401b2f38: 81 a0 00 28 fmovs %f8, %f0
401b2f3c: 81 e8 00 00 restore
401b2f40: 81 c3 e0 08 retl
401b2f44: 01 00 00 00 nop
显然,
软浮点编译时,输入参数是通过定点寄存器 %i0, %i1传递,输出用定点寄存器%o0传递;
硬浮点编译时,输入参数是通过定点寄存器 %i0, %i1传递,输出用浮点寄存器%f0传递;
函数调用方和被调研方,如果使用相同的浮点编译方法(同为软浮点编译或同为硬浮点编译)则都可以得到正确结果。
而上述bug出错就源于,一个硬浮点编译的函数调用了一个软浮点编译的函数,被调用函数把结果放到了%o0寄存器中,而调用方却去%f0寄存器中获取结果,自然就出错了。
解决思路
现在的问题是,base,bsp必须用软浮点编译,app可以是软浮点也可以是硬浮点编译,app用到的一个静态库里面有大量浮点计算要求必须硬浮点编译。这时app用软浮点编译和静态库有冲突,用硬浮点编译和base 库有冲突。
首先想到的是用-mfloat-abi=softfp编译选项来编译静态库,让静态库即能用到硬浮点的提速又能在接口上和其他程序兼容。
- -mfloat-abi=soft 调用软浮点库(softfloat lib 定点运算)来实现浮点运算,浮点参数通过定点寄存器传递.
- -mfloat-abi=hard 调用FPU硬浮点指令实现浮点运算, 浮点参数一般通过浮点寄存器传递.。
- -mfloat-abi=softfp 调用FPU硬浮点指令实现浮点运算,但浮点参数通过定点寄存器传递.
操作系统内核, 驱动程序, BSP, 内核模块一般采用 -mfloat-abi=soft 编译.如果存在 VFP 应用程序可使用 -mfloat-abi=softfp 来编译。
但可惜sparc-sylixos-elf-gcc没有此选项。arm-sylixos-eabi-gcc及其他体系结构是有该选项的。
$ sparc-sylixos-elf-gcc.exe --target-help
The following options are target specific:
-m32 Use 32-bit ABI
-m64 Use 64-bit ABI
-mapp-regs Use ABI reserved registers
-mcbcond Use UltraSPARC Compare-and-Branch extensions
-mcmodel= Use given SPARC-V9 code model
-mcpu= Use features of and schedule code for given CPU
-mdebug= Enable debug output
-mfaster-structs Use structs on stronger alignment for double-word
copies
-mfix-at697f Enable workaround for single erratum of AT697F
processor (corresponding to erratum #13 of AT697E
processor)
-mfix-ut699 Enable workarounds for the errata of the UT699
processor
-mflat Use flat register window model
-mfmaf Use UltraSPARC Fused Multiply-Add extensions
-mfpu Use hardware FP
-mhard-float Use hardware FP
-mhard-quad-float Use hardware quad FP instructions
-mmemory-model= Specify the memory model in effect for the
program.
-mpopc Use UltraSPARC Population-Count instruction
-mptr32 Pointers are 32-bit
-mptr64 Pointers are 64-bit
-mrelax Optimize tail call instructions in assembler and
linker
-msoft-float Do not use hardware FP
-msoft-quad-float Do not use hardware quad fp instructions
-mstack-bias Use stack bias
-mstd-struct-return Enable strict 32-bit psABI struct return checking.
-mtune= Schedule code for given CPU
-munaligned-doubles Assume possible double misalignment
-muser-mode Do not generate code that can only run in
supervisor mode
-mv8plus Compile for V8+ ABI
-mvis Use UltraSPARC Visual Instruction Set version 1.0
extensions
-mvis2 Use UltraSPARC Visual Instruction Set version 2.0
extensions
-mvis3 Use UltraSPARC Visual Instruction Set version 3.0
extensions
$ arm-sylixos-eabi-gcc.exe --target-help
The following options are target specific:
-mabi= Specify an ABI
-mabort-on-noreturn Generate a call to abort if a noreturn function
returns
-mapcs-float Pass FP arguments in FP registers
-mapcs-frame Generate APCS conformant stack frames
-mapcs-reentrant Generate re-entrant, PIC code
-march= Specify the name of the target architecture
-marm Generate code in 32 bit ARM state.
-mbig-endian Assume target CPU is configured as big endian
-mcallee-super-interworking Thumb: Assume non-static functions may be called
from ARM code
-mcaller-super-interworking Thumb: Assume function pointers may go to non-
Thumb aware code
-mcpu= Specify the name of the target CPU
-mfix-cortex-m3-ldrd Avoid overlapping destination and address
registers on LDRD instructions that may trigger
Cortex-M3 errata.
-mfloat-abi= Specify if floating point hardware should be used
-mfp16-format= Specify the __fp16 floating-point format
-mfpu= Specify the name of the target floating point
hardware/format
-mlittle-endian Assume target CPU is configured as little endian
-mlong-calls Generate call insns as indirect calls, if
necessary
-mlra Use LRA instead of reload (transitional)
-mneon-for-64bits Use Neon to perform 64-bits operations rather
than core registers.
-mnew-generic-costs Use the new generic RTX cost tables if new core-
specific cost table not available (transitional).
-mold-rtx-costs Use the old RTX costing tables (transitional).
-mpic-data-is-text-relative Assume data segments are relative to text segment.
-mpic-register= Specify the register to be used for PIC addressing
-mpoke-function-name Store function names in object code
-mrestrict-it Generate IT blocks appropriate for ARMv8.
-msched-prolog Permit scheduling of a function's prologue
sequence
-msingle-pic-base Do not load the PIC register in function prologues
-mslow-flash-data Assume loading data from flash is slower than
fetching instructions.
-mstructure-size-boundary= Specify the minimum bit alignment of structures
-mthumb Generate code for Thumb state
-mthumb-interwork Support calls between Thumb and ARM instruction
sets
-mtls-dialect= Specify thread local storage scheme
-mtp= Specify how to access the thread pointer
-mtpcs-frame Thumb: Generate (non-leaf) stack frames even if
not needed
-mtpcs-leaf-frame Thumb: Generate (leaf) stack frames even if not
needed
-mtune= Tune code for the given processor
-munaligned-access Enable unaligned word and halfword accesses to
packed data.
-mvectorize-with-neon-double Use Neon double-word (rather than quad-word)
registers for vectorization
-mvectorize-with-neon-quad Use Neon quad-word (rather than double-word)
registers for vectorization
-mword-relocations Only generate absolute relocations on word sized
values.
-mwords-little-endian Assume big endian bytes, little endian words.
This option is deprecated.
另一个方法是这样的,APP和算法库都使用硬浮点编译,这时,app调用的base库里的会返回浮点数的函数接口就会出错,那把这些函数单独用硬浮点编译一个libcfoat静态库,app同时连接base和libcfoat两个库,其中返回浮点的用libcfoat静态库中的,其他用base静态库中的。这这方式实现会比较繁琐,但也能解决浮点接口冲突问题。