“你在字节跳动哪个业务?”
“古籍数字化。把《论语》《左传》《道德经》这些古籍变成电子版,让大家都能免费看。”
没错,除了你熟悉的那些 App,字节跳动还在做一些小众而特别的事情,古籍数字化就是其中之一。
在字节跳动与北京大学的合作之下,识典古籍官网已经上线了 685 部古籍,包括双方参与设计与研发的《永乐大典》高清影像数据库,你可以登录官网或者在今日头条古籍频道看到它们。
可不要以为古籍数字化只是扫描一个电子版放网上,它对技术能力要求很高,比如:
1.古籍的排版并非从左到右、行行清晰,这样的文本,怎么提取出来?
2.茴香豆的「茴」有四种写法,我怎么知道用户要的是哪一种?
3.我的文言文只有高中语文水平,要怎么做人名、地名等命名实体识别?
我们找字节跳动的程序员们聊了聊,发现了一些有趣的解决方案。来看看他们在做的究竟是怎样的工作吧。

Q1:你为什么会对古籍感兴趣?
我最早做的是直播业务,后来发现古籍项目缺少服务端研发,我就过来了。
巧的是,我的女朋友是中文系毕业的,学过一些古籍研究的课程。她的同学们做研究的时候经常抱怨没有好的古籍阅读平台,所以当她得知我要做古籍项目的时候还挺开心的。
后来上线之后也发现,这个产品确实可以帮到很多学生和古籍研究人员。
Q2:这么说你之前是门外汉,那要怎么搞懂古籍呢?
这个项目是跟北大合作的,所以北大的老师会给我们讲古籍相关的知识。
别人开会讨论 GMV、研究 DAU;我们开会张口《永乐大典》,闭口《孙子兵法》。虽然都是研发,但画风完全不一样。
而且让我非常惊讶的是,北大的老师虽然是研究古籍的,但是很懂计算机,甚至还会写 Python 来进行一些数据处理。
Q3:古籍数字化这个工作难在哪?
作为古籍数字化业务的研发,我们业务的复杂度很高。比如古籍的格式里,大字是正文,小字是注解,单独一列的大字是标题,比现代人写的文章复杂多了:

因此,为了把这些复杂的结构区分开,我们定义了一套古籍的元数据协议。
最特殊的是,古籍里有一些字是现代汉语里没有的——它不是繁体字或者异体字。比如你看《永乐大典卷之三千五百十八【九真】》的开头:

右侧这些类似「门」字,或者像横折钩笔画一样的字,现代汉语字库里压根没有,我们就用图片的形式嵌入到文本中:

这样你就会看到,文本中不仅有正常的字,还有第二行黄色的「注朝门」三个字的注解,还有那些黄底的图片,我们以 Unicode 特殊字符的形式存储下来。
这样,我们就把一页一页的古籍变成了结构化的数据,可以满足行业通用的 TEI(Text Encoding Initiative)元数据标准,能区分章节、标题、内文,方便搜索、翻看,而且还能进一步编辑整理。
现在,借助飞书文档提供的 SDK,我们已经为合作方北大的专家学者们提供了古籍整理平台,便于精校现有古籍、增加新的书目。

Q1:OCR 是怎么识别出文字的?
我们一般先通过深度学习中的目标检测技术,通过计算机视觉确定图片中的主体在哪里,找到文字的位置。

然后再识别文字的内容。

这就类似于一个分类问题,算法自动判断这是一个什么字。
Q2:这么说它是很成熟的技术了?在古籍场景上会有什么难点吗?
古籍要复杂一些。
一般的现代印刷体,我们只要找到一行一行的文字,就可以识别了。但古籍不同,虽然大部分古籍都是竖着读的,但也有横着读的,所以识别出每个字之后,要推理出它的阅读顺序。
你看,大部分情况下每个字旁边,上、下、左、右、左上、左下、右上、右下一圈一共有 8 个字。

但识别出来之后,计算机只能知道某个特定位置上是某个字,并不知道这些零散的字的阅读顺序,它不知道应该以怎样的顺序将这些单个字符排列成一段文本。

因此,每当找到一个字,就需要把它和周围的 8 个左右的字分别连接在一起。

算法根据语料自动判断每一组连接是否符合阅读顺序,符合便是 1,不符合便是 0,这样,就可以推导出识别出的文字的阅读顺序(下图红色箭头)。
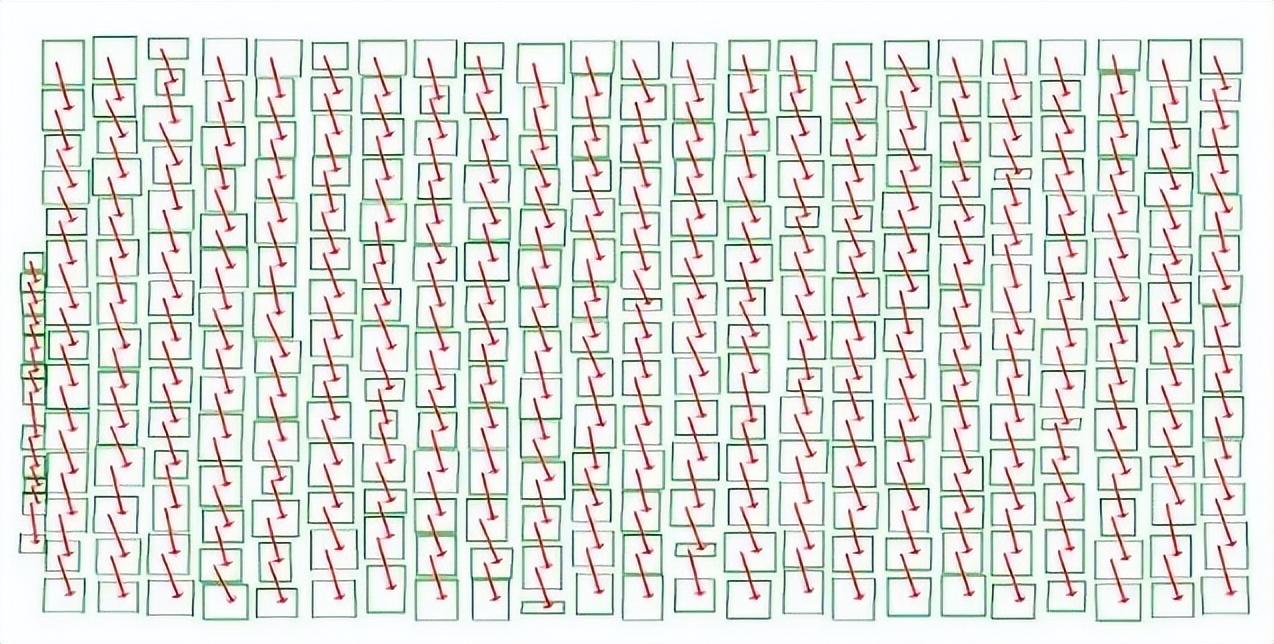
这样才可以找出阅读顺序,把它变为数字化的文本。
上面那些保存完好的规整印刷古籍要容易一些,还有一些非常困难的,比如下面的佛经:

它是手写体而非整整齐齐的印刷体,排版也比较随意,关键还有很多褶皱和残缺,保存状况并不好,亟待整理。
面对这样的古籍,模型可能没见过此类特殊排版。我们的方法是:如果某种版式很常见、需要用到 AI 来自动化,那我们就多用一些数据去训练;实在没有数据,那就还是自己用文字渲染或者 GAN 模型来生成一些「仿制古籍」去训练 AI。
Q3:你们需要用到很多 AI 技术,有那么多古籍数据可以让你们去训练 AI 吗?
会有这个问题。有些生僻字出现的太少,我们找不到真正的古籍,只好让 GAN 模型自己写一个生僻字来当做训练集。

另一种比较聪明的方式是,如果这个生僻字刚好可以根据偏旁部首拆开,比如「毈」字可以拆成「卵」字和「段」字,那就拆开再识别好啦。
Q4:除了古籍,字节跳动还有哪些业务场景会用到 OCR?
很多啊,比如当你在抖音搜索视频的时候,视频里并没有几个字,那搜索引擎是怎么把这些视频找出来的呢?因为我们用 OCR 提取了创作者给视频加的字幕。
虽然 OCR 是一项历史悠久的技术,但也是需要不断创新的。想要把一种技术产品化,不光要把文字识别出来,还要做信息抽取。视觉信息+语义,变成一类多模态的技术。

Q1:来讲一讲古籍的 NLP 怎么做吧?
不管是给古文分词、分段、加标点,还是识别文中的人名、地名、书名、官职名这些实体,都是做序列标注。文本就是一个序列,首先需要模型自动标注文本中的每一个字,就是给它打标签。
比如给古文加标点符号。就像人类完成这项工作一样,模型会判断这个字的后面是否要加标点。如果应该加标点,再判断这里应该是逗号、句号还是问号,模型会根据这个字上下文的语义来去做判断。
识别人名地名则是命名实体识别 ,这是一类典型的 NLP 任务。模型会给每个字两个标签:
一、判断它是不是人名书名这类实体词之内的文字,并且处于词语的哪个位置?
二、判断它是人名,还是地名、书名、官职名。
上面这些过程是整体完成的,主要依赖编码,把文字编码成词嵌入,来计算每个字属于不同标签的概率。
当然,在古籍上,我们训练编码器就需要用一些标注好的古文作为语料。我们的合作方北大的老师就给了我们很多这方面的资料,通过清洗后获得的数据可以帮助我们训练编码器。
其实在 NLP 任务中,古文和现代文的差距,就像中文和英文的差距一样大,所以会用到一些跨语言的预训练模型,用古文语料在一个中文预训练模型上再进行训练。而且我们内部还有很多现成的工具,可以帮助我们更便捷的完成 NLP 任务。
Q2:除了语料库不一样,古文 NLP 还有什么难点么?
其实这项工作就像教一个模型学会古文,给它数据之后,结合一些工具方法,让模型自己学会给古文分词、加标点、识别里面重要的名词。
模型学会之后,当然就要让它「写作业」,来判断它到底学会了没有。
然后问题就来了:我不是学汉语言的,不会给它「批作业」,很判断它到底学得怎么样。
对我来说,读古文比读英文更难一些,只能靠着中学语文学到的那点文言文知识来判断。如果我拿不准,就去和其他句读工具的结果对比一下,实在不同的话就自己去搜索呗。不得不说,这确实帮我巩固了中学语文。
Q3:在字节跳动,NLP 技术还会用在哪些场景?
其实我们做 NLP 的方向很多,除了我在做序列标注,还有同学会研究知识图谱、机器翻译之类的技术。
具体场景也很多,比如会做广告文案的自动生成,飞书会议中的自动翻译,自动识别电商商品的品牌等,这些场景的准确率也都比较高了。
我们也在支持火山引擎,用 NLP 技术满足各行各业客户的需求。

Q1:古籍搜索和其他搜索有什么不同?
古籍搜索主要和其他搜索有两点不同:
第一个是分词的不同,我们定制了一个古籍的分词器,用于处理古文中句读的问题;
第二个是排序的问题,由于古文分段都是由后人手工分段,段落长度参差不齐,长度差别可达到几千倍,对于搜索结果的排序有着许多意料之外的影响。公司内部的搜索中台有很多分词、纠错、返回排序之类的功能,可以直接调用,我们在此之上定制了一些古文的排序策略,对排序结果有一定的优化。
Q2:用的是哪种分词方式呢?
分词是前面负责 NLP 的同学用 BERT 模型完成的,训练它的语料库是一个叫「史藏」的数据集,模型学完史藏之后就会给古文分词了。
但是,我们遇到了一个问题:
李白有一句诗:“天上白玉京,十二楼五城”,当用户搜索这句诗的时候,模型有时候会认为「白玉京」是一个姓「白」名「玉京」的人,把它拆成两个词,有时候会认为「白玉京」是一个词,两种情况搜索结果完全不同,用户可能会找不到这首诗。
在这种情况下,我们就使用单字切词的方式,把整句诗都拆成一个一个的字,就能保证把这首诗搜出来了。
Q3:看来古文的语法问题比较难处理,识别单字会更简单?
也没有那么简单。
正常你用搜索引擎,显示搜索结果的时候,你搜的词会被高亮或者变个颜色展示出来。但有一天产品验收的时候就给我提了一个问题:搜索结果中的异体字不会被高亮。
比如,「白」字在古籍中还有两个变体字:
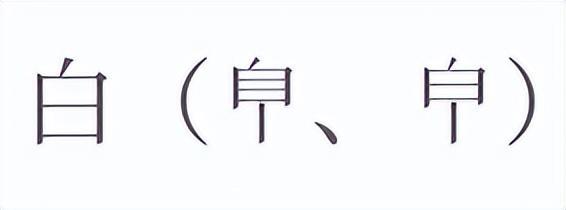
搜出来正常的「白」字都被高亮了,两种异体字却没有被高亮。这种情况很常见,比如搜老子的《道德经》你会发现这三个字,每个都有很多种写法:

那我就要去解决这个问题,把每个字的每种写法,不管是繁体字、异体字还是通假字,都归一化,就像你搜索大写「ABC」的时候,小写的「abc」也可以被搜出来一样。
我们搜罗了很多异体字相关资料,甚至包括北大老师他们自己总结出来的异体字映射表,经过数据清洗之后形成了我们自己的繁简归一化程序。用户输入搜索词的时候,我们统一转化成简体字来搜;呈现结果的时候,再把各种写法都变成高亮。
我试了一下,这套数据非常齐全,比市面上很多主流繁简转换工具都全。
Q4:你不是专门做搜索的同学,也不是专门做 NLP 的同学,那你怎么完成这项工作?
因为公司有其他团队可以合作呀,我找到了公司内部搜索相关的中台团队,他们为我提供了很大的帮助,有什么问题都可以去请教他们。
为了完成古籍定制化的服务,我也学了很多知识,除了学习搜索中台的帮助文档外,我还买了一本巨厚的《信息检索导论》自学 ,努力去了解分词相关的论文资料。
之前遇到一个问题,用户搜索的那句话的原文总是排在搜索结果的第二而不是第一,我就一点点的去看返回结果的日志,研究其中每一轮排序的相关细节,想尽各种手段研究明白它的打分权重之后才解决了这个问题。总之,做这个项目的过程中,我学到了很多搜索技术。
-The End-
看完上面四位程序员同学的经历,你会发现这些能够帮助更多人学习、重温历史文化的工作有其自身的价值和魅力。
用先进的技术,修复古老的记忆,这本身就是一件很酷的事儿吧。



![[HarekazeCTF2019]Easy Notes](https://img-blog.csdnimg.cn/88656c0b54b943c6b24a99e40e33ba17.png)