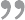上篇重点介绍了互联网APP在搜索交互场景下的通用逻辑,让大众对每天离不开的搜索进行了一个普遍介绍。这一篇,我们来聊聊抖音、头条等APP划一划这个动作背后,是怎么做推荐的。

推荐的背后,离不开每个用户的数据,而且这个用户要规模非常大,这个就叫用户流量,当然,每个用户的个人行为以及普遍习惯的收集,才是后台算法能做准确猜想和推荐的核心逻辑,这个就叫大数据。那么每天APP收集到的你得数据到底有那些?
什么叫做用户行为数据?
用户行为也叫做用户特征,专业术语叫做用户埋点。是很多大厂APP背后进行收集的用户第一首资料。而事实上这是APP系统能够推荐起到的关键作用。用户特征具体分为:视频特征、用户特征。对于用户来讲,抖音会实时的记录用户对某个视频的点击、播放、停留、关注、评论、点赞、转发等行为,并根据这些特征离线或实时的进行计算。

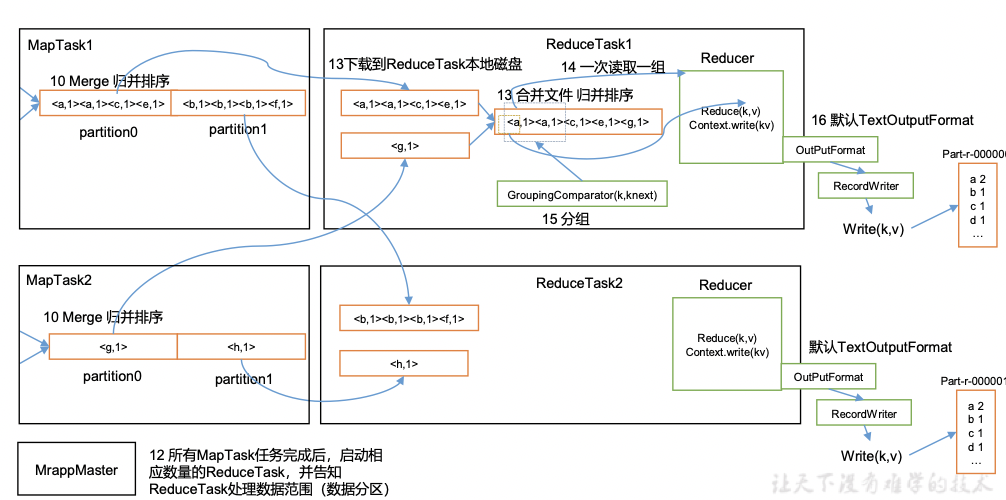
抖音之所以能够让用户“越刷越上头”还在于其对推荐的改进,如图所示:

(1)当一个新用户上传一个视频时,首先由设计好的系统对视频进行自动打标签,获取视频的显式特征信息;
(2)其次将该视频先随机推荐给1万个用户(又称流量池);
(3)这些被推荐的用户根据其对这个新上传的视频进行相关交互(点击、播放、停留、关注、评论、点赞、转发等),根据交互的用户行为数据,来判断当前的视频质量如何(尤其是该视频的完播率如何, 完播率意指整个视频完整的被观看的次数占比),当然这里的算法很复杂,通用的有机器学习的监督分类算法。通过机器学习后的结果,就普遍对该视频的质量有一个打分,再通过打分来判断,是否进一步扩大推荐的范围;
(4)更优秀的视频会被推荐到更大的流量池,以获得更多的用户浏览量。
因此这套机制可以避免资源倾斜问题,即便是一些新用户(或使用小号),在上传的视频中,如果质量好,都有机会获得更多的浏览量,该推荐机制避免了系统偏向大号大V的问题。
另外,抖音推荐还会涉及到对社交网络的挖掘。在基于内容给的推荐时,根据用户关注的主播,或已查看相关主播的多个视频时,可根据该主播的其他粉丝的兴趣来进行推荐,这一部分则可以涉及到社交关系知识图谱,以此发现更多新的视频。这也就是说,当你在持续刷抖音时,总会发现一些新的感兴趣的视频。
对于算法,要结合实际的应用场景,例如对于抖音推荐,目标是为了使得推荐的视频能够更加符合用户的兴趣,因此其优化目标是完播率;而对于一些广告服务的平台,例如爱奇艺视频附带的广告,其优化目标则是最大化广告的点击率(CTR),从而获得更多的广告服务费;而对于淘宝天猫等电商,其优化目标则是兼顾用户是否查看某个商品的点击率(CTR),以及是否会产生购买行为的转化率(CVR)。因此对于算法的设计,需要结合实际的优化目标。常用的推荐算法有:
(1)基于协同过滤的推荐,包括基于用户和基于内容两个部分;
(2)基于矩阵分解或因子分解机的推荐;
(3)基于逻辑回归、集成学习等机器学习方法;
(4)基于Embedding和相似度匹配的推荐;
(5)基于深度学习的推荐
现如今常部署在大数据底层系统上的算法以机器学习或简单的深度学习模型为主,因此大多数领域内,推荐系统不仅在乎准确率,更在乎其实时性,因此部署的模型参数不宜过多。
用户的交互数据通常是支撑大数据和推荐的关键,没有用户交互行为数据,无法谈得上推荐,因此如何构建并提取用户行为在学术界和工业界非常关心的问题,通常对用户的数据采集可以包括一些显式交互数据(包括点击、转发、购买等)和隐式交互数据(包括播放时长,停留时长、社交关系等)。可以通过客户端session对数据的实时获取并保存在数据库中。
推荐系统的未来趋势
现如今各大平台之间数据不流通的问题,是制约推荐系统的发展。例如一个用户间断性的在抖音和微视上看视频,使得两个平台的用户行为是间断性的,然而多个平台之间的数据通常由于商业竞争原因而无法公开,从而影响推荐的性能,使得对用户画像的构建不完善,因此突破此屏障的最新方法是基于数据中台和基于联邦学习的框架体系:
(1)数据中台:缓解数据孤岛,将多个平台的数据汇总在一起,并可实现数据复用与共享;但这通常需要多个公司之间满足一定的协议。在数据中台的基础上,实现大数据挖掘和推荐,可以进一步提高收益;
(2)联邦学习:联邦学习是近两年比较火的概念,其主要解决的就是各大企业之间不愿意公开数据,而使得模型无法充分学习到用户的行为特征的问题。如果利用联邦学习,各个公司的数据无须汇总到一个中心结点,而只需要一定的联邦算法,让模型分布式地进行学习,既可以充分利用各个平台的数据,又可以保证数据的隐私性和安全性。