Linux-0.11 文件系统inode.c详解
Linux-0.11中使用的文件系统为minix, inode.c中的函数和该文件系统强关联。
inode节点在文件系统中与文件相关联,一个文件的就由一个inode来管理,这个inode节点将记录文件的权限,大小, 文件具体存储的逻辑块位置等等信息。
read_inode
static void read_inode(struct m_inode * inode);
该函数的作用是通过inode的编号,在磁盘上读取inode块到内存。
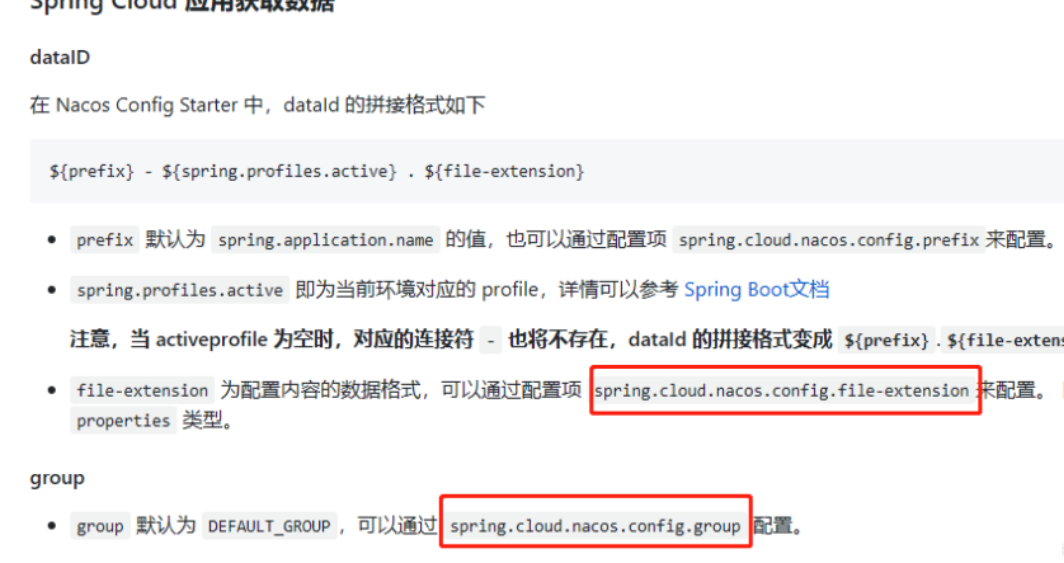
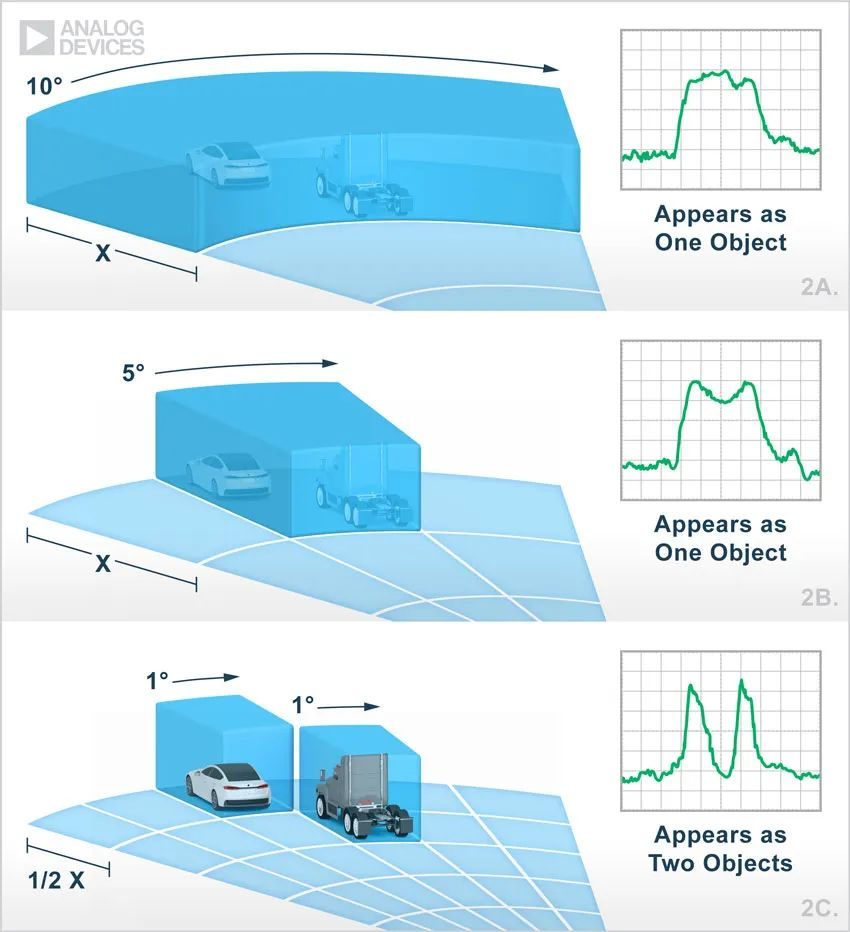
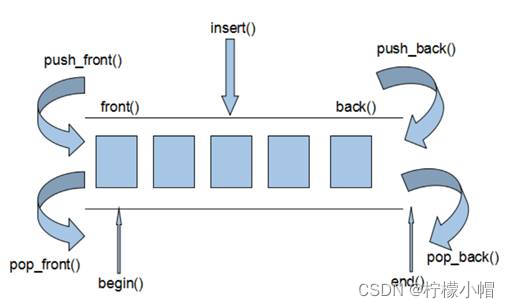
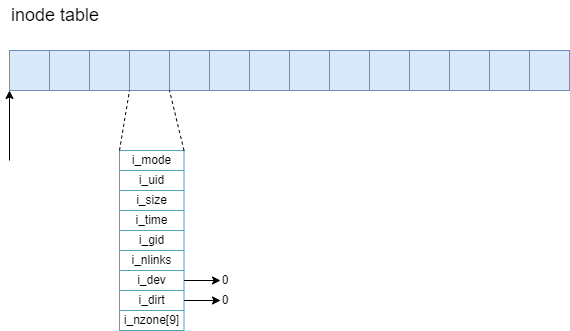
回顾一下minix文件系统的分布,如下图所示:
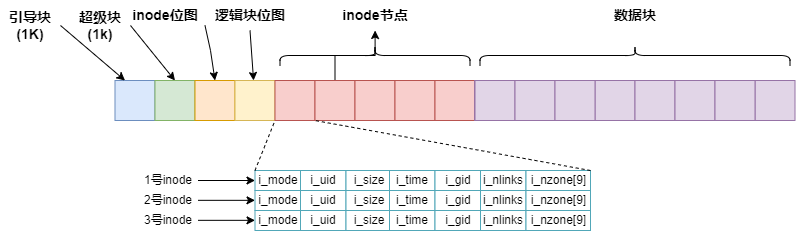
其中引导块为1个block,超级块为1个block,inode位图的大小在超级块中定义,逻辑块位图的大小在超级块中定义。跳过这些块,就可以来到inode节点块的起点。
那么inode节点会在哪个block中呢?
inode节点的序号从0开始, 但是0号是个保留号, 实际存储并不会存0号inode, 因此inode的实际起始位置是1。
因此序号为n的inode,在磁盘上的逻辑块号为:
block = 1 + 1 + s_imap_blocks(inode位图大小) + s_zmap_blocks(逻辑块位图大小) + (n - 1)/每个磁盘块存储的inode数量。
找到了inode所在的逻辑块号, 计算inode在该块中的下标, 则通过:
index = (n - 1) % 每个磁盘块存储的inode数量
到此, 给定一个inode号,就可以从磁盘上找到对应的inode节点。
通过上面的解释,很容易理解下面的代码。
if (!(sb=get_super(inode->i_dev)))//获取超级块的内容
panic("trying to read inode without dev");
block = 2 + sb->s_imap_blocks + sb->s_zmap_blocks +
(inode->i_num-1)/INODES_PER_BLOCK;//获取inode所在的逻辑块
if (!(bh=bread(inode->i_dev,block)))//读取该逻辑块的内容
panic("unable to read i-node block");
*(struct d_inode *)inode =
((struct d_inode *)bh->b_data)
[(inode->i_num-1)%INODES_PER_BLOCK];//将该inode读取到内存中
write_inode
static void write_inode(struct m_inode * inode)
该函数的作用是将inode的内容回写到磁盘。
该函数在搜索inode节点的方法上和read_inode相同。
有所区别的是该函数是修改一个inode的值, 因此在找到inode节点后需要进行赋值, 并将buffer块标记为脏页,以回写到磁盘上。
((struct d_inode *)bh->b_data)
[(inode->i_num-1)%INODES_PER_BLOCK] =
*(struct d_inode *)inode;
bh->b_dirt=1;//磁盘也标记为脏页
inode->i_dirt=0;//inode的脏数据标记为0
iget
iget(int dev,int nr)
该函数的作用主要是通过设备号和inode的序号获取对应的inode节点。
需要注意的是,如果一个硬盘上装有多个文件系统,需要处理一个inode节点是另一个文件系统挂载点的情况。
该段代码主要是遍历inode表,查找是否存在这样的inode, 这个inode的设备号和入参的设备号相同, inode的节点号和入参的节点号相同。如果查到了, 则将该inode的引用计数增加1。
while (inode < NR_INODE+inode_table) {
if (inode->i_dev != dev || inode->i_num != nr) {//遍历inode表, 查找inode
inode++;
continue;
}
wait_on_inode(inode);//等待该inode节点
if (inode->i_dev != dev || inode->i_num != nr) {
inode = inode_table;
continue;
}
inode->i_count++;//引用计数增加1
如果i节点是某个文件系统的安装点, 则在超级块的表中搜索即可搜索到。 若找到了相应的超级块, 则将该i节点写盘。再从安装此i节点的文件系统上的超级块上取设备号,并令i节点为1。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AbFwIRZz-1676864332322)(null)]](https://img-blog.csdnimg.cn/ed6ea89688cd475cb15417a5e49f035b.png)
判断inode节点是否是其他文件系统挂载点的代码如下:
if (inode->i_mount) {//该inode是一个挂载节点
int i;
for (i = 0 ; i<NR_SUPER ; i++)
if (super_block[i].s_imount==inode)//在超级块中查找到
break;
if (i >= NR_SUPER) {
printk("Mounted inode hasn't got sb\n");
if (empty)
iput(empty);
return inode;
}
iput(inode);//将该inode的引用计数减1
dev = super_block[i].s_dev;//设备号设置为超级块中的设备号
nr = ROOT_INO;//inode节点号设置为1号
inode = inode_table;
continue;
}
iput
void iput(struct m_inode * inode)
该函数的作用是放回一个i节点。 该函数主要用于将i节点的引用计数递减1。
首先判断i节点的有效性:
if (!inode)
return;
wait_on_inode(inode);//等待inode解锁
if (!inode->i_count) //如果引用计数为0, 则inode是空闲的, 内核要求放回是有问题的。
panic("iput: trying to free free inode");
下面是对管道节点的处理:
if (inode->i_pipe) {
wake_up(&inode->i_wait);//唤醒等待该管道节点的进程
if (--inode->i_count)//引用计数减1
return;
free_page(inode->i_size);//将管道节点的内存释放, 对于管道节点inode->i_size存放着内存页的地址。
inode->i_count=0;
inode->i_dirt=0;
inode->i_pipe=0;
return;
}
如果是一个设备节点,则刷新该设备:
if (S_ISBLK(inode->i_mode)) {
sync_dev(inode->i_zone[0]);
wait_on_inode(inode);
}
最后一段是执行引用计数减1的操作:
repeat:
if (inode->i_count>1) {//引用计数大于1, 直接减1后返回
inode->i_count--;
return;
}
if (!inode->i_nlinks) {//如果连接数为0, 则该文件已经被删除
truncate(inode);
free_inode(inode);
return;
}
if (inode->i_dirt) {//如果该inode为脏数据, 则写回磁盘
write_inode(inode); /* we can sleep - so do again */
wait_on_inode(inode);
goto repeat;
}
inode->i_count--;//引用计数减1
get_empty_inode
struct m_inode * get_empty_inode(void)
该函数的作用是从空闲的inode表中获取一个空闲的i节点项。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rrEWONIk-1676864332368)(null)]
_bmap
static int _bmap(struct m_inode * inode,int block,int create)
该函数的作用就是映射文件数据块到盘块的处理操作。
需要注意的是入参中的block不是指硬盘的逻辑块, 而是指文件的数据块的序号。 该block指的是文件的第block个1k的数据块。
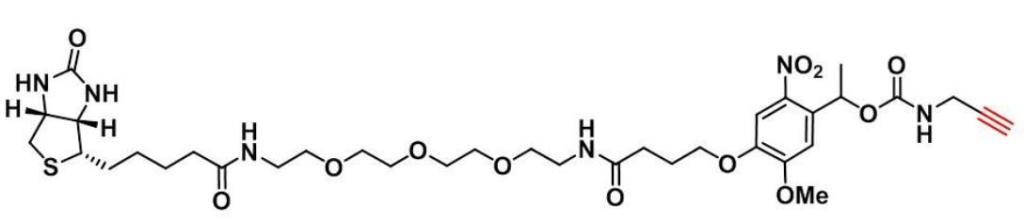
inode的寻址主要分为直接寻址,一次间接块的寻址, 二次间接块的寻址三种。如下图所示:
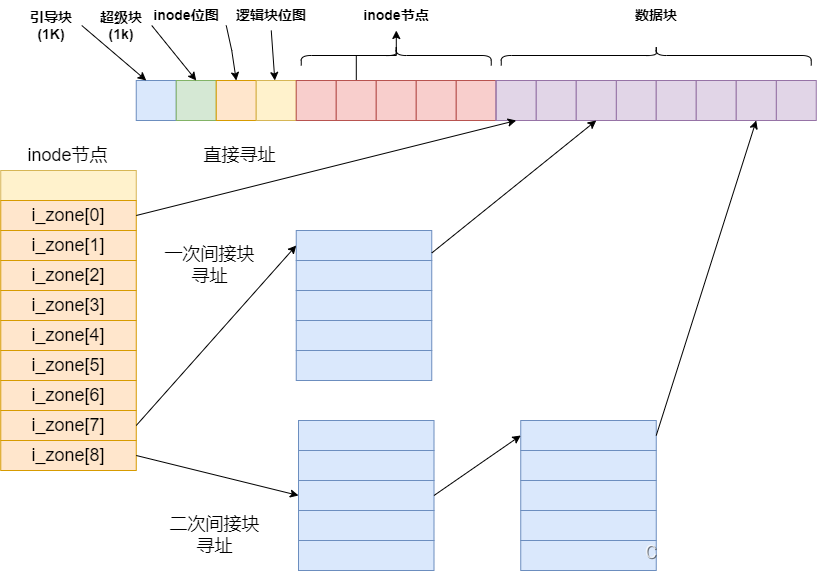
如果block号小于7, 则直接寻址。
if (block<7) {
if (create && !inode->i_zone[block])
if ((inode->i_zone[block]=new_block(inode->i_dev))) {
inode->i_ctime=CURRENT_TIME; //设置change time
inode->i_dirt=1; //设置该inode块已经被修改,是一个脏数据
}
return inode->i_zone[block];
}
如果block号大于7, 小于等于7 + 512, 则通过一次间接块寻址。
block -= 7;
if (block<512) {
if (create && !inode->i_zone[7])
if ((inode->i_zone[7]=new_block(inode->i_dev))) { //建立一次间接块
inode->i_dirt=1;
inode->i_ctime=CURRENT_TIME;
}
if (!inode->i_zone[7])
return 0;
if (!(bh = bread(inode->i_dev,inode->i_zone[7])))
return 0;
i = ((unsigned short *) (bh->b_data))[block];
if (create && !i)
if ((i=new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block]=i;
bh->b_dirt=1;
}
brelse(bh);
return i;
}
如果block号大于7 + 512 , 小于等于7 + 512 + 512 * 512, 则通过二次间接块寻址。
block -= 512;
if (create && !inode->i_zone[8])
if ((inode->i_zone[8]=new_block(inode->i_dev))) {
inode->i_dirt=1;
inode->i_ctime=CURRENT_TIME;
}
if (!inode->i_zone[8])
return 0;
if (!(bh=bread(inode->i_dev,inode->i_zone[8])))
return 0;
i = ((unsigned short *)bh->b_data)[block>>9];
if (create && !i)
if ((i=new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block>>9]=i;
bh->b_dirt=1;
}
brelse(bh);
if (!i)
return 0;
if (!(bh=bread(inode->i_dev,i)))
return 0;
i = ((unsigned short *)bh->b_data)[block&511];
if (create && !i)
if ((i=new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block&511]=i;
bh->b_dirt=1;
}
brelse(bh);
create_block
int create_block(struct m_inode * inode, int block)
create block底层调用了_bmap函数,去磁盘上申请一个逻辑块, 并与inode关联, 通过返回该逻辑块的盘块号。
bmap
int bmap(struct m_inode * inode,int block)
该函数的作用是通过文件数据块的块号返回其磁盘上的逻辑块号。底层也是通过_bmap函数实现。
sync_inodes
void sync_inodes(void)
该函数的作用是将inode表中的脏的数据刷到磁盘上。
inode = 0+inode_table;
for(i=0 ; i<NR_INODE ; i++,inode++) {
wait_on_inode(inode);//等待该inode解锁
if (inode->i_dirt && !inode->i_pipe)//如果inode已经被修改, 并且不是管道节点
write_inode(inode); //将该inode写盘
}
invalidate_inodes
void invalidate_inodes(int dev)
释放设备dev在内存i节点表中的所有i节点。
该函数的作用就是遍历inode数组, 如果inode数组的某一项的i_dev等于dev的时候, 将该inode的i_dev和i_dirt置为0。
inode = 0+inode_table;
for(i=0 ; i<NR_INODE ; i++,inode++) {
wait_on_inode(inode);//如果该inode已经被加锁,则等待该inode解锁
if (inode->i_dev == dev) {
if (inode->i_count) //如果引用不为0, 则打印出错信息
printk("inode in use on removed disk\n\r");
inode->i_dev = inode->i_dirt = 0; //将设备号置为0, 即释放该inode
}
}
get_pipe_inode
struct m_inode * get_pipe_inode(void)
该函数的作用是获取管道节点。
if (!(inode = get_empty_inode()))//从inode表中获取一个空闲的inode
return NULL;
if (!(inode->i_size=get_free_page())) {//从内存中获取一个空的页,赋值给inode的i_size变量
inode->i_count = 0;
return NULL;
}
inode->i_count = 2; /* sum of readers/writers */
PIPE_HEAD(*inode) = PIPE_TAIL(*inode) = 0;//复位管道的头尾指针
inode->i_pipe = 1;
lock_inode
static inline void lock_inode(struct m_inode * inode)
该函数的作用是锁定某个inode节点。
该函数的代码较为简单,下面直接通过注释进行解释。
cli();//关中断
while (inode->i_lock)
sleep_on(&inode->i_wait);//如果该inode被加锁, 就将当前进程状态修改为TASK_UNINTERRUPTIBLE, 切换其他进程运行
inode->i_lock=1; //将该inode的锁定状态修改为1
sti();//开中断
wait_on_inode
static inline void wait_on_inode(struct m_inode * inode)
该函数的作用是等待指定的inode节点解锁。
该函数的代码较为简单,下面直接通过注释进行解释。
cli(); //关中断
while (inode->i_lock)
sleep_on(&inode->i_wait); //如果该inode被加锁, 就将当前进程状态修改为TASK_UNINTERRUPTIBLE, 切换其他进程运行
sti();//开中断
unlock_inode
static inline void unlock_inode(struct m_inode * inode)
该函数的作用是对指定inode解锁。
该函数的代码较为简单,下面直接通过注释进行解释。
inode->i_lock=0;//将该inode的锁定状态修改为0.
wake_up(&inode->i_wait);//唤醒等待该inode的进程