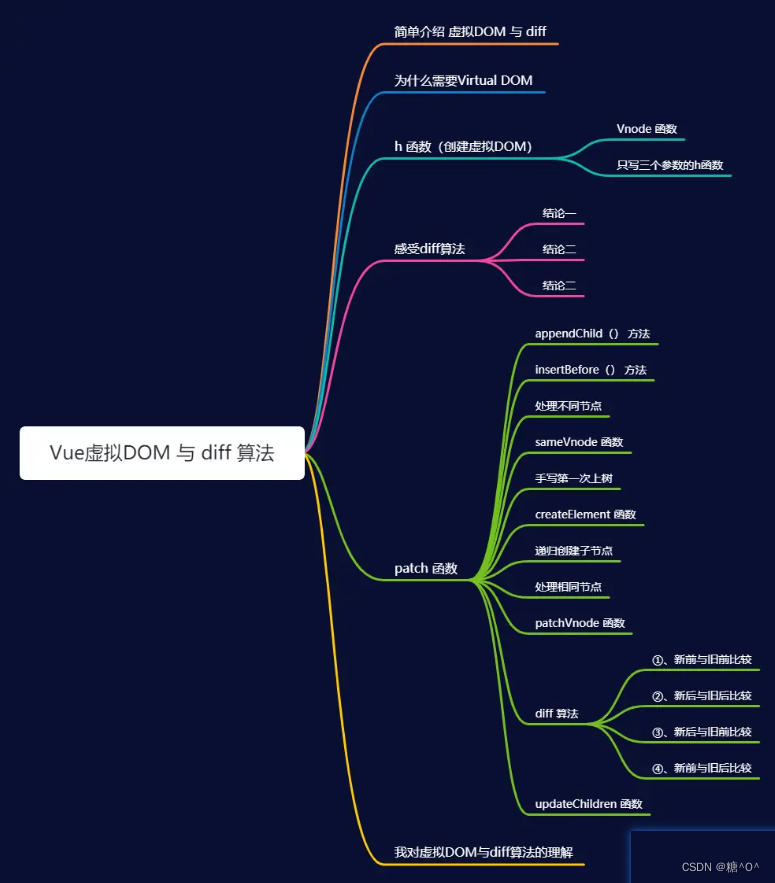
nested 类型???
_all
_routing;
ES-mapping
Elasticsearch根据业务创建映射mapping结构分析:keyword和text(一)_elasticsearch keyword mapping_周全全的博客-CSDN博客
0.Mapping样例
{
"mappings":{
"_doc":{
"_all":{
"enabled":false #默认情况,ElasticSarch自动使用_all所有的文档的域都会被加到_all中进行索引。可以使用"_all" : {"enabled":false} 开关禁用它。如果某个域不希望被加到_all中,可以使用"include_in_all":false关闭
},
"properties":{
"uuid":{
"type":"text",
"copy_to":"_search_all", #对应_search_all字段,可以对其进行全文检索
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150 #ignore_above 默认值是256,当字段文本的长度大于指定值时,不做倒排索引。
}
}
},
"name":{
"type":"text",
"copy_to":"_search_all",
"analyzer":"ik_max_word", # ik_max_word 插件会最细粒度分词
"search_analyzer":"ik_smart", # ik_smart 粗粒度分词
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150
}
}
},
"dt_from_explode_time":{
"type":"date",
"copy_to":"_search_all",
"format":"strict_date_optional_time||epoch_millis"
},
"_search_all":{
"type":"text"
}
},
"date_detection":false, #关闭日期自动检测,如果开启,会对于设置为日期格式的字段进行判断
"dynamic_templates":[ #用于自定义在动态添加field的时候自动给field设置的数据类型
{
"strings":{
"match_mapping_type":"string",
"mapping":{
"type":"text",
"copy_to":"_search_all",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150
}
}
}
}
}
]
}
},
"settings":{
"index":{
"number_of_shards":6, #分片数量
"number_of_replicas":1 #副本数量
}
}
}
1.什么是Mapping
Elasticsearch mapping_Aska小强的博客-CSDN博客
Mapping 类似 mysql 中的 schema 的定义,就是定义索引属性字段的
定义索引中字段的名称
定义索引中字段的数据类型 , 如 text , long , keyword....
定义索引中字段的的倒排索引相关配置 ( Analyzer...)
一个Mapping 属于一个索引的Type
每个文档都属于一个Type
一个Type有一个Mapping 定义
es7.0开始, 在Mapping中不需要指定 Type信息, 因为7.0之后只有_doc Type
1.1es 自动创建mapping
当我们去创建一个 索引的时候 未指定 mapping , es会默认帮这个索引创建一个 mapping
创建一个 索引并且索引一条数据
2.手动创建mapping时考虑:
1. 是否参与搜索:即是否用于索引,index = false
2.即是否需要分词|| 是否需要聚合、排序:即具体的类型 是否为keyword
3.如果分词,分词器是什么 :例如analyzer = "ik_max_word"
4.数值类型是否需要 设置index 以及 是否需要改成keyword
3.Mapping数据类型:
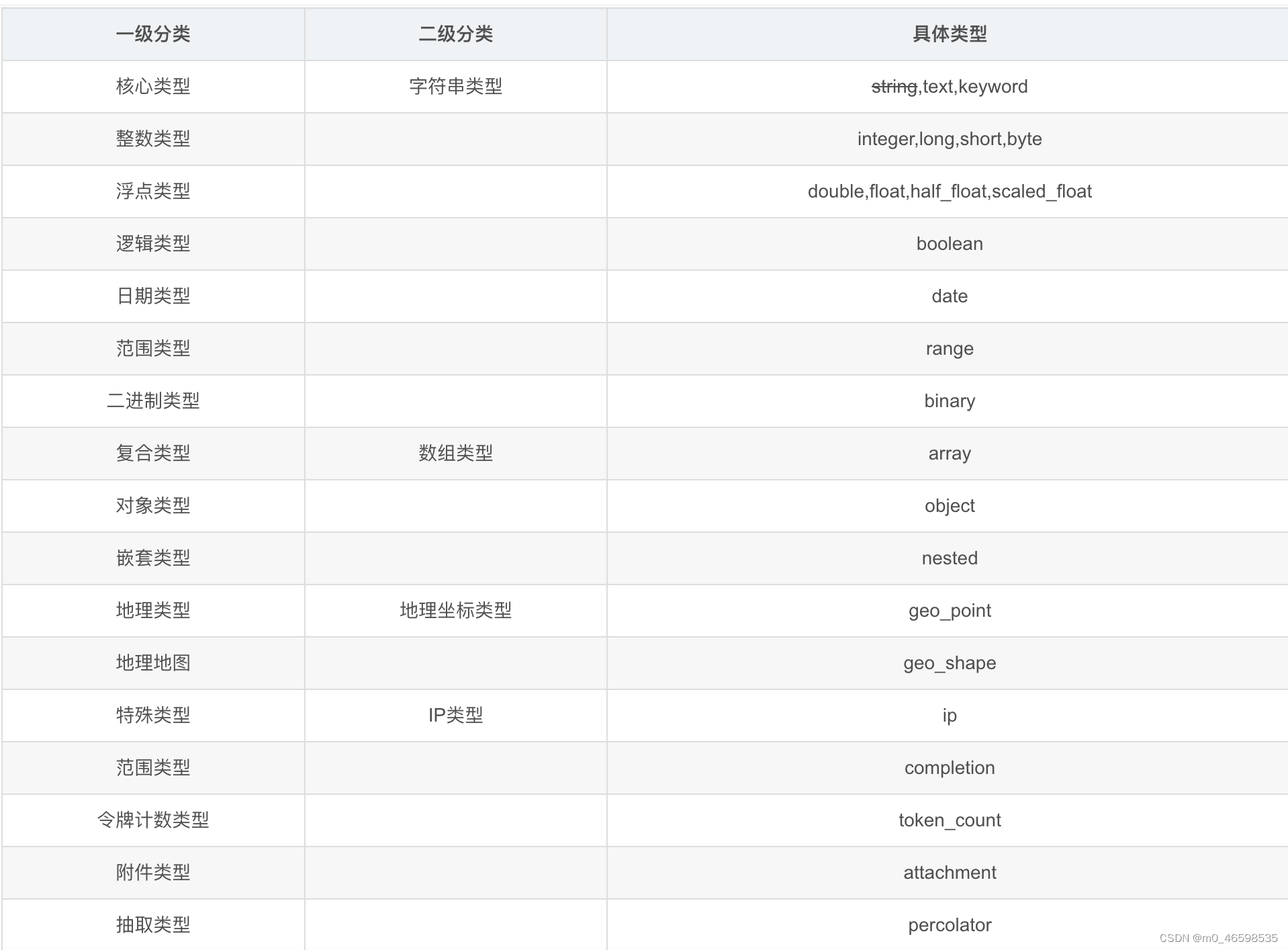
3.1重要数据类型说明:
keyword:
存储:存储数据的时候,不会分词建立索引,而是直接一整个丢到倒排索引中
使用场景:用于聚合、排序和术语级查询(如 term),所以避免参与全文检索。
作用:keyword不支持分词查询 ,但text支持;
text字段类型:
存储:存储数据的时候,会分词建立索引
使用场景:用于全文内容,例如电子邮件正文或产品说明,并且es会通过分析器对字符串进行分词,可以在全文检索中搜索单独的单词。文本字段最适合非结构化但可读的内容并且不用于排序,也很少用于聚合。
作用:text类型无法聚合查询
4.Mapping属性设置
mapping 属性设置analyzer 分词器
默认分词器 standard , 它会把中文一个个拆开,肯定是不适合的,如果是索引中文的信息, 需要设置字段的分词器,
mapping 属性设置 index
通过给 属性设置 index 来控制该 字段是否 参与 索引, 默认 true , 如果index 设置为false 那么 不能记录索引 并且不可以搜索
mapping 设置 属性 null_value 默认值
null_value:当字段遇到null值时候的处理策略(字段为null时候是不能被搜索的,也就是说,text类型的字段不能使用该属性,可以使用在keyword 字段上),设置该值后可以用你设置的值替换null值,这点可类比mysql中的"default"设置默认值, 但是也有点不一样, 后续就可以
使用你设置的这个 null_value 去搜索, 但是检索出来的数据_source 中 还是展示 null
mapping 属性设置 boost 权重
在es搜索的时候 会有一个相关性算分的过程 , 如果不设置 每个字段的默认boost 权重为1.0 , 如果希望加大 按照广告投放金额的分 那么可以设置boost 以提高搜索 自然就排在前面了
mapping 设置 dynamic
关闭动态mapping:
PUT order_es_index/_settings
{
"index.mapper.dynamic":false
}
dynamic 是否允许动态新增字段
true : 允许动态新增字段 同时mapping 被更新 文档可被索引
false: 不允许动态新增字段 , mapping 不会被更新, 字段不能被索引, 但是数据可以入库并且信息会出现在 _source 中
strict : 不允许写入, 直接报错
对于已经存在的字段 一旦又数据写入,就不能进行修改字段定义了,因为 底层Lucene不允许修改, 如果希望修改字段类型,必须 reindex 重建索引