SQL零基础入门学习(SQL约束)
SQL CREATE INDEX 语句
CREATE INDEX 语句用于在表中创建索引。
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
索引
您可以在表中创建索引,以便更加快速高效地查询数据。
用户无法看到索引,它们只能被用来加速搜索/查询。
注释:更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。
SQL CREATE INDEX 语法
在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name
ON table_name (column_name)
SQL CREATE UNIQUE INDEX 语法
在表上创建一个唯一的索引。不允许使用重复的值:唯一的索引意味着两个行不能拥有相同的索引值。Creates a unique index on a table. Duplicate values are not allowed:
CREATE UNIQUE INDEX index_name
ON table_name (column_name)
注释:用于创建索引的语法在不同的数据库中不一样。因此,检查您的数据库中创建索引的语法。
CREATE INDEX 实例
下面的 SQL 语句在 “Persons” 表的 “LastName” 列上创建一个名为 “PIndex” 的索引:
CREATE INDEX PIndex
ON Persons (LastName)
如果您希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开:
CREATE INDEX PIndex
ON Persons (LastName, FirstName)
SQL 撤销索引、撤销表以及撤销数据库
通过使用 DROP 语句,可以轻松地删除索引、表和数据库。
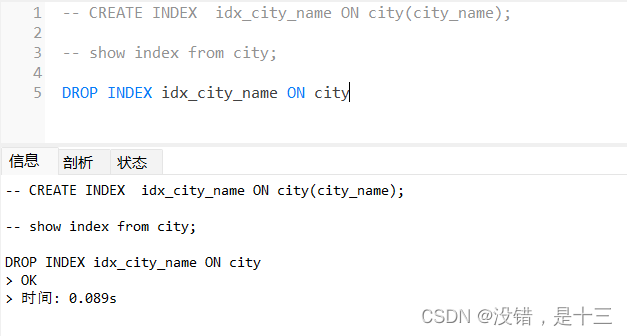
DROP INDEX 语句
DROP INDEX 语句用于删除表中的索引。
用于 MS Access 的 DROP INDEX 语法:
DROP INDEX index_name ON table_name
用于 MS SQL Server 的 DROP INDEX 语法:
DROP INDEX table_name.index_name
用于 DB2/Oracle 的 DROP INDEX 语法:
DROP INDEX index_name
用于 MySQL 的 DROP INDEX 语法:
ALTER TABLE table_name DROP INDEX index_name
DROP TABLE 语句
DROP TABLE 语句用于删除表。
DROP TABLE table_name
DROP DATABASE 语句
DROP DATABASE 语句用于删除数据库。
DROP DATABASE database_name
TRUNCATE TABLE 语句
如果我们仅仅需要删除表内的数据,但并不删除表本身,那么我们该如何做呢?
请使用 TRUNCATE TABLE 语句:
TRUNCATE TABLE table_name
SQL ALTER TABLE 语句
ALTER TABLE 语句用于在已有的表中添加、删除或修改列。
SQL ALTER TABLE 语法
如需在表中添加列,请使用下面的语法:
ALTER TABLE table_name
ADD column_name datatype
如需删除表中的列,请使用下面的语法(请注意,某些数据库系统不允许这种在数据库表中删除列的方式):
ALTER TABLE table_name
DROP COLUMN column_name
要改变表中列的数据类型,请使用下面的语法:
SQL Server / MS Access:
ALTER TABLE table_name
ALTER COLUMN column_name datatype
My SQL / Oracle:
ALTER TABLE table_name
MODIFY COLUMN column_name datatype
Oracle 10G 之后版本:
ALTER TABLE table_name
MODIFY column_name datatype;
SQL ALTER TABLE 实例
请看 “Persons” 表:

现在,我们想在 “Persons” 表中添加一个名为 “DateOfBirth” 的列。
我们使用下面的 SQL 语句:
ALTER TABLE Persons
ADD DateOfBirth date
请注意,新列 “DateOfBirth” 的类型是 date,可以存放日期。数据类型规定列中可以存放的数据的类型。
现在,“Persons” 表将如下所示:

改变数据类型实例
现在,我们想要改变 “Persons” 表中 “DateOfBirth” 列的数据类型。
我们使用下面的 SQL 语句:
ALTER TABLE Persons
ALTER COLUMN DateOfBirth year
请注意,现在 “DateOfBirth” 列的类型是 year,可以存放 2 位或 4 位格式的年份。
DROP COLUMN 实例
接下来,我们想要删除 “Person” 表中的 “DateOfBirth” 列。
我们使用下面的 SQL 语句:
ALTER TABLE Persons
DROP COLUMN DateOfBirth
现在,“Persons” 表将如下所示:

SQL AUTO INCREMENT 字段
Auto-increment 会在新记录插入表中时生成一个唯一的数字。
AUTO INCREMENT 字段
我们通常希望在每次插入新记录时,自动地创建主键字段的值。
我们可以在表中创建一个 auto-increment 字段。
用于 MySQL 的语法
下面的 SQL 语句把 “Persons” 表中的 “ID” 列定义为 auto-increment 主键字段:
CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (ID)
)
MySQL 使用 AUTO_INCREMENT 关键字来执行 auto-increment 任务。
默认地,AUTO_INCREMENT 的开始值是 1,每条新记录递增 1。
要让 AUTO_INCREMENT 序列以其他的值起始,请使用下面的 SQL 语法:
ALTER TABLE Persons AUTO_INCREMENT=100
要在 “Persons” 表中插入新记录,我们不必为 “ID” 列规定值(会自动添加一个唯一的值):
INSERT INTO Persons (FirstName,LastName)
VALUES ('Lars','Monsen')
上面的 SQL 语句会在 “Persons” 表中插入一条新记录。“ID” 列会被赋予一个唯一的值。“FirstName” 列会被设置为 “Lars”,“LastName” 列会被设置为 “Monsen”。
用于 SQL Server 的语法
下面的 SQL 语句把 “Persons” 表中的 “ID” 列定义为 auto-increment 主键字段:
CREATE TABLE Persons
(
ID int IDENTITY(1,1) PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
MS SQL Server 使用 IDENTITY 关键字来执行 auto-increment 任务。
在上面的实例中,IDENTITY 的开始值是 1,每条新记录递增 1。
提示:要规定 “ID” 列以 10 起始且递增 5,请把 identity 改为 IDENTITY(10,5)。
要在 “Persons” 表中插入新记录,我们不必为 “ID” 列规定值(会自动添加一个唯一的值):
INSERT INTO Persons (FirstName,LastName)
VALUES ('Lars','Monsen')
上面的 SQL 语句会在 “Persons” 表中插入一条新记录。“ID” 列会被赋予一个唯一的值。“FirstName” 列会被设置为 “Lars”,“LastName” 列会被设置为 “Monsen”。
用于 Access 的语法
下面的 SQL 语句把 “Persons” 表中的 “ID” 列定义为 auto-increment 主键字段:
CREATE TABLE Persons
(
ID Integer PRIMARY KEY AUTOINCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
MS Access 使用 AUTOINCREMENT 关键字来执行 auto-increment 任务。
默认地,AUTOINCREMENT 的开始值是 1,每条新记录递增 1。
提示:要规定 “ID” 列以 10 起始且递增 5,请把 autoincrement 改为 AUTOINCREMENT(10,5)。
要在 “Persons” 表中插入新记录,我们不必为 “ID” 列规定值(会自动添加一个唯一的值):
INSERT INTO Persons (FirstName,LastName)
VALUES ('Lars','Monsen')
上面的 SQL 语句会在 “Persons” 表中插入一条新记录。“ID” 列会被赋予一个唯一的值。“FirstName” 列会被设置为 “Lars”,“LastName” 列会被设置为 “Monsen”。
用于 Oracle 的语法
在 Oracle 中,代码稍微复杂一点。
您必须通过 sequence 对象(该对象生成数字序列)创建 auto-increment 字段。
请使用下面的 CREATE SEQUENCE 语法:
CREATE SEQUENCE seq_person
MINVALUE 1
START WITH 1
INCREMENT BY 1
CACHE 10
上面的代码创建一个名为 seq_person 的 sequence 对象,它以 1 起始且以 1 递增。该对象缓存 10 个值以提高性能。cache 选项规定了为了提高访问速度要存储多少个序列值。
要在 “Persons” 表中插入新记录,我们必须使用 nextval 函数(该函数从 seq_person 序列中取回下一个值):
INSERT INTO Persons (ID,FirstName,LastName)
VALUES (seq_person.nextval,'Lars','Monsen')
上面的 SQL 语句会在 “Persons” 表中插入一条新记录。“ID” 列会被赋值为来自 seq_person 序列的下一个数字。"FirstName"列 会被设置为 “Lars”,“LastName” 列会被设置为 “Monsen”。