一、前言
今天公司规定了不要使用SELECT *进行查询,让我想到阿里的《Java 开发手册》
中的ORM 映射规范也是这样的,于是翻出来看看,刚刚好重温一下!
规范看了一定要实践,严格规范自己的代码风格,做一个优雅的码农哈!
即使公司不要求,我们也要自己养成习惯,大家可以没事多看几遍,不知道哪里下载的小伙伴可以下载一下最新版:黄山版
《Java 开发手册》-黄山版下载
二、规范
在第38页中:
(四) ORM 映射
【强制】 在表查询中,一律不要使用*作为查询的字段列表,需要哪些字段必须明确写明。
说明:
增加查询分析器解析成本。增减字段容易与 resultMap 配置不一致。- 无用字段
增加网络消耗,尤其是 text 类型的字段。
虽然好了,但是每个表少则8、9个字段,多则几十个字段,自己挨个写实在是太慢了!
我们要学会利用工具,小编这里使用Navicat,教大家两种方式哈!
三、解决方案
1. 第一种
第一种比较简单是mysql自己结构中存在的表中的列信息,我们查询出来拼接一下就可以了:
我们可以看到这里MySQL所有表的列都在COLUMNS
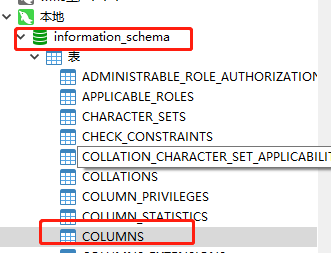
我们直接查询即可:
table_name = '表名'
SELECT
group_concat( COLUMN_NAME )
FROM
information_schema.COLUMNS
WHERE
table_name = 'sys_log';
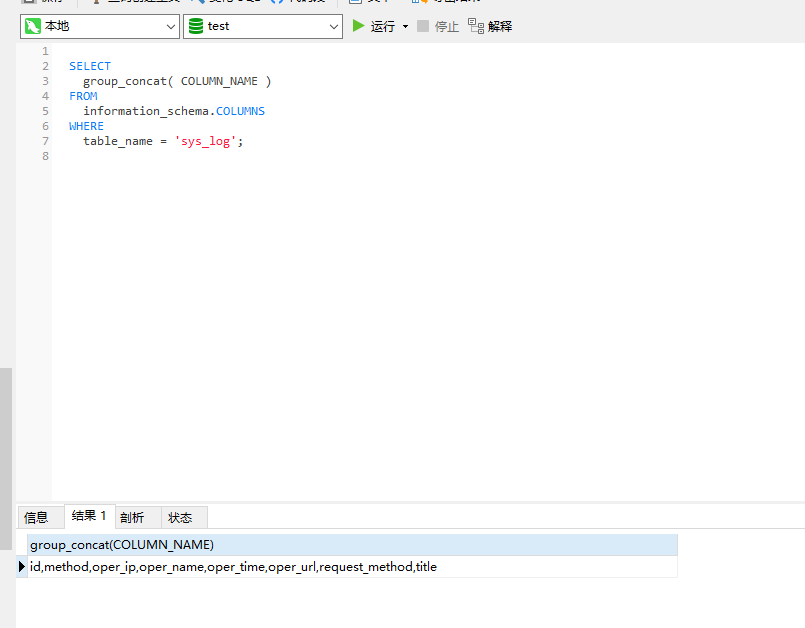
当然这样有点缺点,我们连表进行起别名的时候,字段上还是要自己加
当然规范也是不推荐连表的,但是这个表设计不太好,没有冗余字段,只能这样了!
所以推荐第二种方案!
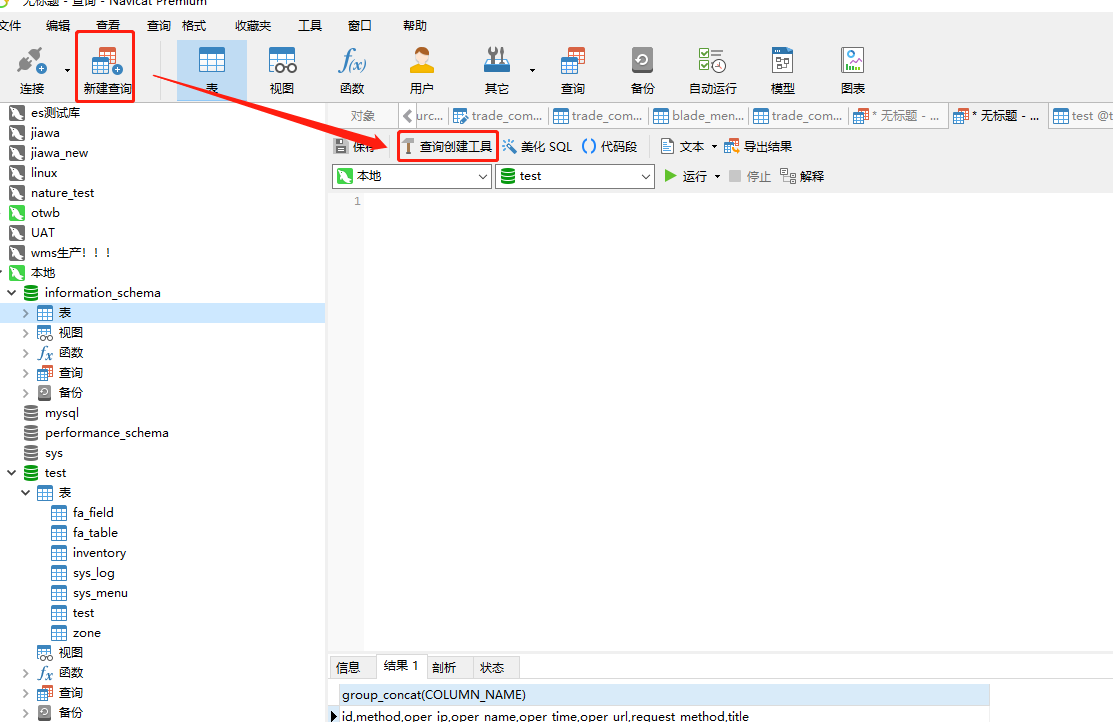
2. 第二种
新建查询-> 查询创建工具
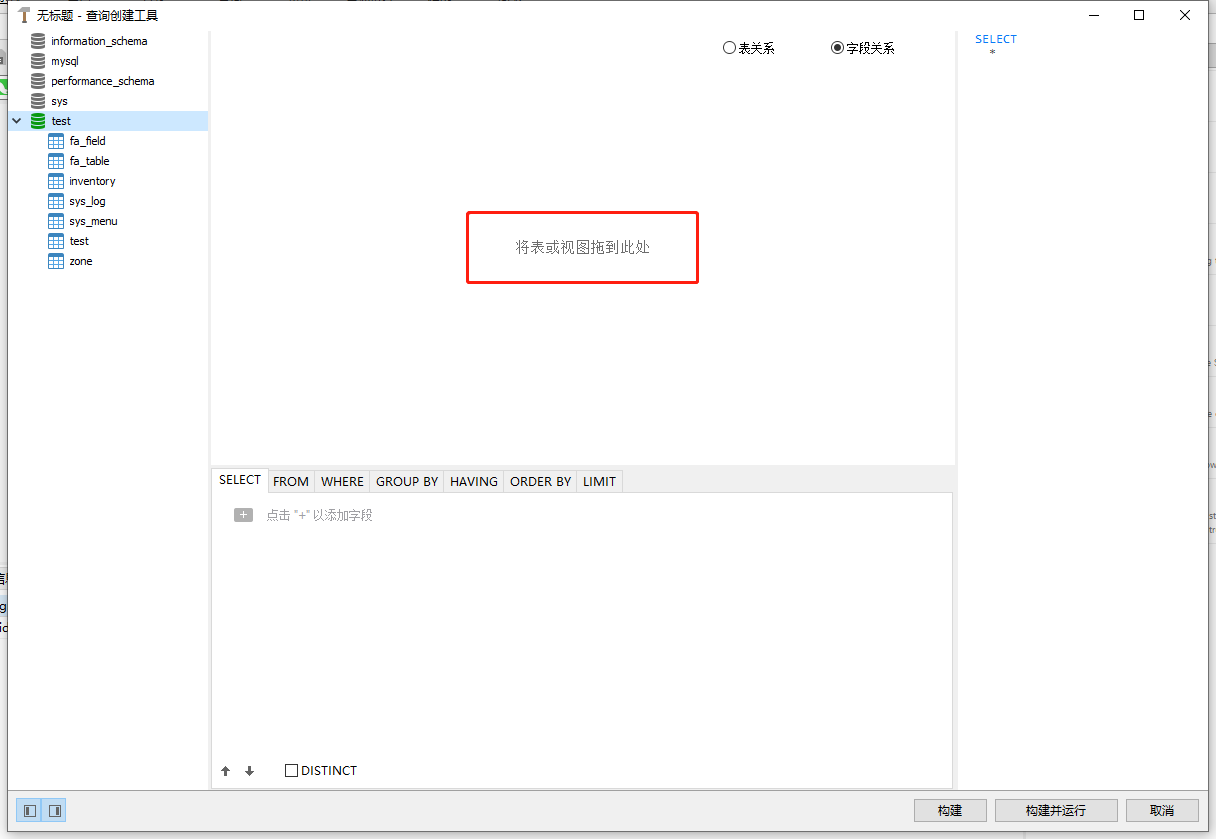
把需要的表拖进来:
在勾选自己需要的字段:
有个缺点不能全选,需要自己一个个的选择,不过可以弥补上面的起别名和各种操作!
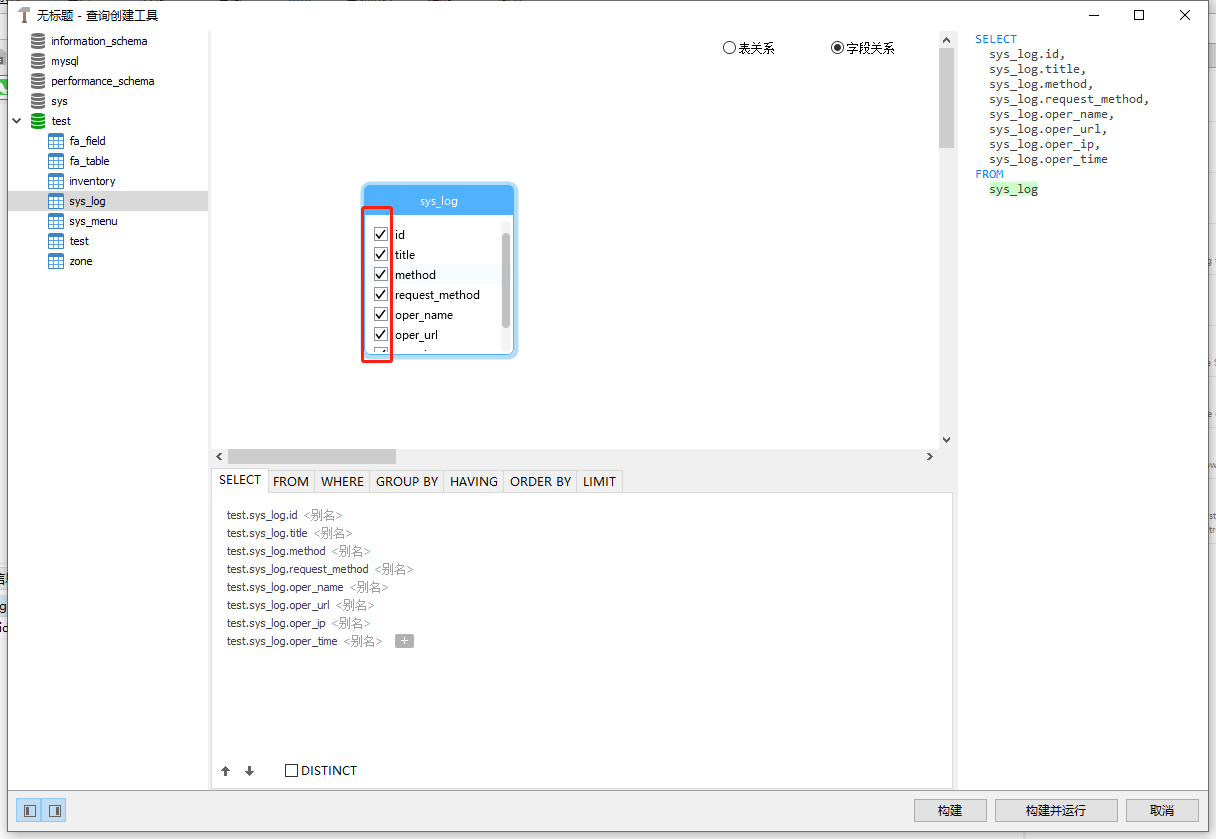
这里演示表起别名:
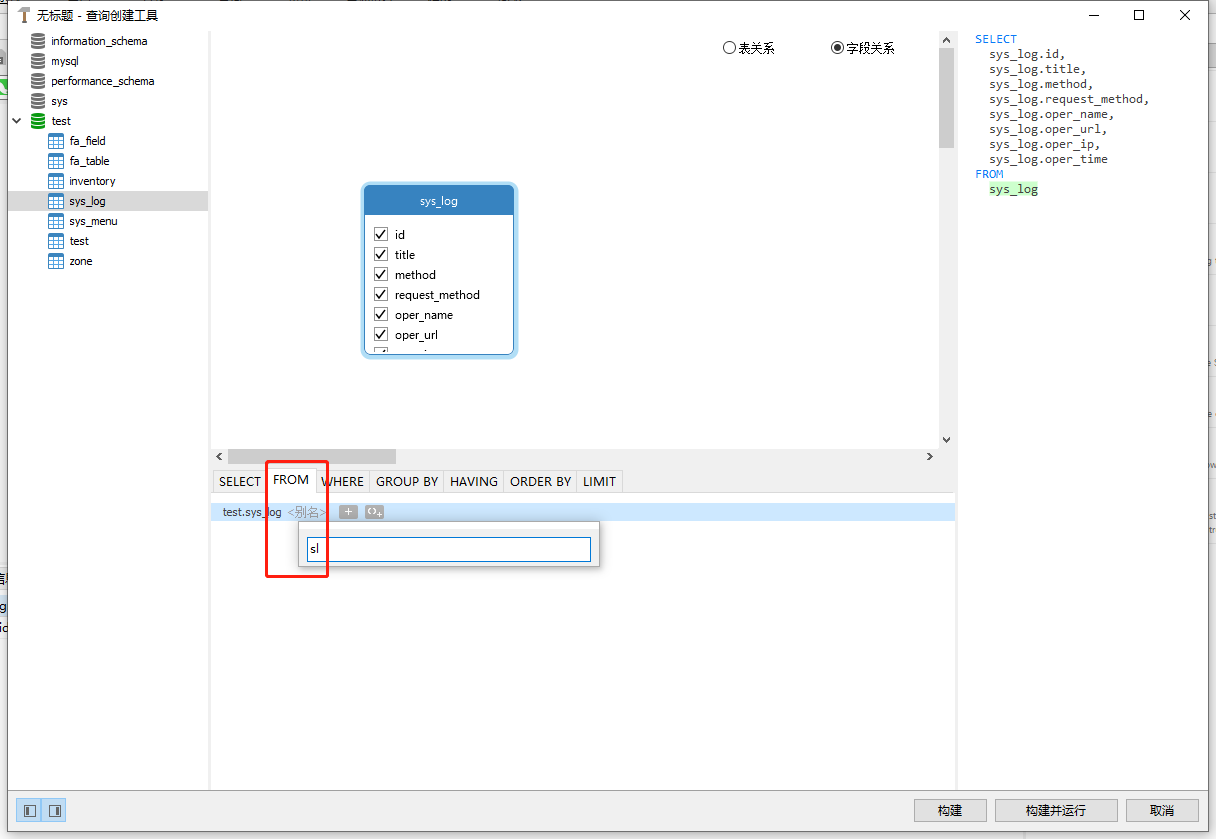
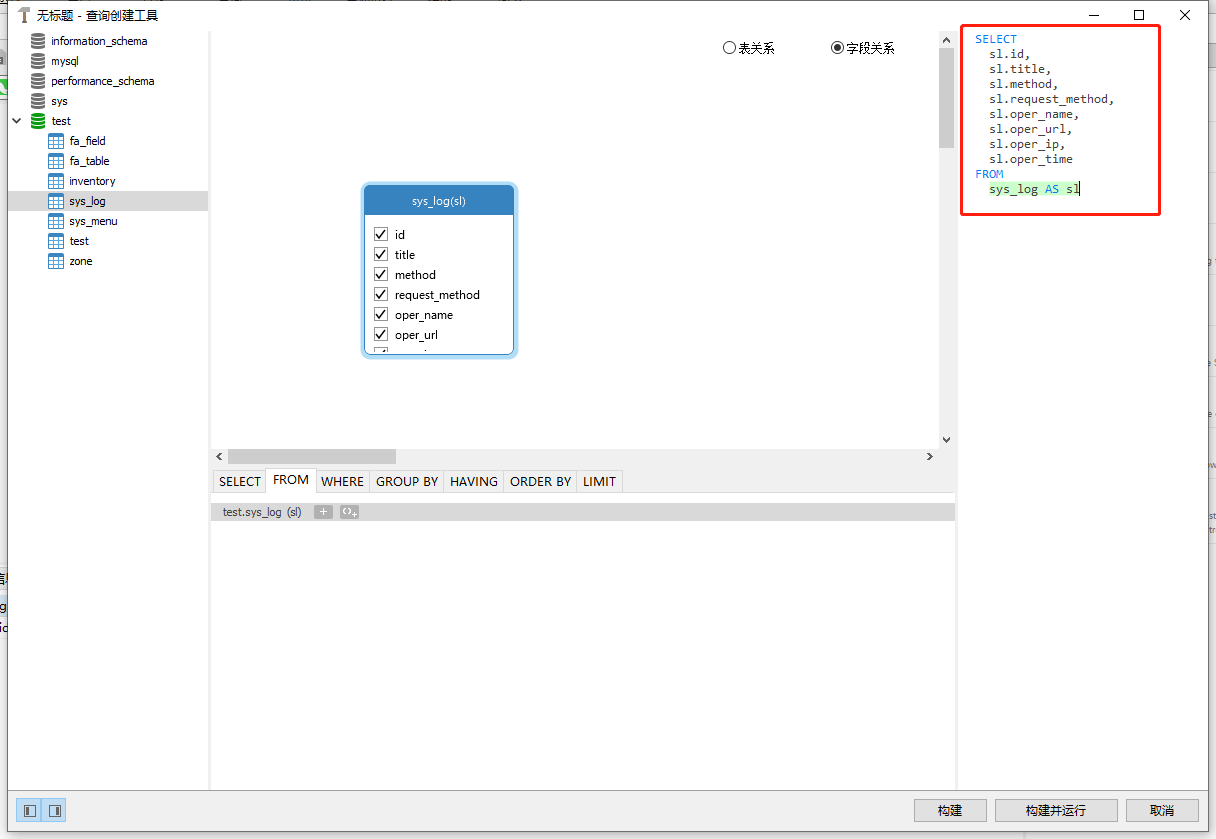
sql字段已准备好:
四、总结
这样就节省了很多时间,遵守了规范,一举两得!
对你有帮助,还请不要吝啬你的发财小手点点关注哈!
写作不易,大家给点支持,你的支持是我写作的动力哈!
关注小编的微信公众号,一起交流学习!文章首发看哦!