pytorch搭建手写数字识别LeNet-5网络,并用tensorRT部署
- 前言
- 1、pytorch 搭建LeNet-5,并转为ONNX格式
- 1.1 LeNet-5网络介绍
- 1.2 ONNX(Open Neural Network Exchange)介绍
- 1.3 pytorch 搭建 LeNet5网络
- 2、将onnx转为tensorRT
- 2.1 tensorRT 介绍
- 2.1 onnx 转为 tensorRT
- 3、opencv加载图片,并使用tensorRT 加速推理
- 推理结果
前言
本文只是本人学习模型部署一个简单demo,只是本人学习记录笔记,文中部分代码和文字来源网上,如有请联系我进行删除。代码实现均为python代码,未实现c++版本。
本文未提供环境搭建介绍,代码运行环境如下:
pytorch=1.13
cuda=11.6
cudnn=8.8.0
tensorRT=8.5.3
pycuda=2022.2.2
opencv=4.7.0
这是本人之前环境实录 cuda11.6.2 + cudnn8.8.0 + tensorRT8.5.3 + pytorch1.13安装记录(亲测有效)
1、pytorch 搭建LeNet-5,并转为ONNX格式
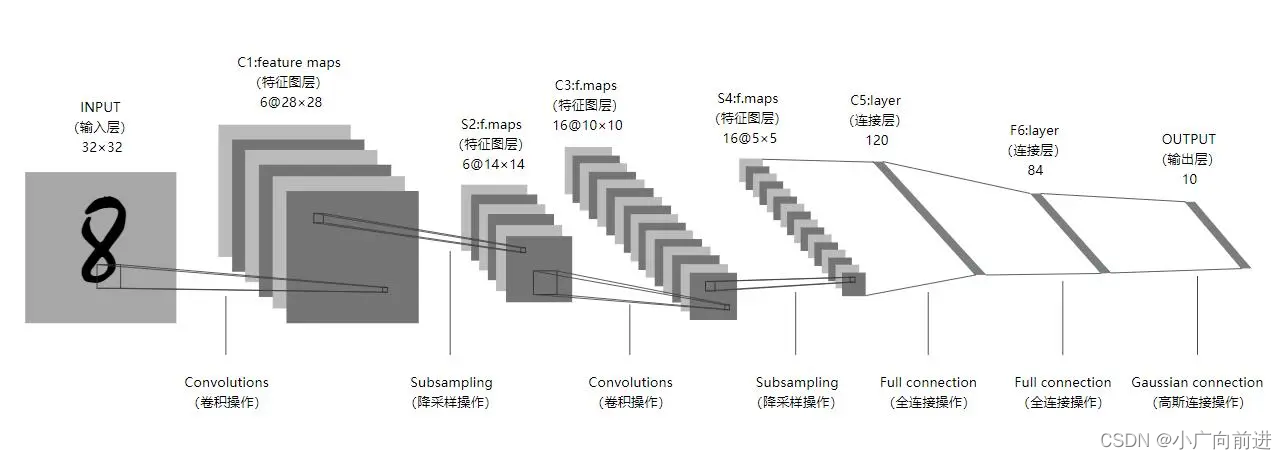
1.1 LeNet-5网络介绍
Lenet-5 神经网络出自论文 Gradient-Based Learning Applied to Document Recognition,是一种用于手写体字符识别的非常高效的卷积神经网络。Lenet-5 神经网络一共有 7 层,每层包含不同数量的训练参数。将一批数据输入进神经网络,经过卷积,激活,池化,全连接和Softmax 回归等操作,最终返回一个概率数组,从而达到识别图片的目的。
1.2 ONNX(Open Neural Network Exchange)介绍
开放神经网络交换(Open Neural Network Exchange, ONNX)是一种用于表示机器学习模型的开放标准文件格式,可用于存储训练好的模型,它使得不同的机器学习框架(如PyTorch, Caffe等)可以采用相同格式存储模型数据并可交互。ONNX定义了一组和环境、平台均无关的标准格式,来增强各种机器学习模型的可交互性。它让研究人员可以自由地在一个框架中训练模型并在另一个框架中做推理(inference)。
ONNX的表示方式有两个核心优势:
1. 框架之间的互用互通
开发者能更方便地在不同框架间切换,为不同任务选择最优工具。基本每个框架都会针对某个特定属性进行优化,比如训练速度、对网络架构的支持、能在移动设备上推理等等。在大多数情况下,研发阶段最需要的属性和产品阶段是不一样的。这导致效率的降低,比如选择不切换到最合适的框架,又或者把模型转移到另一个框架导致额外的工作,造成进度延迟。使用支持ONNX表示方式的框架,则大幅简化了切换过程,让开发者的工具选择更灵活。
2. 优化共享
硬件设备商们推出的对神经网络性能的优化,将能够一次性影响到多个开发框架——如果用的是ONNX表示方式。如果优化很频繁,把它们单独整合到各个框架是个非常耗费时间的事。通过ONNX表示方式,更多开发者就能获取这些优化。
1.3 pytorch 搭建 LeNet5网络
使用pytorch 搭建LeNet5 手写数字识别,并转为onnx格式。
- 导入相关模块
import torch
import torch.nn as nn
import torch.optim as optim
import torch.onnx as onnx
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader
- 定义训练参数
n_epochs = 3
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
log_interval = 10
random_seed = 42
torch.manual_seed(random_seed)
- 加载数据集
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.mnist.MNIST('./mnist/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.mnist.MNIST('./mnist/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])),
batch_size=batch_size_test, shuffle=True)
- 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
- 损失函数
# 定义模型和损失函数
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
train_losses = []
train_counter = []
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
- 开始训练
def train(epoch):
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item())
train_counter.append(
(batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))
torch.save(network.state_dict(), './lenet5.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
def test():
network.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
- 转为onnx格式
# 加载 PyTorch 模型
network.load_state_dict(torch.load("lenet5.pth"))
# 将 PyTorch 模型转为 ONNX 模型
input_shape = (1, 1, 28, 28)
dummy_input = torch.randn(input_shape)
onnx.export(network, dummy_input, "lenet5.onnx")
2、将onnx转为tensorRT
2.1 tensorRT 介绍
TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习应用提供低延迟、高吞吐率的部署推理。
TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。
TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如caffe,TensorFlow等。
由于训练的网络模型可能会很大(比如,inception,resnet等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。
为了提高部署推理的速度,出现了很多模型优化的方法,如:模型压缩、剪枝、量化、知识蒸馏等,这些一般都是在训练阶段实现优化。
而TensorRT 则是对训练好的模型进行优化,通过优化网络计算图提高模型效率。

当网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等),如下:
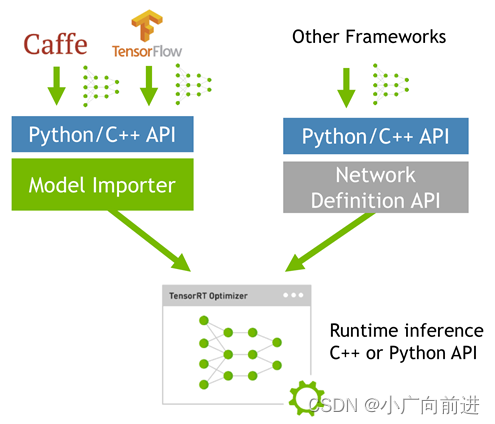
2.1 onnx 转为 tensorRT
import tensorrt as trt
TRT_LOGGER = trt.Logger()
# 加载 ONNX 模型
onnx_file_path = "lenet5.onnx"
def build_engine(onnx_file_path, engine_file_path):
'''
从ONNX文件创建TensorRT引擎以运行推理
:return:
'''
# 创建一个TensorRT builder
builder = trt.Builder(TRT_LOGGER)
# 设置可由构建器使用的最大线程数
builder.max_threads = 10
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, TRT_LOGGER)
runtime = trt.Runtime(TRT_LOGGER)
# 设置可由运行时使用的最大线程数
runtime.max_threads = 10
# 解析模型文件
with open(onnx_file_path, "rb") as model:
print("开始ONNX文件解析")
if not parser.parse(model.read()):
print("错误:无法解析ONNX文件")
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
print("完成ONNX文件解析")
# 打印输入信息
print("Network inputs:")
for i in range(network.num_inputs):
tensor = network.get_input(i)
print(tensor.name, tensor.dtype, tensor.shape)
config = builder.create_builder_config()
config.set_flag(trt.BuilderFlag.REFIT)
config.max_workspace_size = 1 << 28 # 256MiB
plan = builder.build_serialized_network(network, config)
engine = runtime.deserialize_cuda_engine(plan)
with open(engine_file_path, "wb") as f:
f.write(plan)
return engine
build_engine(onnx_file_path, "lenet5.engine")
3、opencv加载图片,并使用tensorRT 加速推理
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import cv2
TRT_LOGGER = trt.Logger()
# 加载 TensorRT Engine
engine_file_path = "lenet5.engine"
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
# 创建执行上下文
context = engine.create_execution_context()
# 分配输入和输出内存
input_shape = (1, 1, 28, 28)
output_shape = (1, 10)
input_host = cuda.pagelocked_empty(trt.volume(input_shape), np.float32)
output_host = cuda.pagelocked_empty(trt.volume(output_shape), np.float32)
input_device = cuda.mem_alloc(input_host.nbytes)
output_device = cuda.mem_alloc(output_host.nbytes)
# 加载测试图像
img = cv2.imread(r"C:\Users\xr\Desktop\0.pgm", cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (28, 28)) / 255.0
# 预处理输入图像
input_data = img.reshape((1,) + img.shape)
input_data = (input_data.astype(np.float32))
input_data = np.expand_dims(input_data, -1)
input_data = 1 - np.transpose(input_data, (0, 3, 1, 2))
# 将数据从主机内存复制到设备内存
np.copyto(input_host, input_data.ravel())
cuda.memcpy_htod(input_device, input_host)
# 执行 TensorRT Engine
context.execute_v2(bindings=[int(input_device), int(output_device)])
# 将数据从设备内存复制到主机内存
cuda.memcpy_dtoh(output_host, output_device)
# 后处理输出数据
prediction = np.argmax(output_host)
print(prediction)
# 显示结果
img = cv2.resize(img, (280, 280))
cv2.putText(img, "label:{}".format(prediction), (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0
cv2.imshow("input image", img)
cv2.waitKey()
cv2.destroyAllWindows()
推理结果