1.Java集合有哪些?
集合类型主要有3种:set(集)、list(列表)和map(映射)
Map接口和Collection接口是所有集合框架的父接口:
1. Collection接口的子接口包括:Set接口和List接口
2. Map接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
3. Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
4. List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等

2.Java集合的快速失败机制 “fail-fast”?
是java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast 机制。
例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。
原因:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
解决办法:
1. 在遍历过程中,所有涉及到改变modCount值得地方全部加上synchronized。
2. 使用CopyOnWriteArrayList来替换ArrayList
简单的说,就是一个线程正在遍历集合,此时另一个线程删了一个元素,就会抛异常,处理方式也很容易,加锁(也就是使用synchronized关键字(此关键字后面将线程安全讲)),还有就是用CopyOnWriteArrayList,它在“添加/修改/删除”数据时,都会新建一个数组,并将更新后的数据拷贝到新建的数组中,最后再将该数组赋值给“volatile数组”。
3.怎么确保一个集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常。
4.List接口
4.1迭代器 Iterator 是什么?
Iterator 接口提供遍历任何 Collection 的接口。我们可以从一个 Collection 中使用迭代器方法来获取迭代器实例。可以实现一边遍历,一边删除,这是for循环遍历所不能实现的。
Iterator<Integer> it = list.iterator();
while(it.hasNext()){
*// do something*
it.remove();
}Iterator是一个可以实现在遍历的时候删除而不报错的接口
4.2遍历一个 List 有哪些不同的方式?每种方法的实现原理是什么?
1. for 循环遍历,基于计数器。在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后停止。
2. 迭代器遍历,Iterator。Iterator 是面向对象的一个设计模式,目的是屏蔽不同数据集合的特点,统一遍历集合的接口。Java 在 Collections 中支持了 Iterator 模式。
3. foreach 循环遍历。foreach 内部也是采用了 Iterator 的方式实现,使用时不需要显式声明Iterator 或计数器。优点是代码简洁,不易出错;缺点是只能做简单的遍历,不能在遍历过程中操作数据集合,例如删除、替换。
4.3 Java 中 List遍历的最佳实践是什么?
最佳实践:Java Collections 框架中提供了一个 RandomAccess 接口,用来标记 List 实现是否支持 Random Access。
如果一个数据集合实现了该接口,就意味着它支持 Random Access,按位置读取元素的平均时间复杂度为 O(1),如ArrayList。
如果没有实现该接口,表示不支持 Random Access,如LinkedList。
推荐的做法就是,支持 Random Access 的列表可用 for 循环遍历,否则建议用 Iterator 或foreach 遍历。
4.4说一下 ArrayList 的优缺点
ArrayList的优点如下:
ArrayList 底层以数组实现,是一种随机访问模式。ArrayList 实现了 RandomAccess 接口,因此查找的时候非常快。
ArrayList 在顺序添加一个元素的时候非常方便。
ArrayList 的缺点如下:
删除元素的时候,需要做一次元素复制操作。如果要复制的元素很多,那么就会比较耗费性能。
插入元素的时候,也需要做一次元素复制操作,缺点同上。(头插头删比较消耗性能)
ArrayList 比较适合顺序添加、随机访问的场景。
4.5 ArrayList是线程安全的吗?
当然不是,线程安全版本的数组容器是Vector。
Vector的实现很简单,就是把所有的方法统统加上synchronized就完事了。
你也可以不使用Vector,用Collections.synchronizedList把一个普通ArrayList包装成一个线程安全版本的数组容器也可以,原理同Vector是一样的,就是给所有的方法套上一层synchronized。
不存在一个集合工具是查询效率又高,增删效率也高的,还线程安全的,因为数据结构的特性就是优劣共存的,想找个平衡点很难,牺牲了性能,那就安全,牺牲了安全那就快速。
4.6 数组的长度是有限制的,而ArrayList是可以存放任意数量对象,那么他是怎么实现的呢?
其实实现方式比较简单,他就是通过数组扩容的方式去实现的。
就比如我们现在有一个长度为10的数组,现在我们要新增一个元素,发现已经满了,那ArrayList会怎么做呢?(10是默认长度)

第一步他会重新定义一个长度为10+10/2的数组也就是新增一个长度为15的数组。(每次扩容都是原来长度的1.5倍)

然后把原数组的数据,原封不动的复制到新数组中,这个时候再把指向原数的地址换到新数组,ArrayList就这样完成了一次改头换面。

4.7 能说一下ArrayList在增删的时候是怎么做的么?主要说一下他为啥慢。
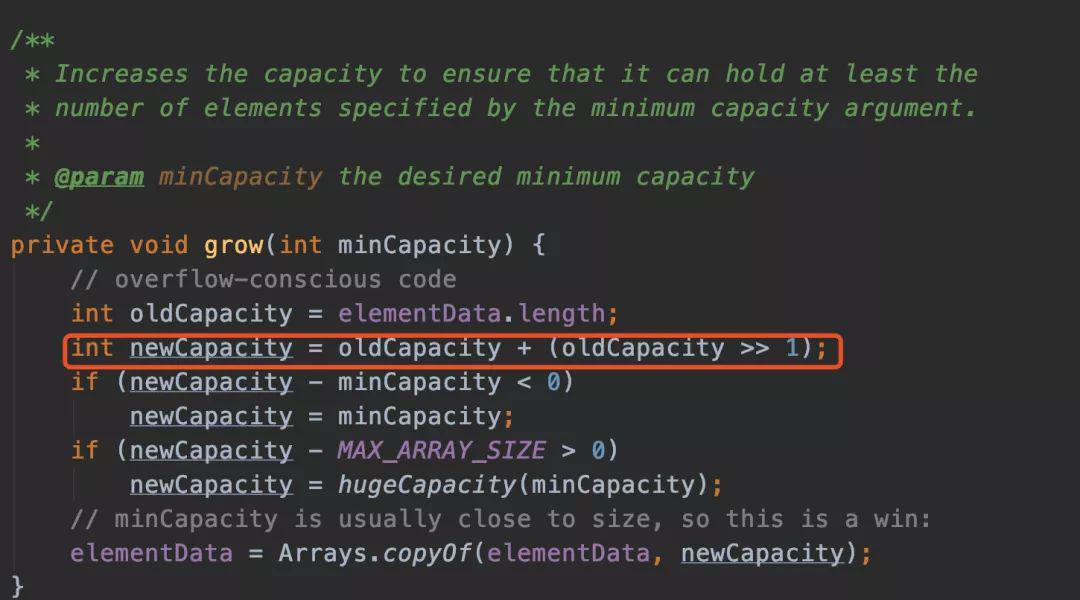
他有指定index新增,也有直接新增的,在这之前他会有一步校验长度的判断ensureCapacityInternal,就是说如果长度不够,是需要扩容的。

在扩容的时候,老版本的jdk和8以后的版本是有区别的,8之后的效率更高了,采用了位运算,右移一位,其实就是除以2这个操作。
指定位置新增的时候,在校验之后的操作很简单,就是数组的copy,大家可以看下代码。

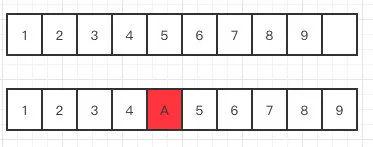
画个图解释下,你可能就明白一点:
比如有下面这样一个数组我需要在index 5的位置去新增一个元素A

那从代码里面我们可以看到,他复制了一个数组,是从index 5的位置开始的,然后把它放在了index 5+1的位置

给我们要新增的元素腾出了位置,然后在index的位置放入元素A就完成了新增的操作了
至于为啥说他效率低,我想我不说你也应该知道了,我这只是在一个这么小的List里面操作,要是我去一个几百几千几万大小的List新增一个元素,那就需要后面所有的元素都复制,然后如果再涉及到扩容啥的就更慢了不是嘛。
4.8 LinkList(链表)
LinkedList 是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
4.9 ArrayList 和 LinkedList 的区别是什么?
数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为ArrayList 增删操作要影响数组内的其他数据的下标。
内存空间占用:LinkedList 比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
LinkedList 的双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
总结:
ArrayList是实现了基于动态数组的数据结构,而LinkedList是基于链表的数据结构; 对于随机访问get和set,ArrayList要优于LinkedList,因为LinkedList要移动指针;对于添加和删除操作add和remove,两种数据结构谁快谁慢取决于数据量的大小,通常采用ArrayList能满足大部分的使用场景,除非需要使用LinkedList实现队列、栈等数据结构。
若使用头插法插入数据,使用linkedList效率大于arrayList
使用尾插法,数据量过大时,arrayList效率高于LinkedList,
若根据下标查找数据:arrayList效率高
若根据值来查找数据,arrayList和LinkedList效率差不多。
4.10 ArrayList 和 Vector 的区别是什么?
这两个类都实现了 List 接口(List 接口继承了 Collection 接口),他们都是有序集合
线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。
性能:ArrayList 在性能方面要优于 Vector。
扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%。
Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
4.11 为什么 ArrayList 的 elementData 加上 transient 修饰?
什么是序列化?Java中对象的序列化指的是将对象转换成以字节序列的形式来表示,这些字节序列包含了对象的数据和信息,一个序列化后的对象可以被写到数据库或文件中,也可用于网络传输。
transient关键字的作用?对于transient 修饰的成员变量,在类的实例对象的序列化处理过程中会被忽略。 因此,transient变量不会贯穿对象的序列化和反序列化,生命周期仅存于调用者的内存中而不会写到磁盘里进行持久化。

可以看到 ArrayList 实现了 Serializable 接口,这意味着 ArrayList 支持序列化。transient 的作用是说不希望 elementData 数组被序列化,重写了 writeObject 实现:
/**
* Save the state of the <tt>ArrayList</tt> instance to a stream (that
* is, serialize it).
*
* @serialData The length of the array backing the <tt>ArrayList</tt>
* instance is emitted (int), followed by all of its elements
* (each an <tt>Object</tt>) in the proper order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}每次序列化时,先调用 defaultWriteObject() 方法序列化 ArrayList 中的非 transient 元素,然后遍历 elementData,只序列化已存入的元素,这样既加快了序列化的速度,又减小了序列化之后的文件大小。
5. Set
5.1 List 和 Set 的区别
List , Set 都是继承自Collection 接口
List 特点:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。
Set 特点:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是 HashSet、LinkedHashSet 以及TreeSet。
另外 List 支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。
Set和List对比
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
5.2 说一下 HashSet 的实现原理?
HashSet 是基于 HashMap 实现的,HashSet的值存放于HashMap的key上,HashMap的value统一为present,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层HashMap 的相关方法来完成,HashSet 不允许重复的值。

这里可能会有疑惑,HashMap是(key,value)形式,而HashSet是单值形式,为什么能复用HashMap的方法呢?看代码HashSet的add()方法

这个PRESENT 又是个啥?

上面注释这句话啥意思呢?就是说,赋了一个假值,即Map的value都是这个PRESENT 假的值, 因为不需要知道value,只要求key不重复。