本章将开始探讨JDK中的HashMap,包括HashMap如何避免和解决上一章所说的散列冲突问题,以及Java 8对HashMap的改进
避免散列冲突- 散列函数设计
String.hashcode()
Object.hashCode()方法用于返回当前对象的散列值。Object类中也约定了,重写了equals也要重写hashcode,相同对象必须有相同哈希码。
以常见的String类的hashcode()为例,会有一个固定值31,在for循环中会结合每一位字符的ASCII码计算出最终的hashcode
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
这里String用的哈希函数是一个叫做DJBX33A算法的变种
这里的乘子用一个固定值31的好处:
- 之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)
- 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5)- i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
- 另外,一些实验证明,31是个不大不小的质数,碰撞概率很小
因此,String类hashcode的实现兼顾了散列函数的随机性和性能
扰动函数HashMap.hash()
假如用String作为hashmap的key,计算出hashcode后,并没有直接根据数组长度取模,而是先将key传入扰动函数hash()
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
hashmap为什么使用扰动函数对hashcode的上半区和下半区异或:
- 首先提一下,hashMap的长度必须是2的幂,这样hash%length就会转换为hash&(length-1),计算更加高效,
- 而Java假设length一般很少超过2^16(65536),因此计算索引:hash&(length-1),hash值参与运算的部分一般只有低16位,导致高16位信息丢失,为了提高最终索引值随机性,让高16位也参与运算,扰动的办法就是hashcode高16位和低16位进行运算
- 为什么用异或呢,因为用&或者|都会让结果趋向于0或1,反而不平均了
- **怎么验证随机性呢??**用实验的方式,比如准备10万个单词,分别用加扰动和不加扰动的方式,插入到一个长度为128(2次幂)的hashmap中,看看每个索引下对应的单词数量。如果所有单词。可以画出折线图看看,如果所有单词在每个索引下分配的比较平均,就说明随机性强。随机性强也是为了尽量减少hash碰撞。
避免散列冲突-负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
在HashMap中,负载因子决定了数据量多少了以后进行扩容。这里要提到上面做的HashMap例子,我们准备了7个元素,但是最后还有3个位置空余,2个位置存放了2个元素*。* 所以可能即使你数据比数组容量大时也是不一定能正正好好的把数组占满的,而是在某些小标位置出现了大量的碰撞,只能在同一个位置用链表存放,那么这样就失去了Map数组的性能
要选择一个合理的大小下进行扩容,默认值0.75就是说当阀值容量占了3/4时赶紧扩容,减少Hash碰撞。
解决散列冲突 - 链表 + 红黑树
HashMap解决散列冲突的方法是上一章中提到的拉链法(链表法)
在Java 8之前,HashMap只使用了链表来解决哈希冲突。
但是,由于链表长度增长过长会导致查找效率变低,因此在Java 8中添加了红黑树的支持来解决这个问题。当链表长度超过8时,HashMap将使用红黑树代替链表,这样能够提高HashMap的性能。
如果红黑树中节点的数量降到一定数量以下(Java 8中为6个),它将退化为链表。这是因为红黑树节点包含额外的指针和颜色标记,当节点数较少时,这些额外开销可能会变得更加显著,而链表占用的空间更少,也更容易遍历。
这种自动调整的特性使得HashMap能够在不同负载下保持良好的性能和空间使用率。
Java8对HashMap的修改
这部分将尽可能解释每种修改的背后原因
数据结构的改变
前面也提到过:Java8之前的数据结构数组+链表,而Java8之后是数组+链表/红黑树,显然是对于性能的考虑
更简单的hash()方法
前面我们提到过扰动函数能够让最终的hash值更加随机,但实际上Java8之前的扰动函数hash()更加复杂:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
关于这一点改变我目前也没有在权威资料中查到原因,不过这篇回答中对此进行了一个合理猜测:
https://stackoverflow.com/questions/24673567/change-to-hashmap-hash-function-in-java-8
简单来说就是个tradeoff:更复杂的hash()方法、更随机的散列值 vs 更高效的hash()方法、更好的性能
有可能是官方发现后者带来的好处更大,所以放弃了更为复杂的hash()方法
其实回答里也提到了:假如key的hashcode()方法已经能生成高质量的散列值(例如String),那hash()方法再进行复杂运算其实是在浪费时间
新增节点的插入位置
新增一个节点时,Java8之前采用的是头插法,之后采用的是尾插法
采用头插法最大的问题就是在并发时,扩容可能产生环形链表,导致get()方法产生死循环,采用尾插法可以解决
其实头插法有一个好处:根据局部性原理越晚插入的元素越有可能被访问,因此头部插入有助于后续访问效率的提升
但是,如果是一个容量很大,并且长期存在于硬盘上的数据结构,这种局部性原理的效率提升更为明显。内存中短期使用的小容量数据结构,反而不太能借助局部性原理提升效率。
扩容方法
扩容时最直接影响效率的问题,就是需要把元素迁移到新的桶位中。
首先注意,表中每个节点都会保存一个hash值,这个值是经过扰动函数处理之后、取模之前的值,扩容时会用到这个值重新计算下标
拆分元素的过程中,原jdk1.7中会需要重新计算哈希值:**hash&(length-1),但是到jdk1.8中已经进行优化,不再直接取模计算,提升了拆分的性能,设计的还是非常巧妙的
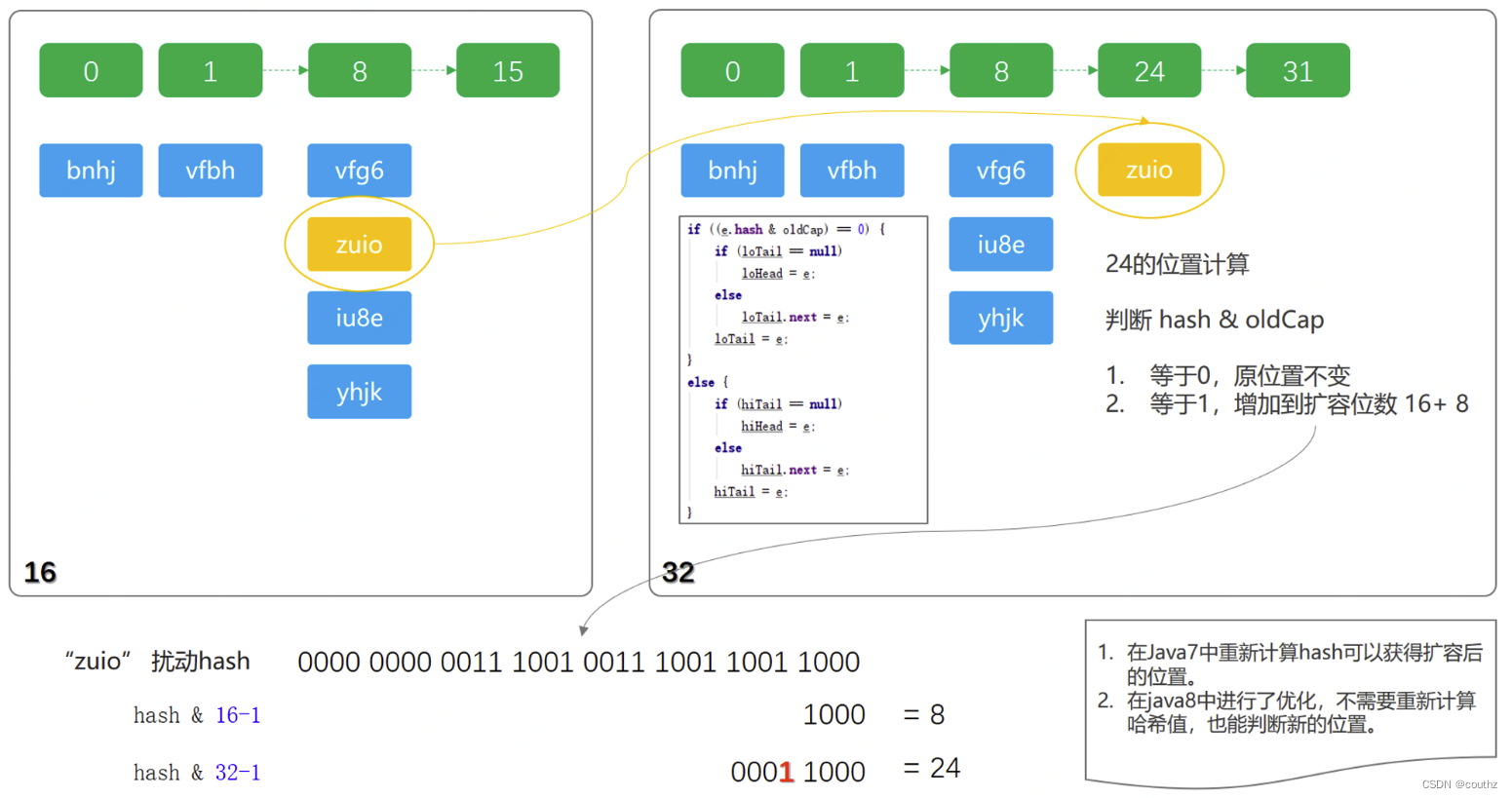
对31取模保留低5位,对15取模保留低4位,两者的差异就在于第5位是否为1,是的话则需要加上增量,为0的话则不需要改变
参考资料
面经手册 · 第3篇《HashMap核心知识,扰动函数、负载因子、扩容链表拆分,深度学习》 | bugstack 虫洞栈