好久不更了,这次一鼓作气,学完它!
文章目录
- LeetCode Cookbook 哈希表
- 30. 串联所有单词的子串
- 36. 有效的数独(很不错的循环题目)
- 49. 字母异位词分组
- 290. 单词规律
- 447. 回旋镖的数量
- 575. 分糖果
- 594. 最长和谐子序列
- 599. 两个列表的最小索引总和
- 648. 单词替换(字典树 Trie)
- 676. 实现一个魔法字典
- 705. 设计哈希集合
- 745. 前缀和后缀搜索
- 811. 子域名访问计数
- 884. 两句话中的不常见单词
- 961. 在长度 2N 的数组中找出重复 N 次的元素
- 1207. 独一无二的出现次数
- 总结
LeetCode Cookbook 哈希表
本节是与哈希表相关的习题,非常不错的17道题,在这里分享给大家,如果喜欢的话,欢迎点赞收藏家关注哦!
30. 串联所有单词的子串
题目链接:30. 串联所有单词的子串
题目大意:给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
例如,如果 words = [“ab”,“cd”,“ef”], 那么 “abcdef”, “abefcd”,“cdabef”, “cdefab”,“efabcd”, 和 “efcdab” 都是串联子串。 “acdbef” 不是串联子串,因为他不是任何 words 排列的连接。
返回所有串联字串在 s 中的开始索引。你可以以 任意顺序 返回答案。
注意:(1)1 <= s.length <= 1 0 4 10^4 104;(2)1 <= words.length <= 5000;(3)1 <= words[i].length <= 30;(4)words[i] 和 s 由小写英文字母组成
例如:
输入:s = "barfoothefoobarman", words = ["foo","bar"]
输出:[0,9]
解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。
子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。
输出顺序无关紧要。返回 [9,0] 也是可以的。
输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
输出:[]
解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。
所以我们返回一个空数组。
输入:s = "barfoofoobarthefoobarman", words = ["bar","foo","the"]
输出:[6,9,12]
解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。
子串 "foobarthe" 开始位置是 6。它是 words 中以 ["foo","bar","the"] 顺序排列的连接。
子串 "barthefoo" 开始位置是 9。它是 words 中以 ["bar","the","foo"] 顺序排列的连接。
子串 "thefoobar" 开始位置是 12。它是 words 中以 ["the","foo","bar"] 顺序排列的连接。
- 解题思路: 哈希表比较容易理解一些。
- 时间复杂度: O ( n 2 ) O(n^2) O(n2) 方法1滑动窗口为 O ( n ) O(n) O(n)
- 空间复杂度: O ( n ) O(n) O(n)
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
if not s or not words: return []
one_word =len(words[0])
all_words = one_word*len(words)
n = len(s)
nums = len(words)
if n<one_word: return []
words = Counter(words)
ans = []
# 方法1 滑动窗口
# for i in range(0,one_word):
# cur_cnt = 0
# left,right = i,i
# cur_Counter = Counter()
# while right+one_word <= n:
# w = s[right:right+one_word]
# right += one_word
# if w not in words:
# left = right
# cur_Counter.clear()
# cur_cnt = 0
# else:
# cur_Counter[w] += 1
# cur_cnt += 1
# while cur_Counter[w] > words[w]:
# left_w = s[left:left+one_word]
# left += one_word
# cur_Counter[left_w] -= 1
# cur_cnt -= 1
# if cur_cnt == nums:
# ans.append(left)
# return ans
# hash 表
for i in range(n-all_words+1):
tmp = s[i:i+all_words]
c_tmp = []
# 把单词分割一下一个一个往里放
for j in range(0,all_words,one_word):
c_tmp.append(tmp[j:j+one_word])
# 使用计数器看一下 是不是子单词都齐全了
if Counter(c_tmp) == words:
ans.append(i)
return ans
36. 有效的数独(很不错的循环题目)
题目链接:36. 有效的数独
题目大意:请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。
1.数字 1-9 在每一行只能出现一次。
2.数字 1-9 在每一列只能出现一次。
3.数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
注意:
(1)一个有效的数独(部分已被填充)不一定是可解的。
(2)只需要根据以上规则,验证已经填入的数字是否有效即可。
(3)空白格用 ‘.’ 表示。
(4)board.length == 9;board[i].length == 9;board[i][j] 是一位数字(1-9)或者 ‘.’。
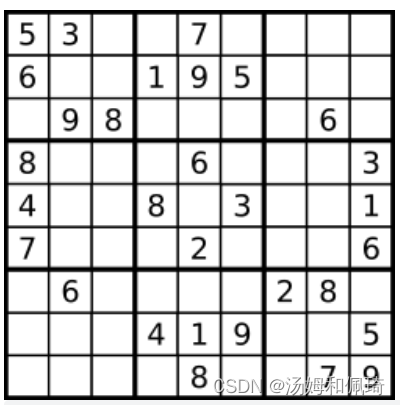
例如:
输入:board =
[["5","3",".",".","7",".",".",".","."]
,["6",".",".","1","9","5",".",".","."]
,[".","9","8",".",".",".",".","6","."]
,["8",".",".",".","6",".",".",".","3"]
,["4",".",".","8",".","3",".",".","1"]
,["7",".",".",".","2",".",".",".","6"]
,[".","6",".",".",".",".","2","8","."]
,[".",".",".","4","1","9",".",".","5"]
,[".",".",".",".","8",".",".","7","9"]]
输出:true
- 解题思路:写好循环,注意九宫格的第三个要求,可以适当记忆一下。在固定的个9*9数据计算中,复杂度不随数据变化而变化。
- 时间复杂度: O ( 1 ) O(1) O(1)
- 空间复杂度: O ( 1 ) O(1) O(1)
class Solution:
def isValidSudoku(self, board: List[List[str]]) -> bool:
# 行、列、块
row = [[]*9 for _ in range(9)]
col = [[]*9 for _ in range(9)]
nine = [[]*9 for _ in range(9)]
for i in range(9):
for j in range(9):
tmp = board[i][j]
if not tmp.isdigit():
continue
# 是否同行或同列出现相同的
if tmp in row[i] or tmp in col[j]:
return False
# 判断九宫格
if tmp in nine[(j//3)*3+i//3]:
return False
row[i].append(tmp)
col[j].append(tmp)
nine[(j//3)*3+i//3].append(tmp)
return True
49. 字母异位词分组
题目链接:49. 字母异位词分组
题目大意:给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
注意:(1)1 <= strs.length <=
1
0
4
10^4
104;(2)0 <= strs[i].length <= 100;(3)strs[i] 仅包含小写字母。
例如:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
输入: strs = [""]
输出: [[""]]
输入: strs = ["a"]
输出: [["a"]]
- 解题思路:注意字符串连接排序后的字符数组需要连接。
- 时间复杂度: O ( n ( k + ∣ Σ ∣ ) ) O(n(k+∣\Sigma∣)) O(n(k+∣Σ∣)),其中 n n n 是 strs \textit{strs} strs 中的字符串的数量, k k k 是 strs \textit{strs} strs 中的字符串的的最大长度, Σ \Sigma Σ 是字符集,在本题中字符集为所有小写字母, ∣ Σ ∣ = 26 |\Sigma|=26 ∣Σ∣=26。需要遍历 n n n 个字符串,对于每个字符串,需要 O ( k ) O(k) O(k) 的时间计算每个字母出现的次数, O ( ∣ Σ ∣ ) O(|\Sigma|) O(∣Σ∣)的时间生成哈希表的键,以及 O ( 1 ) O(1) O(1) 的时间更新哈希表,因此总时间复杂度是 O ( n ( k + ∣ Σ ∣ ) ) O(n(k+|\Sigma|)) O(n(k+∣Σ∣))。
- 空间复杂度: O ( n ( k + ∣ Σ ∣ ) ) O(n(k+∣\Sigma∣)) O(n(k+∣Σ∣))
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
if len(strs)<2:
return [strs]
d = collections.defaultdict(list)
for s in strs:
# sorted(s) 返回的内容是字符串数组 需要join一下
s1 = "".join(sorted(s))
d[s1].append(s)
return list(d.values())
290. 单词规律
题目链接:290. 单词规律
题目大意:给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。
注意:(1)1 <= pattern.length <= 300;(2)pattern 只包含小写英文字母;(3)1 <= s.length <= 3000;(4)s 只包含小写英文字母和 ’ ';(5)s 不包含 任何前导或尾随对空格,s 中每个单词都被 单个空格分隔。
例如:
输入: pattern = "abba", s = "dog cat cat dog"
输出: true
输入:pattern = "abba", s = "dog cat cat fish"
输出: false
输入: pattern = "aaaa", s = "dog cat cat dog"
输出: false
- 解题思路: 哈希表来做,zip()函数非常好用。
- 时间复杂度: O ( n + m ) O(n+m) O(n+m) n,m分别为pattern和s的长度
- 空间复杂度: O ( n + m ) O(n+m) O(n+m)
class Solution:
def wordPattern(self, pattern: str, s: str) -> bool:
def match(word,pattern):
mp = {}
for m,p in zip(word,pattern):
if m not in mp:
mp[m] = p
elif mp[m] != p:
return False
return True
word = s.split()
return match(pattern,word) and match(word,pattern) and len(word) == len(pattern)
447. 回旋镖的数量
题目链接:447. 回旋镖的数量
题目大意:给定平面上 n 对 互不相同 的点 points ,其中 points[i] =
[
x
i
,
y
i
]
[x_i, y_i]
[xi,yi] 。回旋镖 是由点 (i, j, k) 表示的元组 ,其中 i 和 j 之间的距离和 i 和 k 之间的欧式距离相等(需要考虑元组的顺序)。
返回平面上所有回旋镖的数量。
注意:(1)n == points.length;(2)1 <= n <= 500;(3)points[i].length == 2;(4) − 1 0 4 < = x i , y i < = 1 0 4 -10^4 <= x_i, y_i <= 10^4 −104<=xi,yi<=104;(5)所有点都互不相同。
例如:
输入:points = [[0,0],[1,0],[2,0]]
输出:2
解释:两个回旋镖为 [[1,0],[0,0],[2,0]] 和 [[1,0],[2,0],[0,0]]
输入:points = [[1,1],[2,2],[3,3]]
输出:2
输入:points = [[1,1]]
输出:0
- 解题思路:注意用到了组合公式。
- 时间复杂度: O ( n 2 ) O(n^2) O(n2),n为数组长度
- 空间复杂度: O ( n ) O(n) O(n)
class Solution:
def numberOfBoomerangs(self, points: List[List[int]]) -> int:
if len(points)<3:
return 0
ans = 0
for a in points:
d = collections.defaultdict(int)
for b in points:
dis = (b[0]-a[0])**2+(b[1]-a[1])**2
d[dis] += 1
for n in d.values():
# 组合公式 从d[b]个中抽2两个排列
ans+=n*(n-1)
return ans
575. 分糖果
题目链接:575. 分糖果
题目大意:Alice 有 n 枚糖,其中第 i 枚糖的类型为 candyType[i] 。Alice 注意到她的体重正在增长,所以前去拜访了一位医生。
医生建议 Alice 要少摄入糖分,只吃掉她所有糖的 n / 2 即可(n 是一个偶数)。Alice 非常喜欢这些糖,她想要在遵循医生建议的情况下,尽可能吃到最多不同种类的糖。
给你一个长度为 n 的整数数组 candyType ,返回: Alice 在仅吃掉 n / 2 枚糖的情况下,可以吃到糖的 最多 种类数。
注意:(1)n == candyType.length;(2)
2
<
=
n
<
=
1
0
4
2 <= n <= 10^4
2<=n<=104;(3)n 是一个偶数;(4)
−
1
0
5
<
=
c
a
n
d
y
T
y
p
e
[
i
]
<
=
1
0
5
-10^5 <= candyType[i] <= 10^5
−105<=candyType[i]<=105。
例如:
输入:candyType = [1,1,2,2,3,3]
输出:3
解释:Alice 只能吃 6 / 2 = 3 枚糖,由于只有 3 种糖,她可以每种吃一枚。
输入:candyType = [1,1,2,3]
输出:2
解释:Alice 只能吃 4 / 2 = 2 枚糖,不管她选择吃的种类是 [1,2]、[1,3] 还是 [2,3],她只能吃到两种不同类的糖。
输入:candyType = [6,6,6,6]
输出:1
解释:Alice 只能吃 4 / 2 = 2 枚糖,尽管她能吃 2 枚,但只能吃到 1 种糖。
- 解题思路:不难,可以用 集合容器(set) 进行去重。
- 时间复杂度: O ( n ) O(n) O(n) n为candyType的长度
- 空间复杂度: O ( n ) O(n) O(n)
class Solution:
def distributeCandies(self, candyType: List[int]) -> int:
n1 = len(candyType)//2
n2 = len(set(candyType))
return n1 if n2>=n1 else n2
594. 最长和谐子序列
题目链接:594. 最长和谐子序列
题目大意:和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。
现在,给你一个整数数组 nums ,请你在所有可能的子序列中找到最长的和谐子序列的长度。
数组的子序列是一个由数组派生出来的序列,它可以通过删除一些元素或不删除元素、且不改变其余元素的顺序而得到。
注意:(1)
1
<
=
n
u
m
s
.
l
e
n
g
t
h
<
=
2
∗
1
0
4
1 <= nums.length <= 2 * 10^4
1<=nums.length<=2∗104;(2)
−
1
0
9
<
=
n
u
m
s
[
i
]
<
=
1
0
9
-10^9 <= nums[i] <= 10^9
−109<=nums[i]<=109。
例如:
输入:nums = [1,3,2,2,5,2,3,7]
输出:5
解释:最长的和谐子序列是 [3,2,2,2,3]
输入:nums = [1,2,3,4]
输出:2
输入:nums = [1,1,1,1]
输出:0
- 解题思路:巧用 Counter() 容器
- 时间复杂度: O ( n ) O(n) O(n) n为数组长度
- 空间复杂度: O ( n ) O(n) O(n)
class Solution:
def findLHS(self, nums: List[int]) -> int:
if len(nums)<2: return 0
cnt = collections.Counter(nums)
ans = 0
for k in cnt:
if k+1 in cnt:
t = cnt[k]+cnt[k+1]
ans = t if t>ans else ans
return ans
599. 两个列表的最小索引总和
题目链接:599. 两个列表的最小索引总和
题目大意:假设 Andy 和 Doris 想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。
你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设答案总是存在。
注意:(1)1 <= list1.length, list2.length <= 1000;(2)1 <= list1[i].length, list2[i].length <= 30 ;(3)list1[i] 和 list2[i] 由空格 ’ ’ 和英文字母组成;(4)list1 的所有字符串都是 唯一 的,list2 中的所有字符串都是 唯一 的。
例如:
输入: list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"]
输出: ["Shogun"]
解释: 他们唯一共同喜爱的餐厅是“Shogun”。
输入:list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["KFC", "Shogun", "Burger King"]
输出: ["Shogun"]
解释: 他们共同喜爱且具有最小索引和的餐厅是“Shogun”,它有最小的索引和1(0+1)。
- 解题思路: 按题意做就行
- 时间复杂度: O ( n + m ) O(n+m) O(n+m) ,n,m分别为list1和list2的长度
- 空间复杂度: O ( n ) O(n) O(n)
class Solution:
def findRestaurant(self, list1: List[str], list2: List[str]) -> List[str]:
d = {s:i for i,s in enumerate(list2)}
ans,f = [],2000
for i,s in enumerate(list1):
if s in d:
t = i+d[s]
if t < f:
f = i+d[s]
ans = [s]
elif t == f:
ans.append(s)
return ans
648. 单词替换(字典树 Trie)
题目链接:648. 单词替换
题目大意:在英语中,我们有一个叫做 词根(root) 的概念,可以词根后面添加其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典 dictionary 和一个用空格分隔单词形成的句子 sentence。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
注意:(1)1 <= dictionary.length <= 1000;(2)1 <= dictionary[i].length <= 100;(3)dictionary[i] 仅由小写字母组成;(4)1 <= sentence.length <=
1
0
6
10^6
106;(5)sentence 仅由小写字母和空格组成,sentence 中单词的总量在范围 [1, 1000] 内,sentence 中每个单词的长度在范围 [1, 1000] 内,sentence 中单词之间由一个空格隔开,sentence 没有前导或尾随空格。
例如:
输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
输入:dictionary = ["a","b","c"], sentence = "aadsfasf absbs bbab cadsfafs"
输出:"a a b c"
- 解题思路: 字典树,背诵吧。
- 时间复杂度: O ( n + m ) ) O(n+m)) O(n+m)) n,m分别为dictionary和sentence的长度
- 空间复杂度: O ( n × C ) O(n \times C) O(n×C) C=26
class Trie:
# 字典序 模板
def __init__(self) -> None:
self.next = collections.defaultdict(Trie)
self.end = False
def add(self, word: str) -> None:
cur = self
for c in word:
cur = cur.next[c]
if cur.end:
return
cur.end = True
def contain_prefix(self,word: str) -> bool:
cur = self
prefix = ''
for c in word:
if c in cur.next:
cur = cur.next[c]
prefix += c
else:
return False
if cur.end:
return prefix
return False
class Solution:
def replaceWords(self, dictionary: List[str], sentence: str) -> str:
trie = Trie()
for word in dictionary:
trie.add(word)
ans = []
for word in sentence.split():
if prefix := trie.contain_prefix(word):
ans.append(prefix)
else:
ans.append(word)
return ' '.join(ans)
676. 实现一个魔法字典
题目链接:676. 实现一个魔法字典
题目大意:设计一个使用单词列表进行初始化的数据结构,单词列表中的单词 互不相同 。 如果给出一个单词,请判定能否只将这个单词中一个字母换成另一个字母,使得所形成的新单词存在于你构建的字典中。
实现 MagicDictionary 类:
MagicDictionary() 初始化对象
void buildDict(String[] dictionary) 使用字符串数组 dictionary 设定该数据结构,dictionary 中的字符串互不相同
bool search(String searchWord) 给定一个字符串 searchWord ,判定能否只将字符串中 一个 字母换成另一个字母,使得所形成的新字符串能够与字典中的任一字符串匹配。如果可以,返回 true ;否则,返回 false 。
注意:(1)1 <= dictionary.length <= 100;(2)1 <= dictionary[i].length <= 100;(3)dictionary[i] 仅由小写英文字母组成;(4)dictionary 中的所有字符串 互不相同;(5)1 <= searchWord.length <= 100;(6)searchWord 仅由小写英文字母组成,buildDict 仅在 search 之前调用一次;(7)最多调用 100 次 search。
例如:
输入
["MagicDictionary", "buildDict", "search", "search", "search", "search"]
[[], [["hello", "leetcode"]], ["hello"], ["hhllo"], ["hell"], ["leetcoded"]]
输出
[null, null, false, true, false, false]
解释
MagicDictionary magicDictionary = new MagicDictionary();
magicDictionary.buildDict(["hello", "leetcode"]);
magicDictionary.search("hello"); // 返回 False
magicDictionary.search("hhllo"); // 将第二个 'h' 替换为 'e' 可以匹配 "hello" ,所以返回 True
magicDictionary.search("hell"); // 返回 False
magicDictionary.search("leetcoded"); // 返回 False
-
解题思路:使用 list
-
时间复杂度: O ( q n l ) O(qnl) O(qnl),其中 n n n 是数组 dictionary 的长度, l l l 是数组 dictionary 中字符串的平均长度, q q q 是函数 search(searchWord) \text{search(searchWord)} search(searchWord) 的调用次数。
-
空间复杂度: O ( n l ) O(nl) O(nl)
class MagicDictionary:
def __init__(self):
self.word = list()
def buildDict(self, dictionary: List[str]) -> None:
self.word = dictionary
def search(self, searchWord: str) -> bool:
for word in self.word:
if len(word) != len(searchWord):
continue
diff = 0
for a,b in zip(word,searchWord):
if a != b:
diff += 1
if diff > 1:
break
if diff == 1:
return True
return False
# Your MagicDictionary object will be instantiated and called as such:
# obj = MagicDictionary()
# obj.buildDict(dictionary)
# param_2 = obj.search(searchWord)
705. 设计哈希集合
题目链接:705. 设计哈希集合
题目大意:不使用任何内建的哈希表库设计一个哈希集合(HashSet)。
实现 MyHashSet 类:
void add(key) 向哈希集合中插入值 key 。
bool contains(key) 返回哈希集合中是否存在这个值 key 。
void remove(key) 将给定值 key 从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
注意:(1)0 <= key <=
1
0
6
10^6
106;(2)最多调用
1
0
4
10^4
104 次 add、remove 和 contains。
例如:
输入:
["MyHashSet", "add", "add", "contains", "contains", "add", "contains", "remove", "contains"]
[[], [1], [2], [1], [3], [2], [2], [2], [2]]
输出:
[null, null, null, true, false, null, true, null, false]
解释:
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = [1]
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(1); // 返回 True
myHashSet.contains(3); // 返回 False ,(未找到)
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(2); // 返回 True
myHashSet.remove(2); // set = [1]
myHashSet.contains(2); // 返回 False ,(已移除)
- 解题思路:尽量优化一些
- 时间复杂度: O ( 1 ) O(1) O(1)
- 空间复杂度: O ( 数据范围 ) O(数据范围) O(数据范围)
class MyHashSet:
def __init__(self):
self.d = []
def add(self, key: int) -> None:
if key not in self.d:
self.d.append(key)
else: return
def remove(self, key: int) -> None:
if len(self.d) == 0 or key not in self.d:
return
else:
id = self.d.index(key)
del(self.d[id])
def contains(self, key: int) -> bool:
if key in self.d:
return True
else: return False
# Your MyHashSet object will be instantiated and called as such:
# obj = MyHashSet()
# obj.add(key)
# obj.remove(key)
# param_3 = obj.contains(key)
745. 前缀和后缀搜索
题目链接:745. 前缀和后缀搜索
题目大意:设计一个包含一些单词的特殊词典,并能够通过前缀和后缀来检索单词。
实现 WordFilter 类:
WordFilter(string[] words) 使用词典中的单词 words 初始化对象。
f(string pref, string suff) 返回词典中具有前缀 prefix 和后缀 suff 的单词的下标。如果存在不止一个满足要求的下标,返回其中 最大的下标 。如果不存在这样的单词,返回 -1 。
注意:(1)1 <= words.length <=
1
0
4
10^4
104;(2)1 <= words[i].length <= 7;(3)1 <= pref.length, suff.length <= 7;(4)words[i]、pref 和 suff 仅由小写英文字母组成;(5)最多对函数 f 执行
1
0
4
10^4
104 次调用。
例如:
输入
["WordFilter", "f"]
[[["apple"]], ["a", "e"]]
输出
[null, 0]
解释
WordFilter wordFilter = new WordFilter(["apple"]);
wordFilter.f("a", "e"); // 返回 0 ,因为下标为 0 的单词:前缀 prefix = "a" 且 后缀 suff = "e" 。
- 解题思路:尽量优化一些
- 时间复杂度:初始消耗 O ( ∑ i = 0 n − 1 w i 3 ) O(\sum\limits_{i=0}^{n-1}w_i^3) O(i=0∑n−1wi3),其中 w i w_i wi为每个单词的字符数。每次检索消耗 O ( p + s ) O(p+s) O(p+s),其中p和s分别为输入的pref和suff的长度。
- 空间复杂度:初始消耗 O ( ∑ i = 0 n − 1 w i 3 ) O(\sum\limits_{i=0}^{n-1}w_i^3) O(i=0∑n−1wi3),每次检索消耗 O ( p + s ) O(p+s) O(p+s)。
class WordFilter:
def __init__(self, words: List[str]):
self.d = {}
for i,word in enumerate(words):
m = len(word)
for pre in range(1,m+1):
for suf in range(1,m+1):
self.d[word[:pre]+'#'+word[-suf:]] = i
def f(self, pref: str, suff: str) -> int:
return self.d.get(pref+'#'+suff,-1)
# Your WordFilter object will be instantiated and called as such:
# obj = WordFilter(words)
# param_1 = obj.f(pref,suff)
811. 子域名访问计数
题目链接:811. 子域名访问计数
题目大意:网站域名 “discuss.leetcode.com” 由多个子域名组成。顶级域名为 “com” ,二级域名为 “leetcode.com” ,最低一级为 “discuss.leetcode.com” 。当访问域名 “discuss.leetcode.com” 时,同时也会隐式访问其父域名 “leetcode.com” 以及 “com” 。
计数配对域名 是遵循 “rep d1.d2.d3” 或 “rep d1.d2” 格式的一个域名表示,其中 rep 表示访问域名的次数,d1.d2.d3 为域名本身。
例如,“9001 discuss.leetcode.com” 就是一个 计数配对域名 ,表示 discuss.leetcode.com 被访问了 9001 次。
给你一个 计数配对域名 组成的数组 cpdomains ,解析得到输入中每个子域名对应的 计数配对域名 ,并以数组形式返回。可以按 任意顺序 返回答案。
注意:(1)1 <= cpdomain.length <= 100;(2)1 <= cpdomain[i].length <= 100;(3)cpdomain[i] 会遵循
"
r
e
p
i
d
1
i
.
d
2
i
.
d
3
i
"
"rep_i \ d1_i.d2_i.d3_i"
"repi d1i.d2i.d3i" 或
"
r
e
p
i
d
1
i
.
d
2
i
"
"rep_i \ d1_i.d2_i"
"repi d1i.d2i" 格式;(4)
r
e
p
i
rep_i
repi 是范围
[
1
,
1
0
4
]
[1, 10^4]
[1,104] 内的一个整数;(5)
d
1
i
d1_i
d1i、
d
2
i
d2_i
d2i 和
d
3
i
d3_i
d3i 由小写英文字母组成。
例如:
输入:
输入:cpdomains = ["9001 discuss.leetcode.com"]
输出:["9001 leetcode.com","9001 discuss.leetcode.com","9001 com"]
解释:例子中仅包含一个网站域名:"discuss.leetcode.com"。
按照前文描述,子域名 "leetcode.com" 和 "com" 都会被访问,所以它们都被访问了 9001 次。
输入:cpdomains = ["900 google.mail.com", "50 yahoo.com", "1 intel.mail.com", "5 wiki.org"]
输出:["901 mail.com","50 yahoo.com","900 google.mail.com","5 wiki.org","5 org","1 intel.mail.com","951 com"]
解释:按照前文描述,会访问 "google.mail.com" 900 次,"yahoo.com" 50 次,"intel.mail.com" 1 次,"wiki.org" 5 次。
而对于父域名,会访问 "mail.com" 900 + 1 = 901 次,"com" 900 + 50 + 1 = 951 次,和 "org" 5 次。
- 解题思路:Counter
- 时间复杂度: O ( L ) O(L) O(L) L是数组 cpdomains 的长度
- 空间复杂度: O ( L ) O(L) O(L)
class Solution:
def subdomainVisits(self, cpdomains: List[str]) -> List[str]:
counter = collections.Counter()
for cpdomain in cpdomains:
n, ch = cpdomain.split()
num = int(n)
counter[ch] += num
while '.' in ch:
ch = ch[(ch.index('.')+1):]
counter[ch] += num
return [f'{n} {ch}' for ch,n in counter.items()]
884. 两句话中的不常见单词
题目链接:884. 两句话中的不常见单词
题目大意:句子 是一串由空格分隔的单词。每个 单词 仅由小写字母组成。
如果某个单词在其中一个句子中恰好出现一次,在另一个句子中却 没有出现 ,那么这个单词就是 不常见的 。
给你两个 句子 s1 和 s2 ,返回所有 不常用单词 的列表。返回列表中单词可以按 任意顺序 组织。
注意:(1)1 <= s1.length, s2.length <= 200;(2)s1 和 s2 由小写英文字母和空格组成,s1 和 s2 都不含前导或尾随空格,s1 和 s2 中的所有单词间均由单个空格分隔。
例如:
输入:s1 = "this apple is sweet", s2 = "this apple is sour"
输出:["sweet","sour"]
输入:s1 = "apple apple", s2 = "banana"
输出:["banana"]
- 解题思路:使用Counter()
- 时间复杂度: O ( n + m ) O(n+m) O(n+m),n和m分别为s1和s2的长度
- 空间复杂度: O ( n + m ) O(n+m) O(n+m)
class Solution:
def uncommonFromSentences(self, s1: str, s2: str) -> List[str]:
ans = []
s = (s1+' '+s2).split()
cnt = collections.Counter(s)
for s in cnt:
if cnt[s] == 1:
ans.append(s)
return ans
961. 在长度 2N 的数组中找出重复 N 次的元素
题目链接:961. 在长度 2N 的数组中找出重复 N 次的元素
题目大意:给你一个整数数组 nums ,该数组具有以下属性:
1.nums.length == 2 * n.
2.nums 包含 n + 1 个 不同的 元素
3.nums 中恰有一个元素重复 n 次
4.找出并返回重复了 n 次的那个元素。
注意:(1)2 <= n <= 5000;(2)nums.length == 2 * n;(3)0 <= nums[i] <= 1 0 4 10^4 104;(5)nums 由 n + 1 个 不同的 元素组成,且其中一个元素恰好重复 n 次。
例如:
输入:nums = [1,2,3,3]
输出:3
输入:nums = [2,1,2,5,3,2]
输出:2
输入:nums = [5,1,5,2,5,3,5,4]
输出:5
- 解题思路:参考官方题解
- 时间复杂度: O ( n ) O(n) O(n)
- 空间复杂度: O ( 1 ) O(1) O(1)
class Solution:
def repeatedNTimes(self, nums: List[int]) -> int:
# nums = sorted(nums)
# i = len(nums)//2
# return nums[i] if nums[i] == nums[i+1] else nums[i-1]
# found = set()
# for num in nums:
# if num in found:
# return num
# found.add(num)
# return -1
n = len(nums)
# 最多间隔两个元素
for gap in range(1,4):
for i in range(n-gap):
if nums[i] == nums[i+gap]:
return nums[i]
return -1
1207. 独一无二的出现次数
题目链接:1207. 独一无二的出现次数
题目大意:给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。
如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。
注意:(1)1 <= arr.length <= 1000;(2)-1000 <= arr[i] <= 1000。
例如:
输入:arr = [1,2,2,1,1,3]
输出:true
解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。
输入:arr = [1,2]
输出:false
输入:arr = [-3,0,1,-3,1,1,1,-3,10,0]
输出:true
- 解题思路:使用Counter和defaultdict
- 时间复杂度: O ( n ) O(n) O(n) n为数组arr的长度
- 空间复杂度: O ( n ) O(n) O(n)
class Solution:
def uniqueOccurrences(self, arr: List[int]) -> bool:
cnt = collections.Counter(arr)
d = collections.defaultdict(list)
ans = []
for i in cnt:
d[cnt[i]].append(i)
if len(d[cnt[i]])>1:
return False
return False
总结
努力 奋斗!找工作。