一、二进制
为什么要编码? 在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0)
我们用QQ给其他人发消息、发文件、发表情,最终会以二进制形式在网路中传输,到达后再转换回来
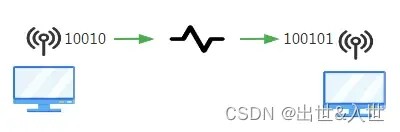
本地存储也一样,最终都是以二进制形式存储在计算机中
二、ASCII
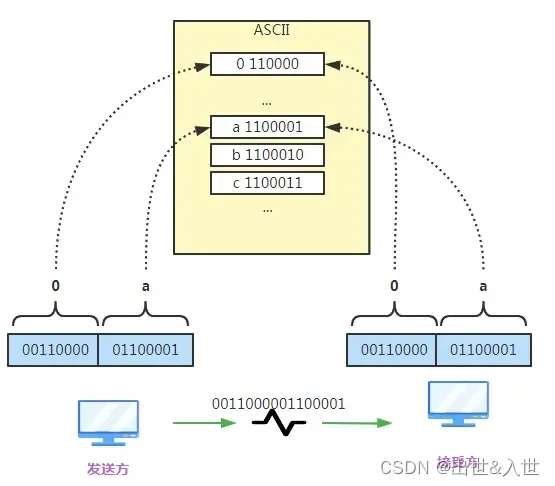
问题来了,A电脑想给B电脑传送一个"a",假如转换的二进制是"110",那么B怎么知道这个二进制代表的是"a"呐
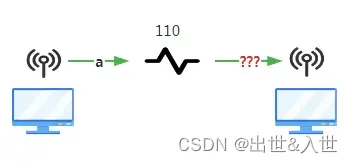
问题主要原因是大家没有共识,就像甲地区110代表"a",到了乙地区110代表"b",两个地区就没办法正常交流
为了解决这个问题,一个叫标准化组织的单位(ISO)出面了:由我们来制定每个字母和二进制的对照关系,大家都按我这个对照关系转换即可(由于最早计算机是美国人玩的,所以需要建立对照关系的也就是英文字母和一些特殊字符),这个由ISO制定的对照关系就是ASCII编码,可以理解为给每个字符设置了一个唯一的ID
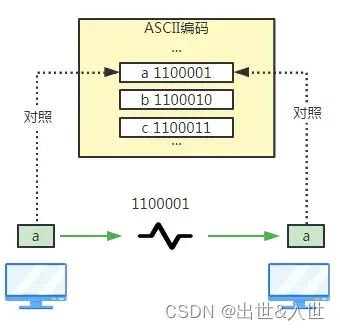
由于有了ASCII编码,大家就有了共识,互相沟通再无障碍
三、Unicode
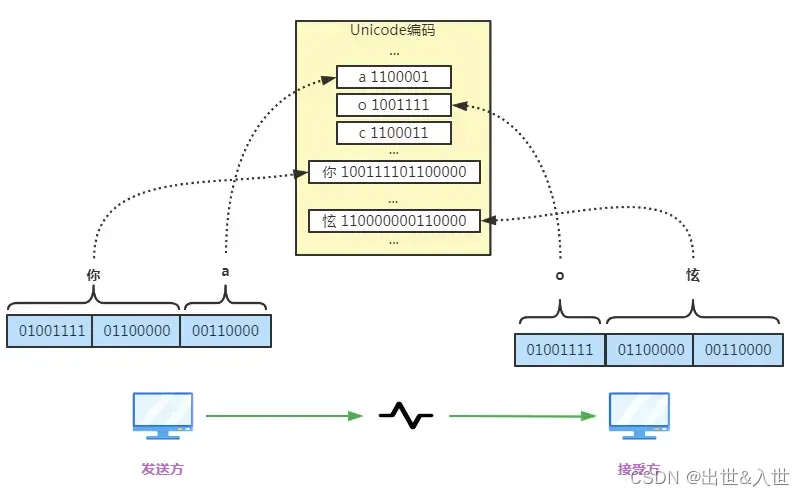
后来时代再发展,越来越多的国家开始用计算机了,这时ASCII码就不够用了,比如“大”在ASCII码中找不到对应的二进制啊,那应该编多少?
为了解决这个问题,ISO又出面了,扩展对照关系,把世界上所有的语言的字符都加入到这个新对照关系,并重新命名为Unicode码,又叫万国码,霸气~
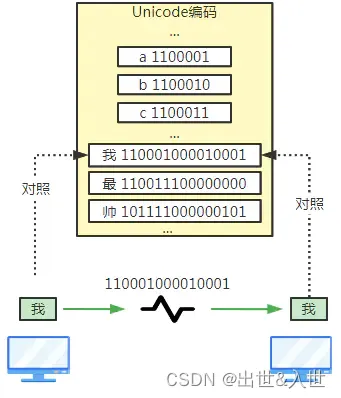
可以发现二进制的位数变长了,因为原来ASCII字符少,现在把世界的字符都加上就越来越长了
四、实现
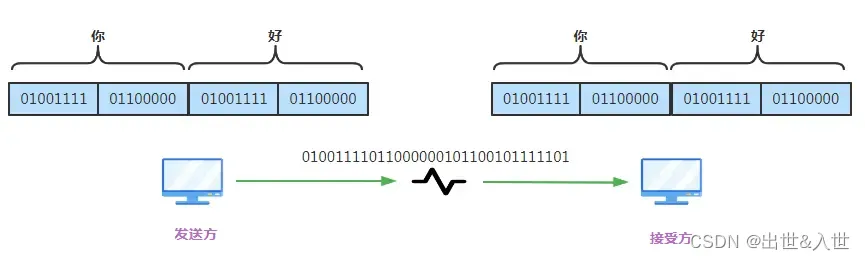
问题又来了,以上的图片每次都是只发送一个字符“a”和 “我”,但实际中我们传递信息肯定都是很多字符组成的句子,比如现在我们发"0a"两个字符,其中0的二进制是110000,a的二进制是1100001,如果发出去合起来就是1100001000001,这时候读法就有意思了,不同的断句读的结果就不一样
比如向后错开一位读取结果就变成了"a!"
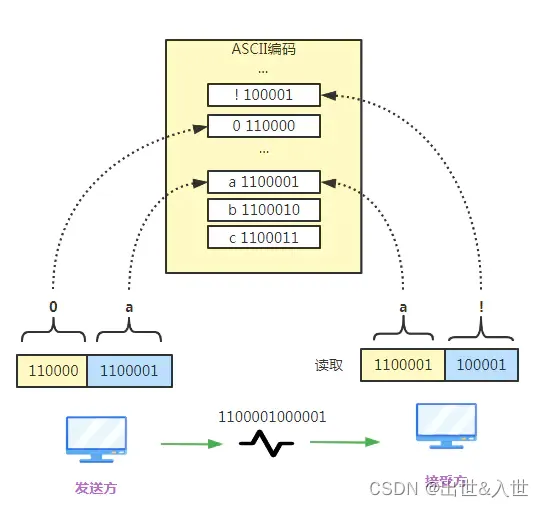
像极了了《九品芝麻官》里的搞笑状纸:
- 收回黄公年租银两三十,万不能转租别人
- 收回黄公年租银两三十万,不能转租别人

所以,光有共识的编码规则并不够,还要真正的实现方式(怎么找到字符和字符的边界),最简单的实现方法就是固定每个字符的二进制长度,不足的前面补零,早期的ASCII码8位二进制足以表示,所以就8位代表一个字符,这8位被称作一个字节,这是ASCII编码的早期实现
那么发展到现在,ASCII不够用了,改用Unicode,最大16位足以标识,可以用两个字节即16位代表一个字符,自然也不会出现断句错误问题,这就是Unicode的最简单实现方式,这种实现方式叫UTF-16
五、UTF-8
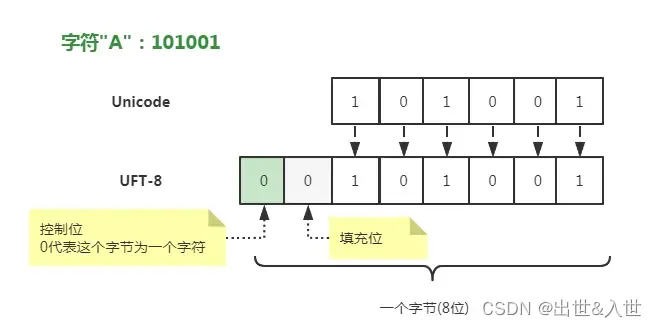
UTF-16可以正常进行网络交流信息,但有个致命的弱点:比如要发送一个阿拉伯数字"1","1"的Unicode码位是110001,6位二进制足够了,确因为要填满16位而在前面填充了10个0,这真是对网络和存储空间极大的浪费
于是,一种更为合理的Unicode编码实现方式UTF-8被广泛使用
UTF-8为什么更加合理?它的核心思想很简单:当字符Unicode码位小的时候少占用字节,码位大时多占字节
这个思想很简单,落地还是有问题要解决的,比如一个电脑接受到了多个字节,怎么知道某一个字节是一个字符,还是这个一个字节和下一个字节共同组成一个字符,如果没有一种方法去标识,还是会产生阅读误区
UTF-8的解决方案如下,定义了一套规则:
- 如果是单字节代表一个字符,首位是0(控制位),剩余位是Unicode码(剩余7位),因此Unicode码位是7位以下的字符(编码十进制0 ~ 127)就可以用单字节传输,比如英文字符都符合7位以下,因此在utf-8中,英文字符占一个字节
由于英文占一一个字节,使得UTF-8可以完美兼容ASCII,这也是它被用的最广泛的原因
-
如果是n字节代表一个字符,第一个字节n个1一个0开头作为控制位,其余字节以10开头作为控制位,所有字节的剩余位数合并代表Unicode值
双字节如下:
双字节 其中黑色XXX存放的是Unicode,总共剩余共11位,11位最大值就是2047,所以127-2047码位的字符用占两个字节。
三字节如下: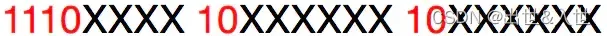
三字节
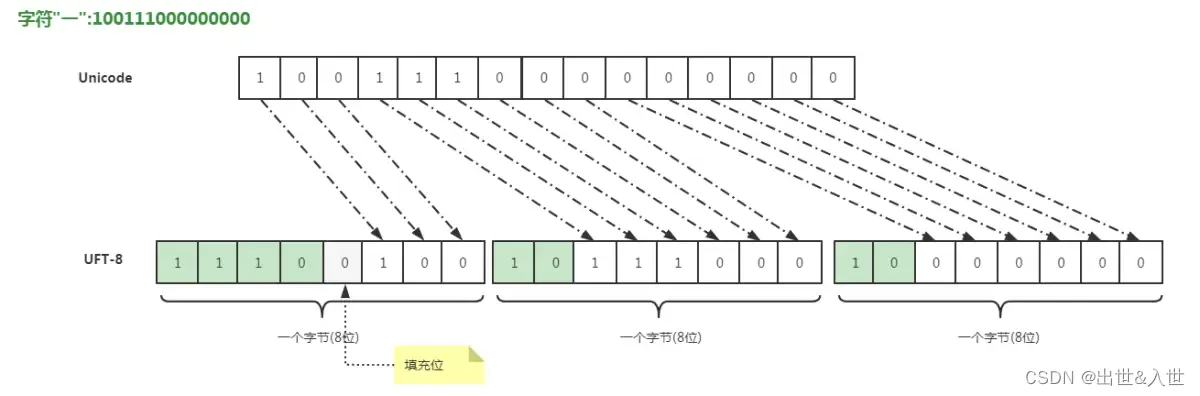
总剩余位16(最大65535),所2048-65535的字符占三个字节,汉字的Unicode在这个范围之中,所以现在懂为什么UTF-8的汉字占三个字节了吧~
六、GBK
因为讲了UTF-8,也不得不提一句GBK了,GBK是与Unicode共存的国产编码方式,全称是《汉字内码扩展规范》,它是我们自己国家定义的字符和二进制的逻辑映射(同一个汉字的Unicode和GBK的码位是不同的),而它的实现方式就比较固定了,用两个字节来代表一个字符
- Unicode是从数字和字符之间的逻辑映射的概念编码,实现方式一般使用UTF-8这种可变字节的实现方式来避免浪费,也可以使用UTF-16用固定两个字节代表一个字符,还有其它实现方式如UTF-32
- GBK编码系统可分为逻辑映射和实现方式两个层次,实现方式由于大部分是汉字所以固定两个字节代表一个字符,够用也不会有太多浪费
所以要说UTF-8和GBK到底谁好,也得分情况,如果大部分字符都是汉字,GBK两字节明显更节省空间(UTF-8因为要留控制位所以汉字需要三个字节),但如果大部分是英文显然UTF-8更节省,再有一点UTF-8实际存储的还是Unicode编码,全球都认,GBK属于国产编码,传送到国外还需要翻译,所以考虑国际化UTF-8还要更胜一筹