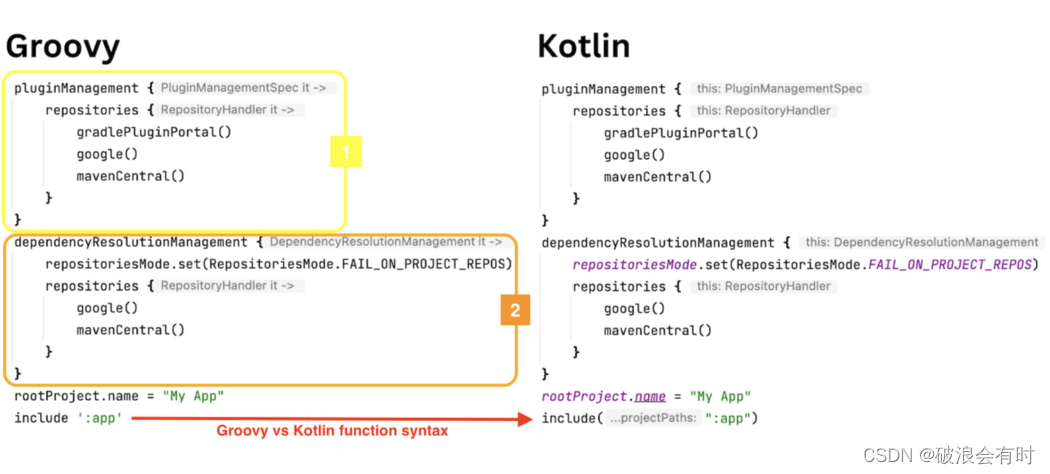
本文将带领大家亲手实现一个垃圾信息过滤的算法。
在正式讲解算法之前,最重要的是对整个任务有一个全面的认识,包括算法的输入和输出、可能会用到的技术,以及技术大致的流程。
本任务的目标是去识别一条短信是否为垃圾信息,即输入为一条文本信息,输出为二分类的分类结果。2002年,Paul Graham提出使用“贝叶斯推断”过滤垃圾邮件。1000封垃圾邮件可以过滤掉995封,且没有一个误判。另外,这种过滤器还具有自我学习的功能,会根据新收到的邮件,不断调整。收到的垃圾邮件越多,它的准确率就越高。
朴素贝叶斯算法是一种有监督的机器学习算法,即算法的实现包含了构建训练集、数据预处理、训练、在测试集上验证等步骤。在下文中首先介绍算法的理论基础,再逐一介绍代码实现算法的整个流程。
01、算法流程
算法的第一步是收集两组带有标签的信息训练集,正常信息和垃圾信息。接下来根据训练集计算概率。训练集越大,最终计算的概率精度越高,分类效果也会越好。具体来说,训练过程包含以下两步
1●解析训练集中所有信息,并提取每一个词。
2●统计每一个词出现在正常信息和垃圾信息的词频
根据这个初步统计结果可以实现一个垃圾信息的鉴别器。对于一个新的样本输入,可以提取每一个词并根据前面给出的贝叶斯公式进行计算,最终得到分类结果。下面对一个简单的样例进行手工模拟ÿ