文章目录
- 垂直分表
- 拆分方法
- 举例
- 垂直分库
- 水平分表
- 水平分库
- 小结
- 垂直角度(表结构不一样)
- 水平角度(表结构一样)
垂直分表
需求:商品表字段太多,每个字段访问频次不⼀样,浪费了IO资源,需要进行优化
也就是“大表拆小表”,基于列字段进行的
拆分方法
- ⼀般是表中的字段较多,将不常用的或者数据较大,长度较长的拆分到扩展表如text类型字段;
- 访问频次低、字段大的商品描述信息单独存放在⼀张表中,访问频次较高的商品基本信息单独放在⼀张表中;
- 把不常用的字段单独放在⼀张表; 把text,blob等大字段拆分出来放在附表中;
- 业务经常组合查询的列放在⼀张表中
举例
//拆分前
CREATE TABLE `product` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(524) DEFAULT NULL COMMENT '视频标题',
`cover_img` varchar(524) DEFAULT NULL COMMENT '封⾯图',
`price` int(11) DEFAULT NULL COMMENT '价格,分',
`total` int(10) DEFAULT '0' COMMENT '总库存',
`left_num` int(10) DEFAULT '0' COMMENT '剩余',
`learn_base` text COMMENT '课前须知,学习基础',
`learn_result` text COMMENT '达到⽔平',
`summary` varchar(1026) DEFAULT NULL COMMENT '概述',
`detail` text COMMENT '视频商品详情',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
//拆分后
CREATE TABLE `product` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(524) DEFAULT NULL COMMENT '视频标题',
`cover_img` varchar(524) DEFAULT NULL COMMENT '封⾯图',
`price` int(11) DEFAULT NULL COMMENT '价格,分',
`total` int(10) DEFAULT '0' COMMENT '总库存',
`left_num` int(10) DEFAULT '0' COMMENT '剩余',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `product_detail` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`product_id` int(11) DEFAULT NULL COMMENT '产品主键',
`learn_base` text COMMENT '课前须知,学习基础',
`learn_result` text COMMENT '达到⽔平',
`summary` varchar(1026) DEFAULT NULL COMMENT '概述',
`detail` text COMMENT '视频商品详情',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
垂直分库
需求:C端项目里面,单个数据库的CPU、内存长期处于90%+的利用率,数据库连接经常不够,需要进行优化
- 垂直分库针对的是⼀个系统中的不同业务进行拆分, 数据库的连接资源比较宝贵且单机处理能力也有限
- 没拆分之前全部都是落到单⼀的库上的,单库处理能力成为瓶颈,还有磁盘空间,内存,tps等限制
- 拆分之后,避免不同库竞争同⼀个物理机的CPU、内存、网络IO、磁盘,所以在高并发场景下,垂直分库⼀定程度上能够突破IO、连接数及单机硬件资源的瓶颈
- 垂直分库可以更好解决业务层面的耦合,业务清晰,且方便管理和维护
⼀般从单体项目升级改造为微服务项目,就是垂直分库
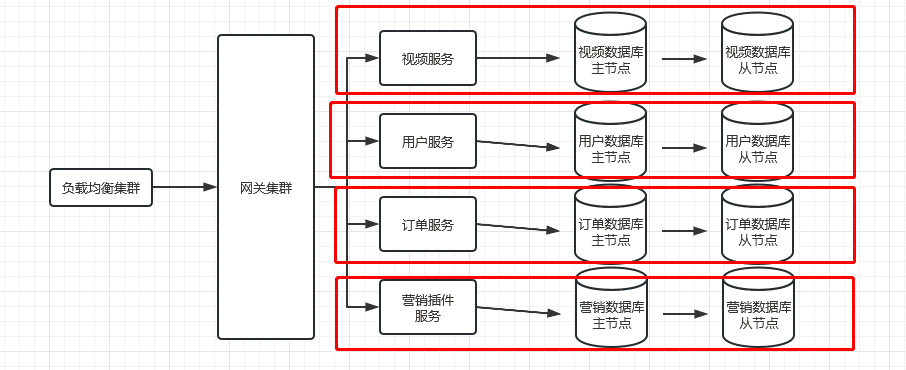
但是,垂直分库分表可以提高并发,但是依然没有解决单表数据量过大的问题
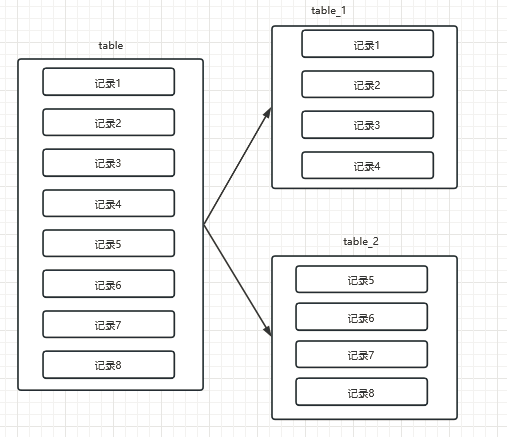
水平分表
需求:当⼀张表的数据达到几千万时,查询⼀次所花的时间长,需要进行优化,缩短查询时间
- 把⼀个表的数据分到⼀个数据库的多张表中,每个表只有这个表的部分数据
- 核心是把⼀个大表,分割N个小表,每个表的结构是⼀样的,数据不⼀样,全部表的数据合起来就是全部数据
- 针对数据量巨⼤的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去
- 但是这些表还是在同⼀个库中,所以单数据库操作还是有IO瓶颈,主要是解决单表数据量过⼤的问题
- 减少锁表时间,没分表前,如果是DDL(create/alter/add等)语句,当需要添加⼀列的时候mysql会锁表,期间所有的读写操作只能等待
水平分库
需求:高并发的项目中,水平分表后依旧在单个库上面,1个数据库资源瓶颈 CPU/内存/带宽等限制导致响应慢,需要进行优化
- 把同个表的数据按照⼀定规则分到不同的数据库中,数据库在不同的服务器上
- 水平分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构
- 每个库的结构都⼀样,但每个库的数据都不⼀样,没有交集,所有库的并集就是全量数据
- 水平分库的粒度,比水平分表更大
小结
垂直角度(表结构不一样)
垂直分表: 将⼀个表字段拆分多个表,每个表存储部分字段
好处: 1. 避免IO时锁表的次数,分离热点字段和⾮热点字段,避免⼤字段IO导致性能下降
原则: 1. 业务经常组合查询的字段⼀个表;不常⽤字段⼀个表;text、blob类型字段作为附属表
垂直分库:根据业务将表分类,放到不同的数据库服务器上
好处: 1. 避免表之间竞争同个物理机的资源,比如CPU/内存/硬盘/网络IO
原则: 1. 根据业务相关性进行划分,领域模型,微服务划分⼀般就是垂直分库
水平角度(表结构一样)
水平分库:把同个表的数据按照⼀定规则分到不同的数据库中,数据库在不同的服务器上
好处: 1. 多个数据库,降低了系统的IO和CPU压力
原则: 1. 选择合适的分片键和分片策略,和业务场景配合
2. 避免数据热点和访问不均衡、避免⼆次扩容难度大
水平分表:同个数据库内,把⼀个表的数据按照⼀定规则拆分到多个表中,对数据进⾏拆分,不影响表结构
单个表的数据量少了,业务SQL执行效率⾼,降低了系统的IO和CPU压力
原则:1. 选择合适的分片键和分片策略,和业务场景配合
2. 避免数据热点和访问不均衡、避免⼆次扩容难度大