ShardingSphere的介绍
ShardingSphere是一款起源于当当网内部的应用框架。2015年在当当网内部诞 生,最初就叫ShardingJDBC。2016年的时候,由其中一个主要的开发人员张亮, 带入到京东数科,组件团队继续开发。在国内历经了当当网、电信翼支付、京东数 科等多家大型互联网企业的考验,在2017年开始开源。并逐渐由原本只关注于关系 型数据库增强工具的ShardingJDBC升级成为一整套以数据分片为基础的数据生态 圈,更名为ShardingSphere。到2020年4月,已经成为了Apache软件基金会的顶 级项目。 ShardingSphere包含三个重要的产品,ShardingJDBC、ShardingProxy和 ShardingSidecar。其中sidecar是针对service mesh定位的一个分库分表插件,目 前在规划中。而我们今天学习的重点是ShardingSphere的JDBC这个组 件。 其中,ShardingJDBC是用来做客户端分库分表的产品,而ShardingProxy是用 来做服务端分库分表的产品。这两者定位有什么区别呢?我们看下官方资料中给出 的两个重要的图:
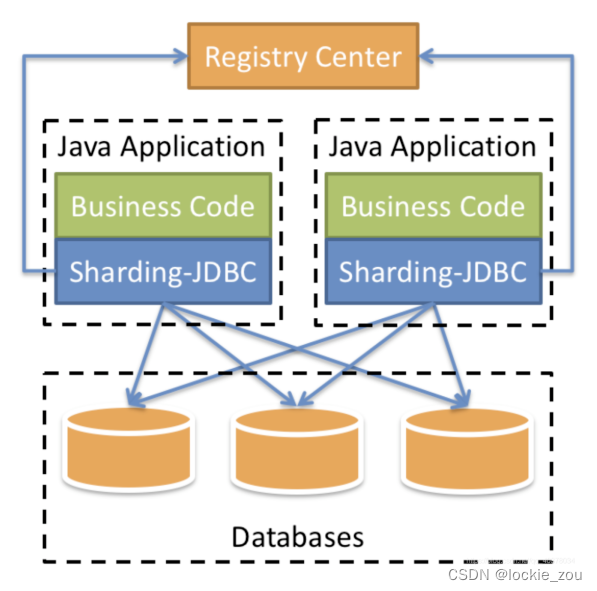
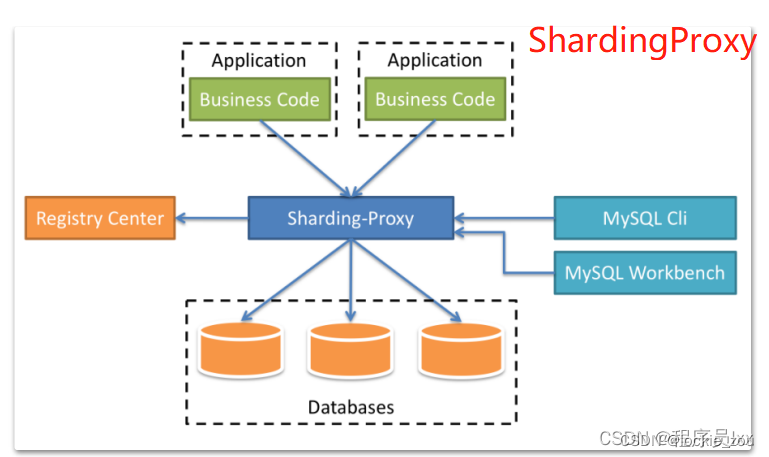

1核心概念
分库分表
分库,显而易见,就是一个数据库分成多个数据库,部署到不同机器。
分表,就是一个数据库表分成多个表。
分片
一般在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,
数据分片将原本一张数据量较大的表例如 t_order 拆分生成数个表结构完全一致的小数据量表 t_order_0、t_order_1、···、t_order_n,每张表只存储原大表中的一部分数据,当执行一条SQL时会通过 分库策略、分片策略 将数据分散到不同的数据库、表内。
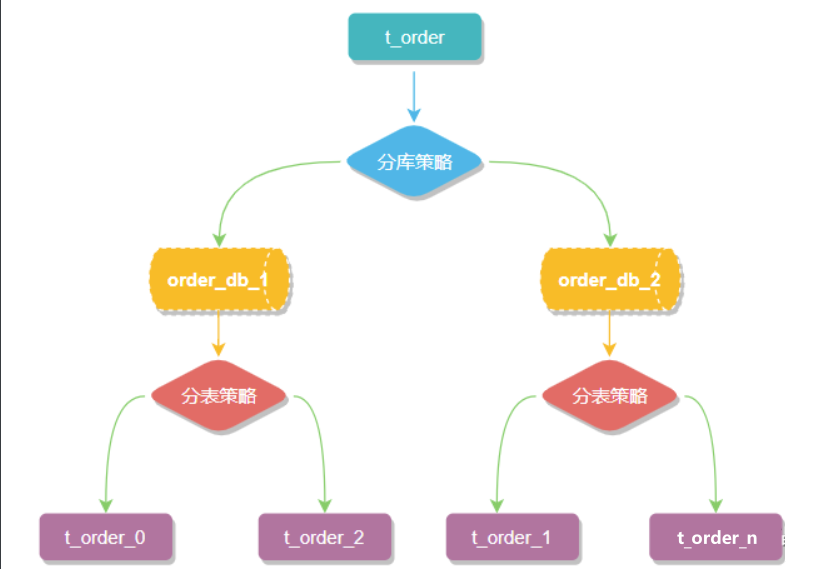
数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,例如上图中 order_db_1.t_order_0、order_db_2.t_order_1 就表示一个数据节点。
逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。
比如将订单表 t_order 拆分成 t_order_0 ··· t_order_9 等 10张表。
此时会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但在代码中写 SQL 依然按 t_order 来写。此时 t_order 就是这些拆分表的逻辑表。
真实表
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
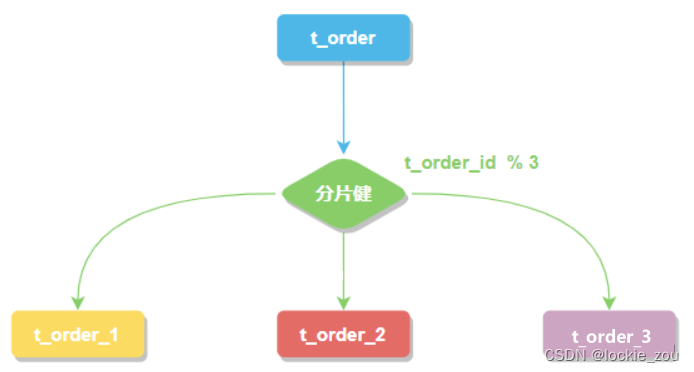
分片键
用于分片的数据库字段。将 t_order 表分片以后,当执行一条SQL时,通过对字段 order_id 取模的方式来决定,这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是 t_order 表的分片健。
实战
以下演示分表,将逻辑订单表 t_order_info 根据订单id字段拆分成3张真实表(t_order_info_0,t_order_info_1,t_order_info_2)
1.创建订单表
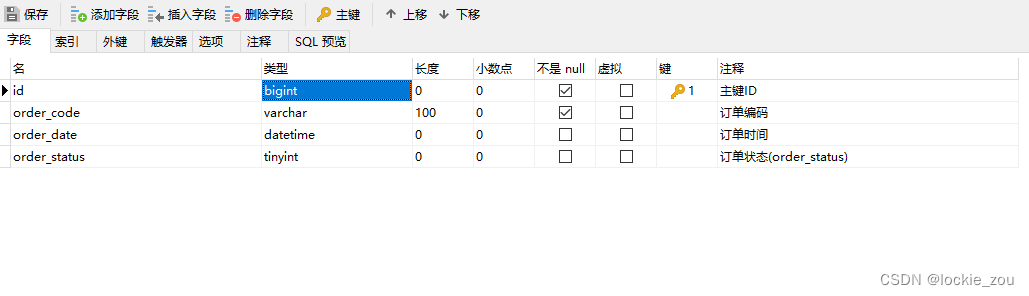
创建好了同时复制另2张表,总共3张表。
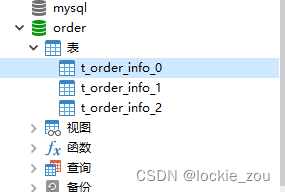
2. 创建springboot微服务项目
新建一个微服务项目,引入sharding包
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.2</version>
</dependency>增加配置
# 配置信息存储方式:内存
spring.shardingsphere.mode.type=Memory
# 显示运行的sql
spring.shardingsphere.props.sql.show=true
# 数据源配置
spring.shardingsphere.datasource.names=ds0
# 数据源0ds0的配置
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://127.0.0.1:3306/order?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowMultiQueries=true&serverTimezone=Asia/Shanghai&useAffectedRows=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
# 表t_order_info
# 分表规则(由于只分表, 不分库, 所以分库直接采用默认的即可)
# 行内表达式分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.order-inline.type=INLINE
# id列的值%3,等于1就选t_order_info_0表,等于2就选t_order_info_1表,等于3就选t_order_info_2表
spring.shardingsphere.rules.sharding.sharding-algorithms.order-inline.props.algorithm-expression=t_order_info_$->{id % 3}
# 真实表分布,order库的t_order_info_0,t_order_info_1,t_order_info_2表
spring.shardingsphere.rules.sharding.tables.t_order_info.actual-data-nodes=ds0.t_order_info_$->{0..2}
# 以id作为算法的数据值
spring.shardingsphere.rules.sharding.tables.t_order_info.table-strategy.standard.sharding-column=id
# 指定分片算法名称(自定义的名称)
spring.shardingsphere.rules.sharding.tables.t_order_info.table-strategy.standard.sharding-algorithm-name=order-inline3.生成代码
使用代码生成器生成代码,订单实体OrderInfo如下,其中自己创建了一个@Sharding 注解用来标识分片键,这里根据id值来分表。
@Getter
@Setter
@ToString
@NoArgsConstructor
public class OrderInfo {
/** 主键ID**/
@Sharding
@JsonFormat(shape = Shape.STRING)
private Long id;
/** 订单编码**/
private String orderCode;
/** 订单时间**/
private Date orderDate;
/** 订单状态**/
private Integer orderStatus;
}@Sharding 注解内容如下
/**
* 数据分片
*/
@Target({ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Sharding {
/**
* 要识别的信息
*/
String name() default "";
}OrderInfoMapper.xml 如下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.cdw.modules.order.mapper.OrderInfoMapper">
<resultMap id="OrderInfoMap" type="OrderInfo">
<id column="id" property="id"/>
</resultMap>
<sql id="baseColumns">
o.id,
o.order_code,
o.order_date,
o.stop_time,
o.order_status
</sql>
<!-- 根据主键ID查询 -->
<select id="findById" resultMap="OrderInfoMap">
SELECT
<include refid="baseColumns" />
FROM t_order_info o WHERE o.id = #{id}
</select>
<!-- 列表 -->
<select id="findList" resultMap="OrderInfoMap">
SELECT
<include refid="baseColumns" />
FROM t_order_info o
<if test="id!=null">AND o.id = #{id}</if>
<if test="orderCode!=null and orderCode!=''">AND o.order_code LIKE concat('%', #{orderCode}, '%')</if>
<if test="orderDate!=null">AND o.order_date = #{orderDate}</if>
<if test="orderStatus!=null">AND o.order_status = #{orderStatus}</if>
</select>
<!-- 批量插入记录 -->
<insert id="insertBatch" useGeneratedKeys="true" keyProperty="id" parameterType="OrderInfo">
INSERT INTO t_order_info (
id,
order_code,
order_date,
order_status
) VALUES
<foreach item="emp" separator="," collection="list">
(
#{emp.id},
#{emp.orderCode},
#{emp.orderDate},
#{emp.orderStatus}
)
</foreach>
</insert>
<!-- 批量更新记录 -->
<update id="updateBatch">
<foreach item="emp" separator=";" collection="list">
UPDATE t_order_info
<set>
<if test="emp.orderCode!=null and emp.orderCode!=''">order_code = #{emp.orderCode},</if>
<if test="emp.orderDate!=null">order_date = #{emp.orderDate},</if>
<if test="emp.orderStatus!=null">order_status = #{emp.orderStatus},</if>
</set>
WHERE id = #{emp.id}
</foreach>
</update>
<!-- 批量删除记录 -->
<delete id="delByIds" parameterType = "java.util.List">
DELETE FROM t_order_info WHERE
id in
<foreach collection="list" item="item" open="(" separator="," close=")" >
#{item}
</foreach>
</delete>
</mapper>
OrderInfoService 代码
/**
* 获取基础订单信息分页列表
*
* @author lockie
* @date: 2022-8-10 09:20
* @param: param
*/
public PageInfo<OrderInfoVO> getOrderInfoPage(OrderInfo param) {
param.enablePage();
return toPageInfo(orderInfoMapper.findList(param), OrderInfoVO.class);
}
/** 查询列表**/
public List<OrderInfoVO> getOrderInfoList(OrderInfo param) {
return copyToList(orderInfoMapper.findList(param), OrderInfoVO.class);
}
/** 根据ID获取详情**/
public OrderInfoVO getOrderInfoById(Long id) {
return orderInfoMapper.findById(id);
}
/** 新增**/
public Integer insertOrderInfo(OrderInfo orderInfo) {
return insertBatchOrderInfo(Collections.singletonList(orderInfo));
}
/** 批量新增**/
public Integer insertBatchOrderInfo(List<OrderInfo> orderInfoList) {
if (CollectionUtils.isEmpty(orderInfoList)) {
return null;
}
try {
List<List<OrderInfo>> data = ShardingUtil.shardingData(shardingCount.getShardingTableCount(), orderInfoList);
data.forEach(s -> {
log.info("orderInfoMapper.insertBatchOrderInfo:[{}]", JsonUtil.toJson(s));
orderInfoMapper.insertBatch(s);
});
} catch (Exception e) {
throw new RuntimeException(e);
}
return 1;
}其中新增操作时重要的就是新增到哪个表去,ShardingUtil就是根据id%3 取余然后找到对应的表
/**
* 分表工具类
* 批量操作ShardingSphere本就不支持, 因此封装这个工具用于处理该问题
* 该工具仅仅支持取模模式
* @author lockie
* @date: 2022-7-30 19:09
*/
@Slf4j
public class ShardingUtil {
private static String fieldName = "";
private static PropertyDescriptor sourceProperty = null;
/**
* 根据数据大小以及分片数量得到初始化分片桶
*
* @author lockie
*/
private static <T> List<List<T>> init(int listCount) {
List<List<T>> retList = new ArrayList<>(listCount);
// 默认先占位
for (int i = 0; i < listCount; i++) {
retList.add(new ArrayList<>());
}
return retList;
}
/**
* 数据分片
*
* @author lockie
* @date: 2022-9-6 14:37
*/
public static <T> List<List<T>> shardingData(int tableCount, List<T> data) throws RuntimeException, InvocationTargetException, IllegalAccessException {
if (tableCount == 0) {
throw new RuntimeException("tableCount 不能为0!");
}
List<List<T>> retData = init(tableCount);
// 如果是1的话, 则表示没有分表, 直接封装数据返回即可
if (tableCount == 1) {
retData.set(0, data);
retData.removeIf(CollectionUtils::isEmpty);
log.info("处理 retData 返回值3{}", JsonUtil.toJson(retData));
return retData;
}
// 基础类型标记
boolean isBasicType = false;
// 获取类
Class<?> clazz = data.get(0).getClass();
// 判断是否为基本类型的包装类
if (clazz.getSimpleName().equals("Long") || clazz.getSimpleName().equals("Integer")) {
isBasicType = true;
}
// 标记是否有分表操作
boolean hasAnnotation = false;
// 获取类型
for (T t : data) {
Object value = null;
if (!isBasicType) {
// 检验字段名称是否有值, 没有的话循环一遍属性查找
if (StringUtils.isEmpty(fieldName)) {
Class<?> tClass = t.getClass();
List<Field> fields = new ArrayList<>();
while (tClass != null) {
fields.addAll(Arrays.asList(tClass.getDeclaredFields()));
tClass = tClass.getSuperclass();
}
for (Field field : fields) {
Sharding sharding = field.getAnnotation(Sharding.class);
if (null == sharding) {
continue;
}
fieldName = field.getName();
hasAnnotation = true;
break;
}
}
// 如果没标注分表注解的话, 则默认将原始数据封装好丢出去
if (!hasAnnotation) {
retData.add(data);
retData.removeIf(CollectionUtils::isEmpty);
log.info("处理 retData 返回值2{}", JsonUtil.toJson(retData));
return retData;
}
// 根据字段名称获取这个属性
sourceProperty = BeanUtils.getPropertyDescriptor(clazz, fieldName);
value = sourceProperty.getReadMethod().invoke(t);
} else {
value = t;
}
// 取模操作
int index = (int) (Long.parseLong(String.valueOf(value)) % tableCount);
List<T> valueList = retData.get(index);
// 添加到对应的List中
valueList.add(t);
}
// 重置状态
sourceProperty = null;
fieldName = "";
// 删除空List
retData.removeIf(CollectionUtils::isEmpty);
log.info("处理 retData 返回值1{}", JsonUtil.toJson(retData));
return retData;
}
}