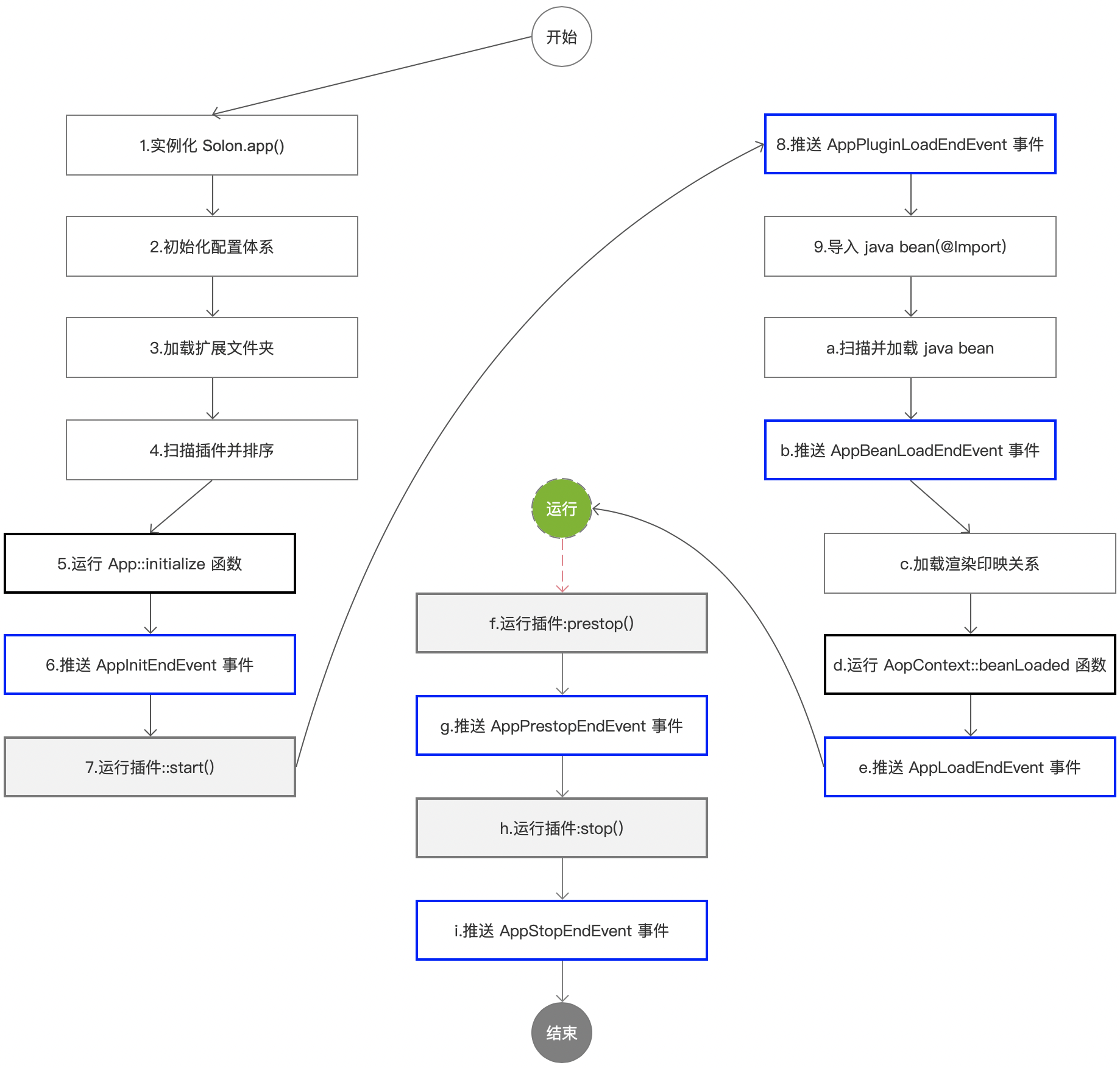
此次用到的虚拟环境:pytorchmwy
项目名称:limuAI
所需框架和工具:pytorch,pandas
一、创建CSV文件
所需工具:pandas
在与项目同等目录下创建一个文件夹名为data,其中文件名称为house_tiny.csv。
代码如下:
import os
import pandas as pd
os.makedirs(os.path.join('..','data'),exist_ok=True)
data_file = os.path.join('..','data','house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每⾏表⽰⼀个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
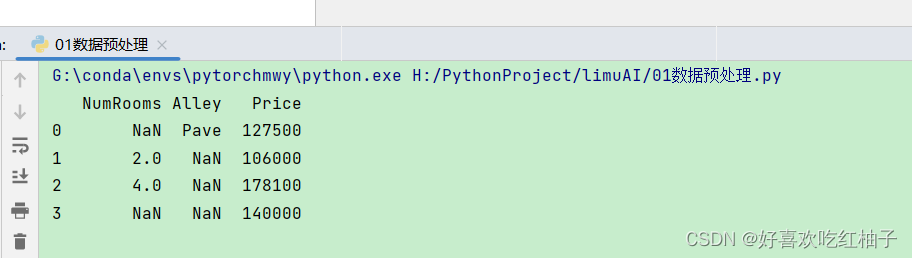
data = pd.read_csv(data_file)
print(data)
二、补全缺失值
2.1 补全数字
注意到上面表格中的数据有缺失值,因此考虑插值法进行数据补全。
pandas中的iloc函数:通过行号来取行数据(index location)
e.g. data.iloc[ : , 0:2 ],取数据表的第1和第2行,以及所有的行取出来。
# 抽取缺失列
inputs,outputs = data.iloc[:,[0,1]],data.iloc[:,2]
# 将缺失值补充为数据的平均值
inputs = inputs.fillna(inputs.mean())
print(inputs)可以看到numrooms中的数据被补全了,2和4的均值为3,故被补全为3。

2.2 补全字符串值
但是Alley中的数据还是有空值,因为pave是字符串,无法进行mean操作求值。对于inputs中的类别值或者离散值,我们将“NaN”视作一个类别。
get_dummies方法可以把把 离散的类别信息转化为onehot编码形式,
dummy_na=True意为是否把nan单独看做一个类别。
inputs = pd.get_dummies(inputs,dummy_na=True)
print(inputs)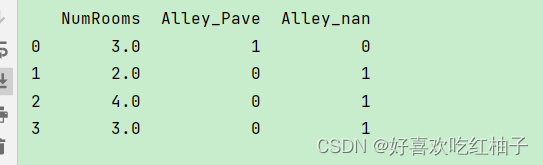
三、数值类型转换为张量
把inputs和outputs的数值形式转换为pytorch中的张量(tensor)形式。
#转换为张量格式
x,y = torch.tensor(inputs.values),torch.tensor(outputs.values)
print(x,'\n',y)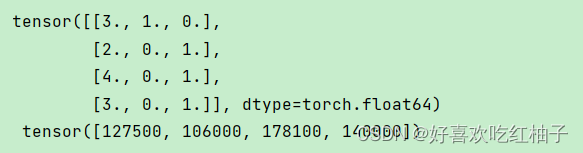
四、完整代码
import os
import pandas as pd
import torch
#创建本地文件数据表
os.makedirs(os.path.join('..','data'),exist_ok=True)
data_file = os.path.join('..','data','house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每⾏表⽰⼀个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
# 打印数据表
data = pd.read_csv(data_file)
print(data)
# 抽取缺失列
inputs,outputs = data.iloc[:,[0,1]],data.iloc[:,2]
# 将缺失值补充为数据的平均值
inputs = inputs.fillna(inputs.mean())
print(inputs)
#生成两个类
inputs = pd.get_dummies(inputs,dummy_na=True)
print(inputs)
#转换为张量格式
x,y = torch.tensor(inputs.values),torch.tensor(outputs.values)
print(x,'\n',y)

![[AI助力] 2022.2.23 考研英语学习 2010 英语二翻译](https://img-blog.csdnimg.cn/d4984061e48a44a4bbb13eb38e258085.png)