进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
master心跳:
指令:PING
周期:由repl-ping-slave-period决定,默认10秒
作用:判断slave是否在线
查询:INFO replication

获取slave最后一次连接时间间隔,lag项维持在0或1视为正常
slave心跳任务
指令:REPLCONF ACK {offset}
周期:1秒
作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
作用2:判断master是否在线
心跳阶段注意事项
当slave多数掉线,或延迟过高时,master为保障数据稳定性,将拒绝所有信息同步操作

slave数量少于2个,或者所有slave的延迟都大于等于10秒时,强制关闭master写功能,停止数据同步
slave数量由slave发送REPLCONF ACK命令做确认
slave延迟由slave发送REPLCONF ACK命令做确认

主从复制常见问题
频繁的全量复制(1)
伴随着系统的运行,master的数据量会越来越大,一旦master重启,runid将发生变化,会导致全部slave的全量复制操作
内部优化调整方案:
1. master内部创建master_replid变量,使用runid相同的策略生成,长度41位,并发送给所有slave
2. 在master关闭时执行命令 shutdown save,进行RDB持久化,将runid与offset保存到RDB文件中
repl-id repl-offset
通过redis-check-rdb命令可以查看该信息
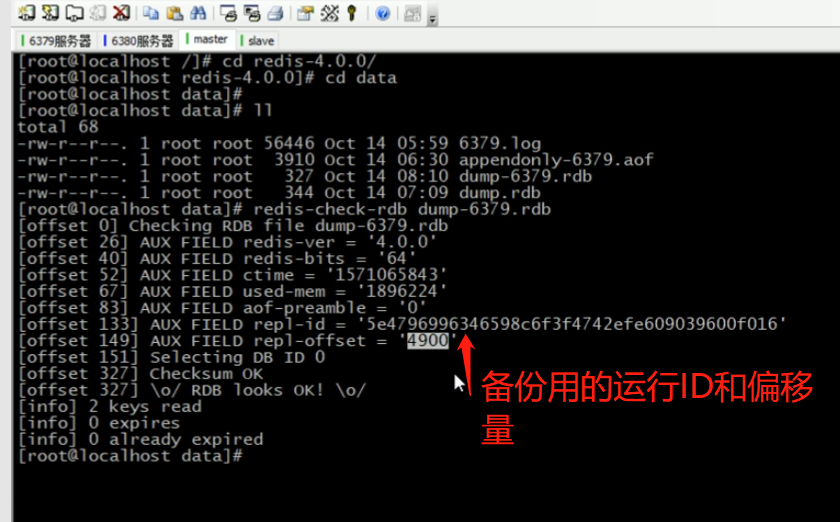
3. master重启后加载RDB文件,恢复数据
重启后,将RDB文件中保存的repl-id与repl-offset加载到内存中
master_repl_id = repl master_repl_offset = repl-offset
通过info命令可以查看该信息
作用:
本机保存上次runid,重启后恢复该值,使所有slave认为还是之前的master
频繁的全量复制(2)
问题现象
网络环境不佳,出现网络中断,slave不提供服务
问题原因
复制缓冲区过小,断网后slave的offset越界,触发全量复制
最终结果
slave反复进行全量复制
解决方案
修改复制缓冲区大小
repl-backlog-size 建议设置如下:
1. 测算从master到slave的重连平均时长second
2. 获取master平均每秒产生写命令数据总量write_size_per_second
3. 最优复制缓冲区空间 = 2 * second * write_size_per_second
频繁的网络中断(1)
问题现象
master的CPU占用过高 或 slave频繁断开连接
问题原因
slave每1秒发送REPLCONF ACK命令到master
当slave接到了慢查询时(keys * ,hgetall等),会大量占用CPU性能
master每1秒调用复制定时函数replicationCron(),比对slave发现长时间没有进行响应
最终结果
master各种资源(输出缓冲区、带宽、连接等)被严重占用
解决方案
通过设置合理的超时时间,确认是否释放slave
repl-timeout该参数定义了超时时间的阈值(默认60秒),超过该值,释放slave
频繁的网络中断(2)
问题现象
slave与master连接断开
问题原因
master发送ping指令频度较低
master设定超时时间较短
ping指令在网络中存在丢包
解决方案
提高ping指令发送的频度
repl-ping-slave-period超时时间repl-time的时间至少是ping指令频度的5到10倍,否则slave很容易判定超时
数据不一致
问题现象
多个slave获取相同数据不同步
问题原因
网络信息不同步,数据发送有延迟
解决方案
优化主从间的网络环境,通常放置在同一个机房部署,如使用阿里云等云服务器时要注意此现象
监控主从节点延迟(通过offset)判断,如果slave延迟过大,暂时屏蔽程序对该slave的数据访问
slave-serve-stale-data yes|no开启后仅响应info、slaveof等少数命令(慎用,除非对数据一致性要求很高)