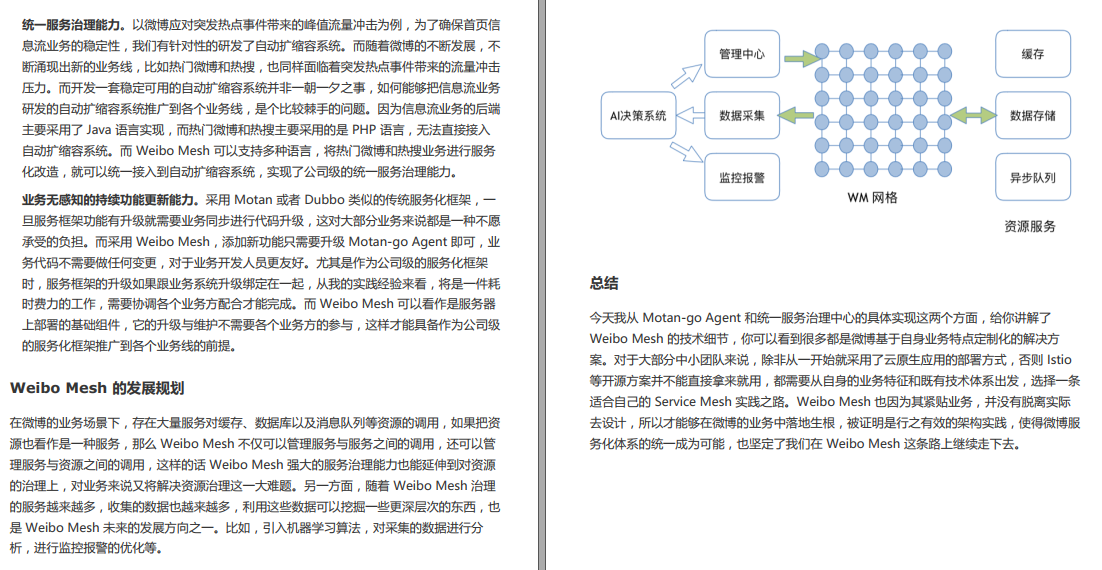
Java集合框架中的锁

今天我们继续来学习锁
字符串操作中的锁
- String是线程安全的,因为使用final修饰
- Stringbuilder 是线程不安全的,其方法没有使用synchronized修饰
- StringBuffer 是线程安全的,其方法使用synchronized修饰
List集合中的锁
- 不安全的
- ArrayList
- LinkedList
- HashSet
- TreeSet
- HashMap
- TreeMap
- 安全的
- Hashtable
- Vector
- Properties
- ConcurrentHashMap
- 但是Java也提供了很多线程安全的方式
- 比如在
java.util.concurrent包下提供的类都是线程安全的类 - 也可以使用
Collections类提供的方法
- 比如在
Collections类源码解析
// 先从一段代码开始
public class MyList {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
LinkedList<String> strings = new LinkedList<>();
List<String> list1 = Collections.synchronizedList(list);
}
}
// 点进去 Collections.synchronizedList(list); 方法 会跳到这个方法
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
// 因为我们使用的是 LinkedList 所以进入 SynchronizedList构造器
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
// 此次又调用了父类构造器
// 然后进入了 Collections的SynchronizedCollection静态内部类
// 然后我们惊奇的发现,其中的所有的方法都是使用 synchronized 修饰的
public class Collections {
// Suppresses default constructor, ensuring non-instantiability.
private Collections() {
}
static class SynchronizedCollection<E> implements Collection<E>, Serializable {
private static final long serialVersionUID = 3053995032091335093L;
final Collection<E> c; // Backing Collection
final Object mutex; // Object on which to synchronize
SynchronizedCollection(Collection<E> c) {
this.c = Objects.requireNonNull(c);
mutex = this;
}
SynchronizedCollection(Collection<E> c, Object mutex) {
this.c = Objects.requireNonNull(c);
this.mutex = Objects.requireNonNull(mutex);
}
public int size() {
synchronized (mutex) {return c.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return c.isEmpty();}
}
public boolean contains(Object o) {
synchronized (mutex) {return c.contains(o);}
}
public Object[] toArray() {
synchronized (mutex) {return c.toArray();}
}
public <T> T[] toArray(T[] a) {
synchronized (mutex) {return c.toArray(a);}
}
public Iterator<E> iterator() {
return c.iterator(); // Must be manually synched by user!
}
public boolean add(E e) {
synchronized (mutex) {return c.add(e);}
}
public boolean remove(Object o) {
synchronized (mutex) {return c.remove(o);}
}
public boolean containsAll(Collection<?> coll) {
synchronized (mutex) {return c.containsAll(coll);}
}
public boolean addAll(Collection<? extends E> coll) {
synchronized (mutex) {return c.addAll(coll);}
}
public boolean removeAll(Collection<?> coll) {
synchronized (mutex) {return c.removeAll(coll);}
}
public boolean retainAll(Collection<?> coll) {
synchronized (mutex) {return c.retainAll(coll);}
}
public void clear() {
synchronized (mutex) {c.clear();}
}
public String toString() {
synchronized (mutex) {return c.toString();}
}
// Override default methods in Collection
@Override
public void forEach(Consumer<? super E> consumer) {
synchronized (mutex) {c.forEach(consumer);}
}
@Override
public boolean removeIf(Predicate<? super E> filter) {
synchronized (mutex) {return c.removeIf(filter);}
}
@Override
public Spliterator<E> spliterator() {
return c.spliterator(); // Must be manually synched by user!
}
@Override
public Stream<E> stream() {
return c.stream(); // Must be manually synched by user!
}
@Override
public Stream<E> parallelStream() {
return c.parallelStream(); // Must be manually synched by user!
}
private void writeObject(ObjectOutputStream s) throws IOException {
synchronized (mutex) {s.defaultWriteObject();}
}
}
}
ConcurrentHashMap
- 在JDK1.7之前,HashMap的底层是数组+链表。同样的,ConcurrentHashMap的底层树结构是数组+链表,但是和HashMap不一样的是,ConcurrentHashMap的中存放数据是一段一段的。即由很多个Segment(段)组成的,每个Segment中都有着类似于数组+链表的结构
- 关于Segment
- ConcurrentHashMap由三个参数
- initalCapacity:初始化总容量,默认值为16
- loadFactor:加载因子,默认0.75
- concurrentLevel:并发级别,默认16
- 其中的并发级别控制了Segment的个数。在y一个ConcurrentHashMap创建后Segment的个数是不能变的,扩容过程是改变每个Segment的大小
- ConcurrentHashMap由三个参数
- 关于分段锁
- Segment继承了重入锁ReentrantLock,有了锁的的功能。每个锁控制的是一段,当每个Segment越来越大的时候,锁的粒度就越来越大了
- 分段锁的优势是保证造操作不同段map的时候进行锁的竞争和等待。这相当于直接对整个map同步synchronized只是有优势的
- 缺点在于分成很多段的时候会浪费很多的内存空间(不连续,碎片化),操作map的时候竞争一个分段锁概率狠小的时候,分段锁反而会造成更新等操作的长时间等待,分段锁的性能会下降
- Segment继承了重入锁ReentrantLock,有了锁的的功能。每个锁控制的是一段,当每个Segment越来越大的时候,锁的粒度就越来越大了
- JDK1.8的map实现
- JDK中的HashMap和ConcurrentHashMap。底层数据结构为数组+链表+红黑树。数组可以扩容,链表可以转化为红黑树(本篇文章不对红黑树做讲解,之前已经分析过, 请看
Java 集合框架 - HashMap 底层 红黑树深度解读.md)
- JDK中的HashMap和ConcurrentHashMap。底层数据结构为数组+链表+红黑树。数组可以扩容,链表可以转化为红黑树(本篇文章不对红黑树做讲解,之前已经分析过, 请看
- 新版的ConcurrentHashMap为什么不使用ReentrantLock而使用synchronized?
- 减少内存开销:如果使用ReenteantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要同步
- 内部优化:synchronized是JVM直接支持的,JVM能在运行时做出相应的优化措施:锁粗化、锁消除、锁自旋等
ConcurrentHashMap源码解析
// 此处只谈其分段所锁的实现 因为其本质就是HashMap
// 构造方法
// 无参构造方法
public ConcurrentHashMap() {
}
// map的初始容量为initialCapacity
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
// 始化参数是一个map
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
// 初始值,和负载因子
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
// 初始值,负载因子,和并发等级
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
// 核心分段 静态内部类
static class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
final float loadFactor;
Segment(float lf) { this.loadFactor = lf; }
}
// 如果指定的键已经不再与值相关联,尝试使用给定的映射函数计算其值并将其输入到该地图除非null 。
// 法调用原子方式执行,因此至多每键一旦施加的功能。 而运算正在进行
// 计算应短而简单,而且不能尝试更新此地图的任何其他映射这个地图
// 线程上的一些尝试更新操作可能被阻止。
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
if (key == null || mappingFunction == null)
throw new NullPointerException();
int h = spread(key.hashCode());
V val = null;
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {
Node<K,V> r = new ReservationNode<K,V>();
synchronized (r) {
if (casTabAt(tab, i, null, r)) {
binCount = 1;
Node<K,V> node = null;
try {
if ((val = mappingFunction.apply(key)) != null)
node = new Node<K,V>(h, key, val, null);
} finally {
setTabAt(tab, i, node);
}
}
}
if (binCount != 0)
break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
boolean added = false;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek; V ev;
if (e.hash == h &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
val = e.val;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
if ((val = mappingFunction.apply(key)) != null) {
added = true;
pred.next = new Node<K,V>(h, key, val, null);
}
break;
}
}
}
else if (f instanceof TreeBin) {
binCount = 2;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null &&
(p = r.findTreeNode(h, key, null)) != null)
val = p.val;
else if ((val = mappingFunction.apply(key)) != null) {
added = true;
t.putTreeVal(h, key, val);
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (!added)
return val;
break;
}
}
}
if (val != null)
addCount(1L, binCount);
return val;
}
// 如果指定键的值存在,尝试来计算给定的密钥和它的当前映射值的新映射。
// 法调用原子方式执行。 而运算正在进行,所以在计算应短而简单,
// 能尝试更新此地图的任何其他映射这个地图被其它线程上的一些尝试更新操作可能被阻止
public V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (key == null || remappingFunction == null)
throw new NullPointerException();
int h = spread(key.hashCode());
V val = null;
int delta = 0;
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & h)) == null)
break;
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f, pred = null;; ++binCount) {
K ek;
if (e.hash == h &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
val = remappingFunction.apply(key, e.val);
if (val != null)
e.val = val;
else {
delta = -1;
Node<K,V> en = e.next;
if (pred != null)
pred.next = en;
else
setTabAt(tab, i, en);
}
break;
}
pred = e;
if ((e = e.next) == null)
break;
}
}
else if (f instanceof TreeBin) {
binCount = 2;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null &&
(p = r.findTreeNode(h, key, null)) != null) {
val = remappingFunction.apply(key, p.val);
if (val != null)
p.val = val;
else {
delta = -1;
if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
}
if (binCount != 0)
break;
}
}
if (delta != 0)
addCount((long)delta, binCount);
return val;
}
// 尝试计算用于指定键和其当前映射的值的映射(或null ,如果没有当前映射)。
// 法调用原子方式执行。 而运算正在进行,所以在计算应短而简单,
// 能尝试更新此地图的任何其他映射这个地图被其它线程上的一些尝试更新操作可能被阻止。
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (key == null || remappingFunction == null)
throw new NullPointerException();
int h = spread(key.hashCode());
V val = null;
int delta = 0;
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {
Node<K,V> r = new ReservationNode<K,V>();
synchronized (r) {
if (casTabAt(tab, i, null, r)) {
binCount = 1;
Node<K,V> node = null;
try {
if ((val = remappingFunction.apply(key, null)) != null) {
delta = 1;
node = new Node<K,V>(h, key, val, null);
}
} finally {
setTabAt(tab, i, node);
}
}
}
if (binCount != 0)
break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f, pred = null;; ++binCount) {
K ek;
if (e.hash == h &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
val = remappingFunction.apply(key, e.val);
if (val != null)
e.val = val;
else {
delta = -1;
Node<K,V> en = e.next;
if (pred != null)
pred.next = en;
else
setTabAt(tab, i, en);
}
break;
}
pred = e;
if ((e = e.next) == null) {
val = remappingFunction.apply(key, null);
if (val != null) {
delta = 1;
pred.next =
new Node<K,V>(h, key, val, null);
}
break;
}
}
}
else if (f instanceof TreeBin) {
binCount = 1;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null)
p = r.findTreeNode(h, key, null);
else
p = null;
V pv = (p == null) ? null : p.val;
val = remappingFunction.apply(key, pv);
if (val != null) {
if (p != null)
p.val = val;
else {
delta = 1;
t.putTreeVal(h, key, val);
}
}
else if (p != null) {
delta = -1;
if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
break;
}
}
}
if (delta != 0)
addCount((long)delta, binCount);
return val;
}
// 如果指定键已经不再与一个(非空)值相关联,它与给定值关联。
// 替换指定重映射函数的结果,或移除如果该值为null 。 整个方法调用原子方式执行。
// 正在进行,所以在计算应短而简单,而且不能尝试更新此地图的任何其他映射这个地图
// 程上的一些尝试更新操作可能被阻止。
public V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
if (key == null || value == null || remappingFunction == null)
throw new NullPointerException();
int h = spread(key.hashCode());
V val = null;
int delta = 0;
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(h, key, value, null))) {
delta = 1;
val = value;
break;
}
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f, pred = null;; ++binCount) {
K ek;
if (e.hash == h &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
val = remappingFunction.apply(e.val, value);
if (val != null)
e.val = val;
else {
delta = -1;
Node<K,V> en = e.next;
if (pred != null)
pred.next = en;
else
setTabAt(tab, i, en);
}
break;
}
pred = e;
if ((e = e.next) == null) {
delta = 1;
val = value;
pred.next =
new Node<K,V>(h, key, val, null);
break;
}
}
}
else if (f instanceof TreeBin) {
binCount = 2;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r = t.root;
TreeNode<K,V> p = (r == null) ? null :
r.findTreeNode(h, key, null);
val = (p == null) ? value :
remappingFunction.apply(p.val, value);
if (val != null) {
if (p != null)
p.val = val;
else {
delta = 1;
t.putTreeVal(h, key, val);
}
}
else if (p != null) {
delta = -1;
if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
break;
}
}
}
if (delta != 0)
addCount((long)delta, binCount);
return val;
}
// 移动或者复制每个仓库的节点
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
// 在替换所有斌链接节点在给定的索引,除非表是太小了,在这种情况下,调整大小来代替。
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
- ConcurrentHashMap取消了segment分段锁,而采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
- synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
- 推荐文章
- https://www.jianshu.com/p/d10256f0ebea
- http://www.jasongj.com/java/concurrenthashmap/
- https://www.itqiankun.com/article/concurrenthashmap-principle
- http://www.codeceo.com/article/java-hashmap-concurrenthashmap.html
- https://www.cnblogs.com/shan1393/p/9020564.html
- Java并发包concurrent——ConcurrentHashMap
- Java8 ConcurrentHashMap详解
- 一些ConcurrentHashMap的问题
- 扩容过程中,读访问能够访问到数据,怎么实现的?
- volatile关键字修饰数据,保证了内存一致性
- 扩容机制中,写访问如何处理
- 假设指定桶为形成红黑树,且当前红黑树正在自平衡,那此时的读线程是被阻塞等待还是有其他的方案?详细说一说
- JDK8中统计当前散列表的元素个数是如何实现的?为什么没有使用AtomicLong?
- 简单说一下,LastRun机制
- 扩容过程中,读访问能够访问到数据,怎么实现的?