文章目录
- 一、噪声数据
- 1.1 分箱
- 1.2 回归
- 1.3 聚类
- 1.4 其他
- 二、数据清理作为一个过程
- 2.1 偏差检测
- 2.1.1 使用“元数据”:关于数据的数据
- 2.1.2 编码格式:存在使用不一致、数据表示不一致
- 2.1.3 字段过载
- 2.1.4 唯一性规则
- 2.1.5 连续性规则
- 2.1.6 空值规则
- 2.2 数据变换(纠正偏差)
- 2.3 迭代
- 2.4 加强交互性
- 三、数据集成和变换
- 3.1 数据集成
- 3.2 数据变换
- 3.3 规范化
- 3.3.1 Min-Max 规范化(最小-最大规范化)
- 3.3.2 Min-Max 规范化(最小-最大规范化)例子代码(红酒数据集)
- 3.2.3 缺点
- 3.3 Score 规范化(零-均值规范化)
- 3.3.1 Score 规范化(零-均值规范化)例子代码(红酒数据集)
一、噪声数据
噪声数据(Noisy Data)就是无意义的数据,这个词通常作为损坏数据的同义词使用。
1.1 分箱
通过考察数据的“近邻”(周围的值)来光滑有序数据的值。局部光滑。
- 划分:等频、等宽
- 光滑:用箱均值、用箱中位数、用箱边界(去替换箱中的每个数据)
- 箱中的最大和最小值被视为箱边界。箱中的每一个值都被最近的边界值替换
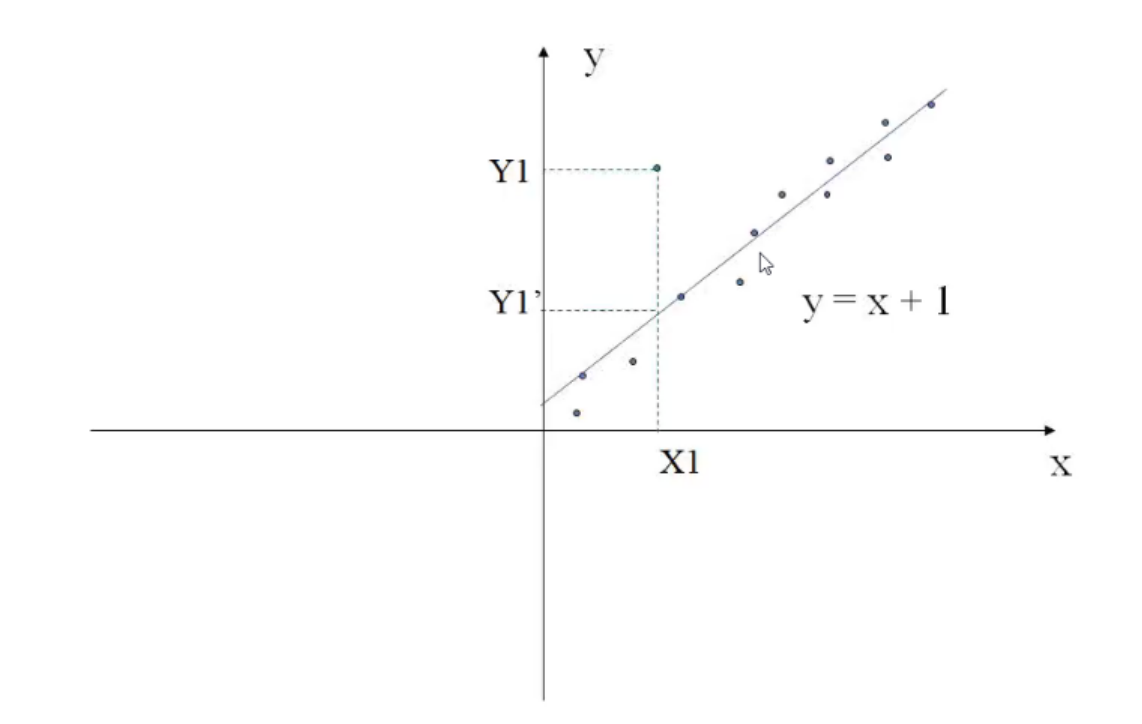
1.2 回归
用一个函数(回归函数)拟合数据来光滑数据。
- 线性回归
- 多元线性回归
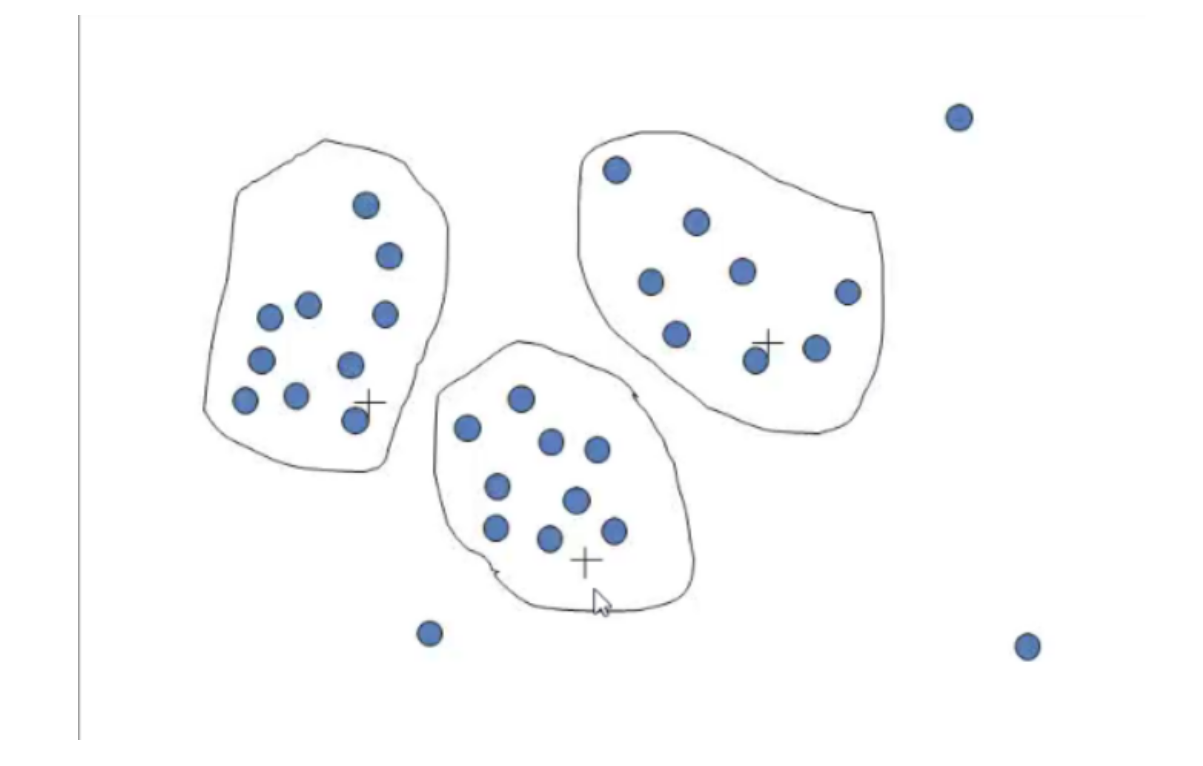
1.3 聚类
将类似的值聚集为簇 A A A。
噪声数据是有益处的。
1.4 其他
如数据归约、离散化和概念分层。
二、数据清理作为一个过程
2.1 偏差检测
2.1.1 使用“元数据”:关于数据的数据
例如,每个属性的数据类型是什么?定义域是什么?
2.1.2 编码格式:存在使用不一致、数据表示不一致
例如:日期“2015/12/08”和”08/12/2015"
2.1.3 字段过载
新属性的定义挤进已定义的属性的未使用(位)部分
2.1.4 唯一性规则
给定属性的每个值都必须不同于该属性的其他值
2.1.5 连续性规则
属性的最低值和最高值之间没有缺失的值,并且所有的值还必须是唯一的(例如,检验数)
2.1.6 空值规则
说明空白、问号、特殊符号或指示空值条件的其他串的使用(例如,一个给定属性的值何处不能用),以及如何处理这样的值
2.2 数据变换(纠正偏差)
- 数据清洗工具:使用简单的领域知识(邮政地址知识和拼写检查),检查并纠正数据中的错误。在清理多个数据源的数据时,这些工具依赖分析和模糊匹配技术。
- 数据审计工具:通过分析数据发现规则和联系,并检测违反这些条件的数据来发现偏差。
- 数据迁移工具:允许说明简单的变换。
- ETL(提取/变换/装入)工具:允许用户通过图形用户界面说明变换。
- 通常这些工具只支持有限的变换。
2.3 迭代
- 需要迭代执行偏差检测和数据变换(纠正偏差)这两步过程。
- 通常需要多次迭代才能达到满意的效果。
2.4 加强交互性
- 数据清理工具:kettle 是一个开源的数据清理工具
- 开发数据变换操作规范说明语言
三、数据集成和变换
- 数据集成合并多个数据源中的数据,存放在一个一致的数据库(如数据仓库)中。
- 源数据可能包括多个数据库,数据立方或一般文件。
- 数据变换将数据转换或统一成适合于挖掘的形式。
3.1 数据集成
- 实体识别:元数据可帮助避免错误
- 属性冗余与相关性分析:相关分析
- 数据重复(元组冗余)
- 数据值冲突的检测与处理:表示、比例或编码不同
3.2 数据变换
- 平滑:去掉数据中的噪声。技术包括分箱、回归、聚类。
- 聚集 Aggregation:对数据进行汇总或聚集。
- 数据泛化(概化):使用概念分层,用高层概念替换低层或“原始”数据。
- 规范化:将属性数据按比例缩放,使之落入一个小的特定区间。最小-最大、Z-Score、按小数定标规范化。
- 属性构造(特征构造):由给定的属性构造新的属性并添加到属性集中,以帮助挖掘过程。可以帮助提高准确率和对高维数据结构的理解。
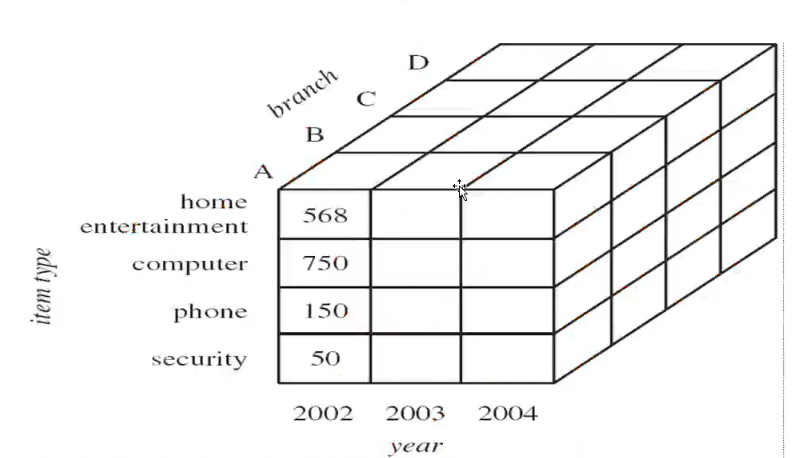
数据立方体聚集:
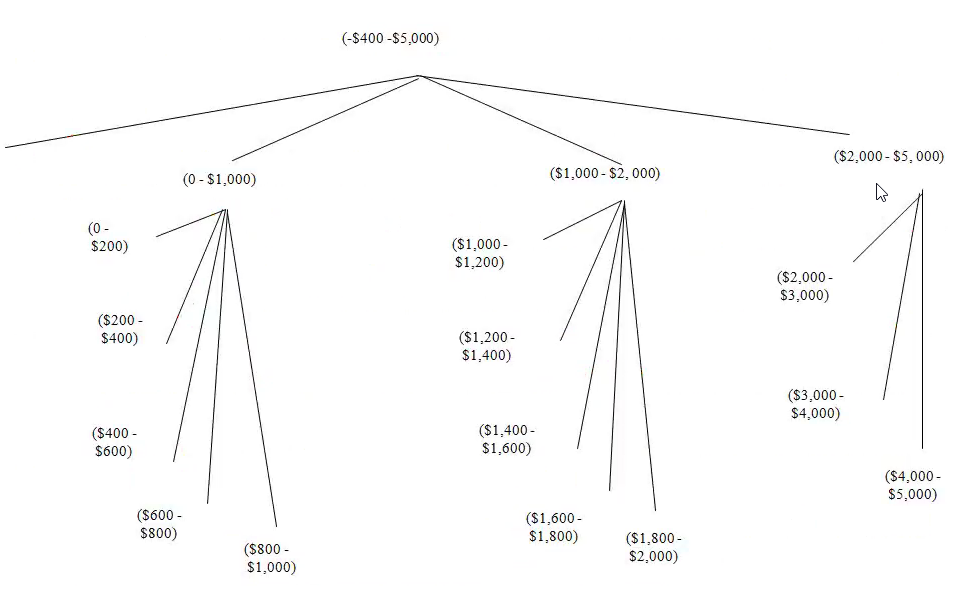
概念分层:

3.3 规范化
3.3.1 Min-Max 规范化(最小-最大规范化)
规范化公式:
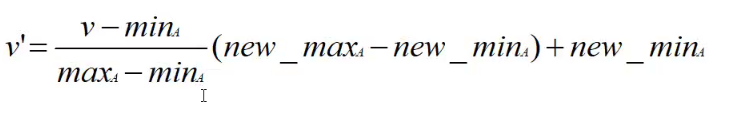
3.3.2 Min-Max 规范化(最小-最大规范化)例子代码(红酒数据集)
- 事先准备,采用红酒数据集,将数据拿出:
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.datasets import load_wine
wine = load_wine()
X = wine.data
y = wine.target
- 支持向量机
from sklearn import svm
svm = svm.SVC()
- 支持向量机 training score:
print("支持向量机 training score: ",svm.score(X,y))
svm.fit(wine_X,y)
运行结果为:

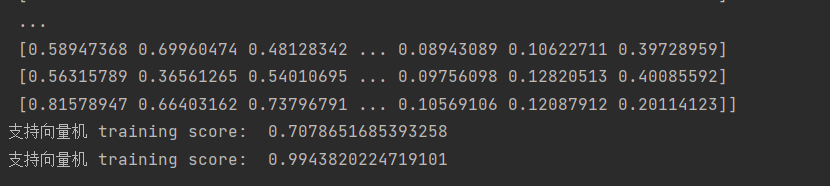
- 手动让其进行 Min-Max 规范化(最小-最大规范化):
wind_X=X.copy()
for i in range(13):
columu_X = X[:, i]
wind_X[:, i] = (columu_X-columu_X.min())/(columu_X.max()-columu_X.min())
print(wind_X)
- 对照组,输出之前的训练得分:
svm.fit(X,y)
print("支持向量机 training score: ",svm.score(X,y))
- 支持向量机归一化后 training score:
svm.fit(wind_X,y)
print("支持向量机归一化后 training score: ",svm.score(wind_X,y))
- 结果:可以看出,对其改善很大:
3.2.3 缺点
- 若存在离群点,可能影响规范化
- 若在规范化后添加新的数据,当新数据落在原数据的区间[min A, max A ]之外,将导致“越界”错误
3.3 Score 规范化(零-均值规范化)
z-score 规范化(零均值规范化):属性 A A A 的值基于 A A A 的平均值和标准差规范化。

对离群点不敏感。
3.3.1 Score 规范化(零-均值规范化)例子代码(红酒数据集)
- 事先准备,采用红酒数据集,将数据拿出:
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.datasets import load_wine
wine = load_wine()
X = wine.data
y = wine.target
- 支持向量机
from sklearn import svm
svm = svm.SVC()
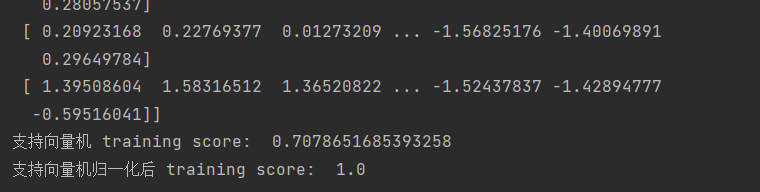
- 使用模型里的按列归一化:
from sklearn import preprocessing
#数据预处理:按列归一化
wine_X=preprocessing.scale(X)
print(wine_X)
- 输出结果为:
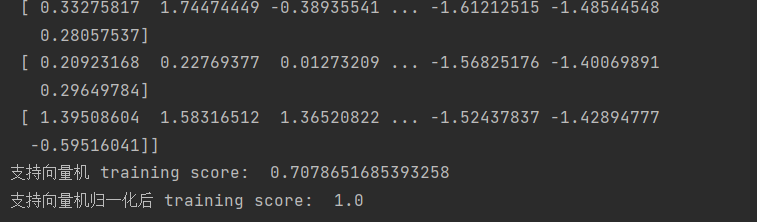
- 手动撰写按列归一化
wind_X=X.copy()
for i in range(13):
columu_X = X[:, i]
wind_X[:, i]=(columu_X-columu_X.mean())/columu_X.std()
print(wind_X)563
结果查看:

![3.知识图谱概念和相关技术简介[知识抽取、知识融合、知识推理方法简述],典型应用案例介绍国内落地产品介绍。一份完整的入门指南,带你快速掌握KG知识,芜湖起飞!](https://img-blog.csdnimg.cn/190ddc3c7454438ea0ffd435c81f9423.png)