MySQL 索引(基础篇)
你好,我是悟空。
本文目录如下:
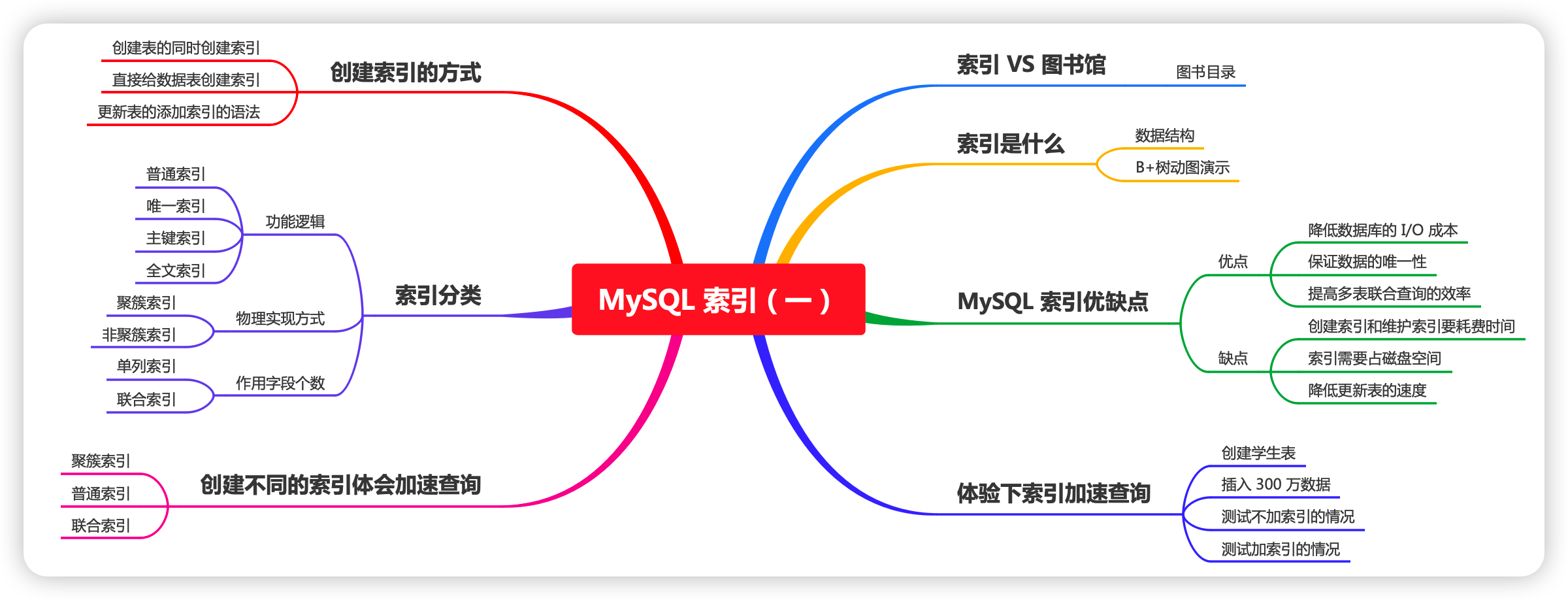
一、前言
最近在梳理 MySQL 核心知识,刚好梳理到了 MySQL 索引相关的知识,我的文章风格很多都是原理 + 实战的方式带你去了解知识点,所以本篇也是。
当然,索引的知识点还是很多的,本篇是对索引的基础知识进行讲解,不涉及索引的底层原理,以及未涉及到如何查看执行计划,将会分成多篇进行讲解,请持续关注~
二、索引 VS 图书馆

设想一种场景,你现在是一名图书管理员,每天的工作就是将归还的书放回原位。如果有人想找某本书,则可以先通过书的分类、书号等,找到书所在的书架位置,进一步缩小了范围。
假如图书馆没有图书管理员,书架上的书是无规律摆放的,那么有人想找一本书,就只能从头开始找了,找不找得到完全靠运气了。
如果你去过图书馆,应该会知道图书馆的检索系统。图书馆为图书准备了检索目录,包括书名、书号、对应的位置信息,包括在哪个区、哪个书架、哪一层。我们可以通过书名或书号,快速获知书的位置,拿到需要的书。
MySQL 中的索引,就相当于图书馆的检索目录,它是帮助 MySQL 系统快速检索数据的一种存储结构。我们可以在索引中按照查询条件,检索索引字段的值,然后快速定位数据记录的位置,这样就不需要遍历整个数据表了。而且,数据表中的字段越多,表中数据记录越多,速度提升越是明显。
三、索引是什么
索引它的英文名是 Index,它是一种数据结构。
数据结构是计算机存储、组织数据的方式。一种好的数据结构可以带来更高的运行或者存储效率。数据在内存中是呈线性排列的,但是我们可以使用指针等道具,构造出类似“树形”的复杂结构。
数据结构按线性和非线性分为两大类,八大种,比如线性数据结构的就有 数组、链表、栈、队列。
非线性的数据结构就有,树、堆、散列表、图等等。
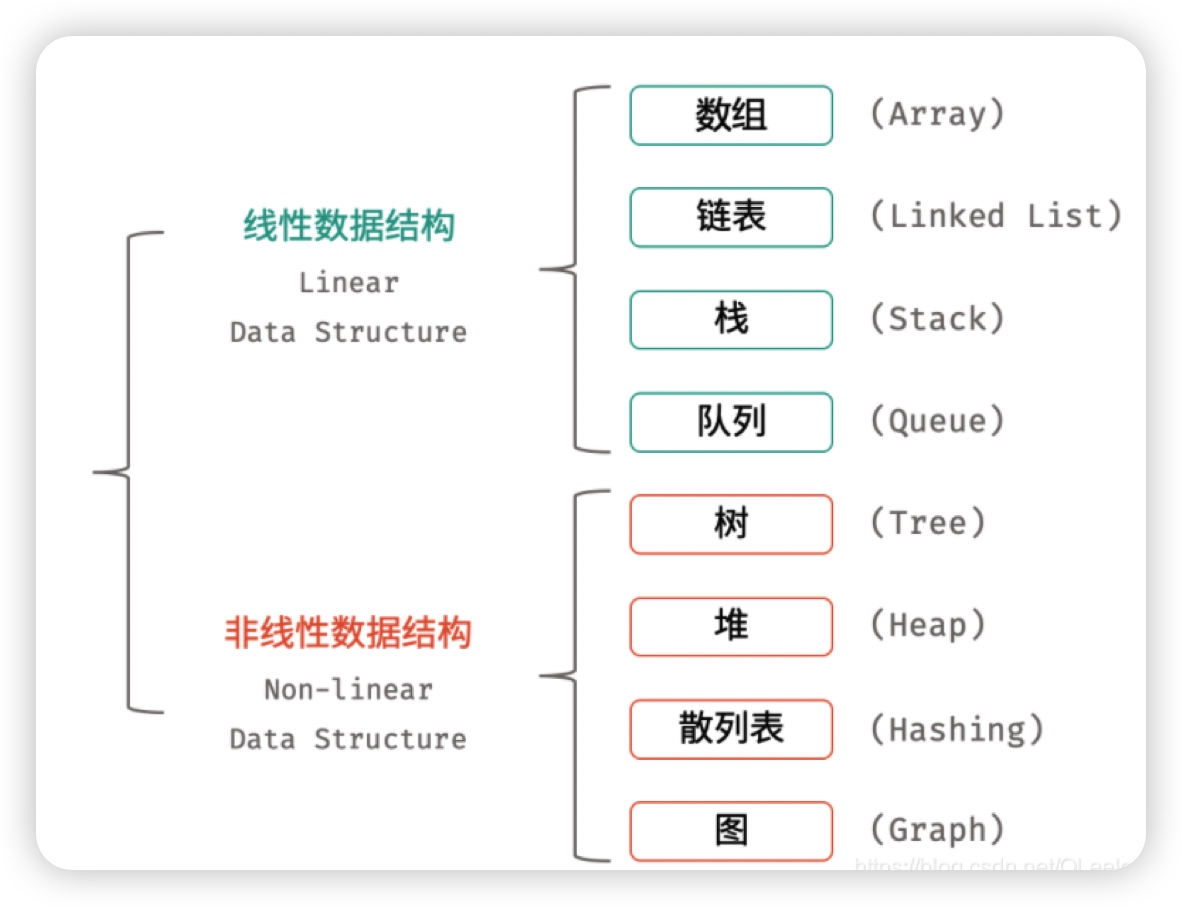
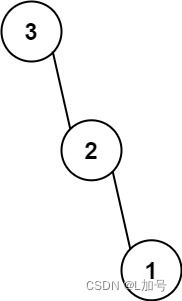
那 MySQL 中的索引是其中哪一种呢?它是一种树型数据结构,而且是 B+ 树,如下图所示,不过图中的树是一种倒着的树,它的根在最上面。
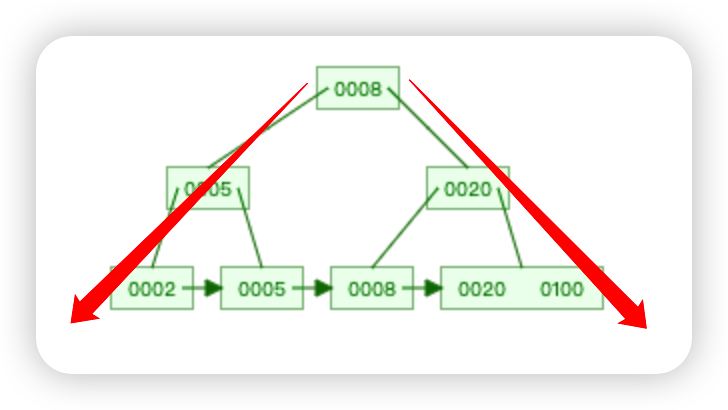
那 B+ 树是如何存储数据的呢?
我们可以打开这个网站看下。
设想下我们往一张数据表中随机插入一些数字:
2、5、8、100、20
类似我们将图书馆的书随机摆放到书架中,然后我们来通过动图演示的方式看下 B+ 树是如何按照它的数据结构来存放、查找和删除这些数字的。
四、MySQL 索引的优缺点
优点
降低数据库的 I/O 成本
这里其实就是减少数据库读写数据的花费的时间。
假如让你从一堆杂乱中的书中找一本指定的书,是不是得一本一本的看下封面上写的书名是不是对的,
有了索引,就不需要对每本书都翻看封面了,可以快速到那本书,减少了很多无效的查找。
保证数据的唯一性
通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。注意这里是唯一索引,通过关键字 UNIQUE 来创建唯一索引。
比如说员工表中的每个员工 id 都是唯一的。
提高多表联合查询的效率
不论是单表查询,还是多表查询,索引都是提高查询效率的。
任何事物都有其两面性,索引有优点,必定也会有缺点,那索引有什么缺点呢?
缺点
创建索引和维护索引要耗费时间
就好比图书馆借书和还书都是需要图书管理员来的维护,如果长期没人管,图书不就又乱了吗?
索引需要占磁盘空间
就好比图书馆对每本书的位置信息都是需要存放到一份数据里面的,如果是存放到电脑里面,就会占用电脑的硬盘空间,如果是用纸质文档来存储,则会占用房间的空间。
降低更新表的速度
就好比图书馆将新出的书放到书架之前,管理员是需要先查询下这本书的所属位置,再去放到书架上,这个查询的过程就会耗费一定的时间。
五、体验下索引加速查询
前面说了索引的优点很多,最主要的原因是提高查询速度。那我们就来看下不加索引和加索引两种场景下的查询速度。
首先你得创建一张表吧,然后往表里插入很多数据,对吧?
创建学生表
我这里创建了一张学生表:

字段说明:
- id:这条记录的 id,也是主键 id,具有唯一性,也就是说每条记录都是唯一的。
- stu_no:学生编号,插入样本数据时为自增的数字
- stu_name:学生姓名,插入样本数据时为随机的英文字母组合
- age:学生年龄,插入样本数据时会随机分布年龄
- classId:班级 id,插入样本数据时会随机分布班级 id。
插入 300 万数据
现在表创建好了,就需要往表里面插入大量数据了,这里我就直接用写好的脚本插入 300 万数据。

测试不加索引的情况
那如果我想根据某个学生编号stu_no来找到学生的记录该怎么查询呢?
查询脚本如下:

现在 student 表是没有添加索引的,来看下它的查询速度吧。
如何去统计脚本执行所花的时间呢?因为我现在用的是 workbench 图形化管理工具,所以可以借助这款工具来看执行时间:
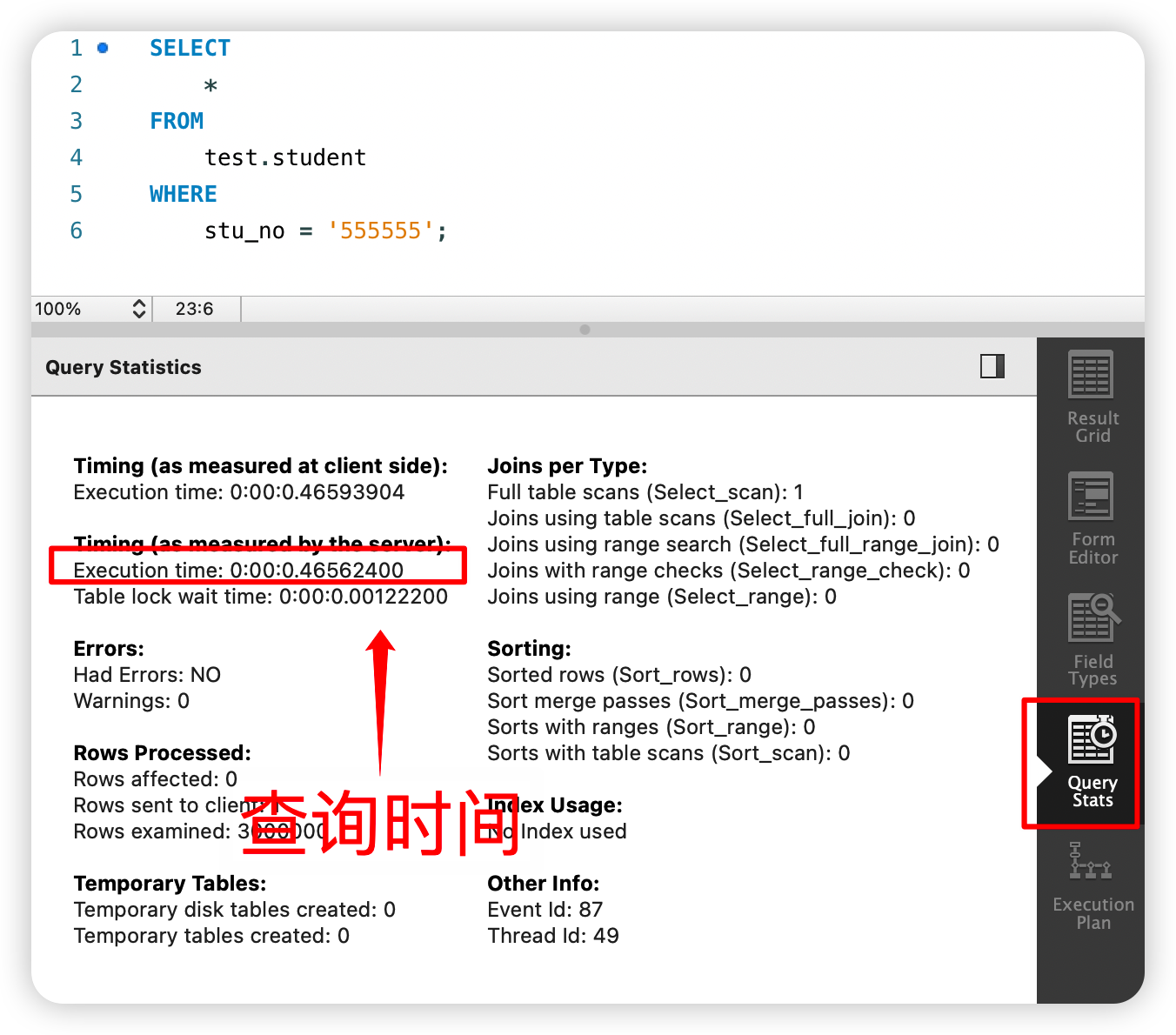
可以看到查询这条数据用了 0.47s 时间,从查询计划中也可以看到这个查询是全表扫描了,也就是说查询 stu_no = '555555'这条记录是从记录的第一行开始,一行一行扫描,看下哪条记录的stu_no = '555555',这种查询方式是很慢很慢的,尤其是要要从这么大的数据量来中找。

测试加索引的情况
添加索引
如果我们这个要查询的字段 stu_no 加上索引会发生什么事情呢?
加索引的方式可以直接通过 workbench 工具或者通过脚本。
workbench 工具添加索引

脚本添加索引
ALTER TABLE `test`.`student`
ADD INDEX `index_stu_no` (`stu_no` ASC) VISIBLE;
测试添加索引后的查询速度
加了索引后,查询只需要 0.0013s,如下图所示:

再来看下它的执行计划:

可以看到利用了索引查找,通过索引直接定位到那一行数据。
有了索引之后,MySQL 在执行 SQL 语句的时候多了一种优化的手段。
也就是说,在查询的时候,可以先通过查询索引快速定位,然后再找到对应的数据进行读取,这样就大大提高了查询的速度。
六、创建索引的方式
在工作中,我们一般都是写好创建索引的 SQL 脚本,然后将脚本提交到代码仓库。这样更方便维护 SQL 脚本和索引。
那创建索引的脚本是怎么样的呢?有没有语法要求?
创建索引的语法
创建索引有三种方式:
创建表的同时创建索引
语法:
CREATE TABLE 表名(
字段 数据类型,
字段 数据类型,
...
{ INDEX | KEY } 索引名 (字段1,字段2,...)
)
示例:创建 member 表的同时创建一个索引 uk_idx_id,字段是 id。
CREATE TABLE member (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
INDEX uk_idx_id (id)
);
直接给数据表创建索引
语法:
CREATE INDEX 索引名 ON 表名 (
字段1,字段2,...
);
示例:创建一个索引 index_name,字段为 name。
CREATE INDEX index_name ON member (
name
);
更新表的添加索引的语法
ALTER TABLE 表名
ADD { INDEX | KEY } 索引名 (字段1,字段2,...);
示例:创建一个联合索引 index_id_name,字段为 id 和 name。
ALTER TABLE member
ADD INDEX index_id_name (id, name);
七、索引分类
MySQL的索引包括普通索引、唯一性索引、全文索引、单列索引、多列索引和空间索引等。
从 功能逻辑上说,索引主要有 4 种,分别是普通索引、唯一索引、主键索引、全文索引。
按照 物理实现方式 ,索引可以分为 2 种:聚簇索引和非聚簇索引。
按照 作用字段个数 进行划分,分成单列索引和联合索引。
聚簇索引(主键索引)特点
- 主键作为索引,B+树的 叶子节点 存储的是完整的用户记录
非聚簇索引(二级索引、辅助索引)特点
回表查询:先到普通索引上定位主键值,再到聚集索引上定位行记录,它的性能较扫一遍索引树低(一般情况下)。
详细说明:
一般我们自己建的索引不管是单列索引还是联合索引,都称为普通索引,相对应的另外一种就是聚簇索引。 每个普通索引就对应着一颗独立的索引B+树,索引 B+ 树的节点仅仅包含了索引里的几个字段的值以及主键值。
根据索引树按照条件找到了需要的数据,仅仅是索引里的几个字段的值和主键值,如果用 select * 则还需要很多其他的字段,就得走一个回表操作,根据主键再到主键的聚簇索引里去找,聚簇索引的叶子节点是数据页,找到数据页里才能把一行数据的所有字段值提取出来。
假设有 select * from table order by a,b,c 的语句,(table 有 abcdef 6 个字段),首先得从联合索引的索引树里按照顺序 a、b、c 取出来所有数据,接着对每一条数据都根据主键到聚簇索引的查找,其实性能不高。
联合索引(二级索引,组合索引)特点
- 同时为多个列建立索引。
八、创建不同的索引体会加速查询
创建聚簇索引体会加速查询
我们之前创建 student 表的同时添加了以 id 为索引字段的主键索引(聚簇索引),所以看下使用主键 id 来查询的速度怎么样。如果你之前对这个表没有添加过主键索引,可以通过这个脚本添加:
# id 不为空,自增长主键,自动添加聚簇索引
ALTER TABLE `test`.`student`
CHANGE COLUMN `id` `id` INT NOT NULL AUTO_INCREMENT ,
ADD PRIMARY KEY (`id`);

执行计划中可以看到是直接用的 constant 方式,说明查询直接找到了那条记录,速度是非常快的。
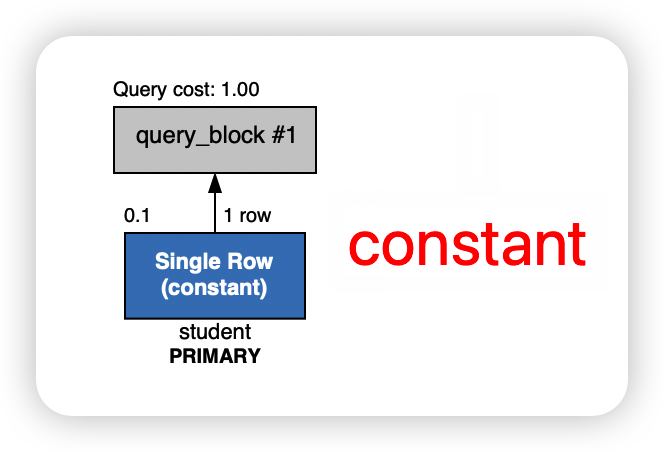
然后我们把主键索引删除之后,再看下查询用时。
先删除主键索引:
ALTER TABLE `test`.`student`
CHANGE COLUMN `id` `id` INT NOT NULL,
DROP PRIMARY KEY;
查询耗时 0.6 秒。
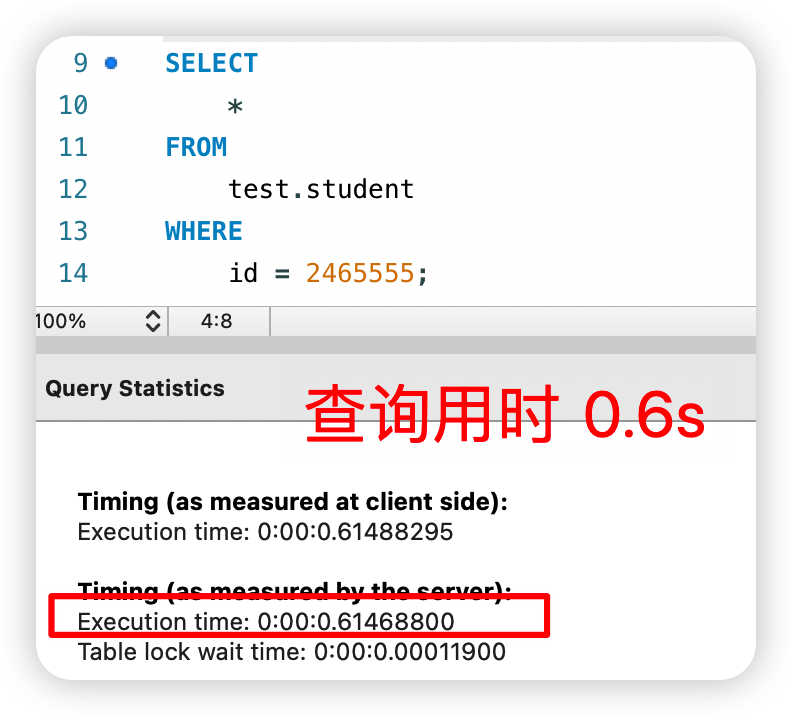
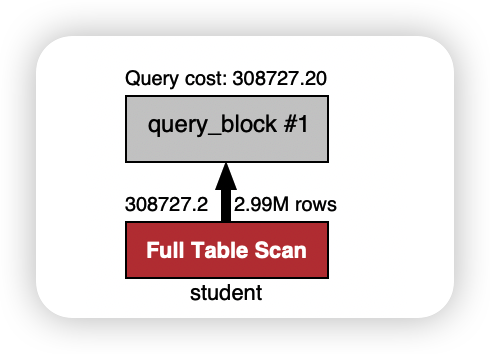
而且查看执行计划是全表扫描,这种查询方式非常耗时。
创建普通索引体会加速查询
在本文中的第 5 小节已经通过在 stu_no 学生编号上创建普通索引来演示查询效果了,索引也是加速了查询。
创建联合索引体会加速查询
不加索引的情况下,查询 年龄=15,班级 id = 20 的学生,用时 0.46 秒。
在 student 表上的 age 和 classId 字段创建了一个联合索引:
CREATE INDEX index_age_class_id ON test.student (
age,
classId
);
查询语句:
SELECT
*
FROM
test.student
WHERE
age = 15 AND classId = 20;
耗时 0.014 秒。
0.46 秒降低到 0.014 秒,速度提升了 30 倍。
总结
本篇讲解了 MySQL 的索引是什么,优缺点,MySQL 索引分类,以及如何通过脚本创建 MySQL 索引,最后通过演示不同类型的索引如何加速查询。
下一篇 MySQL 文章我们接着聊 MySQL 索引。