CIFAR-10数据集在计算机视觉领域是一个很重要的数据集,很有必要去熟悉它,我们来到Kaggle站点,进入到比赛页面:https://www.kaggle.com/competitions/cifar-10
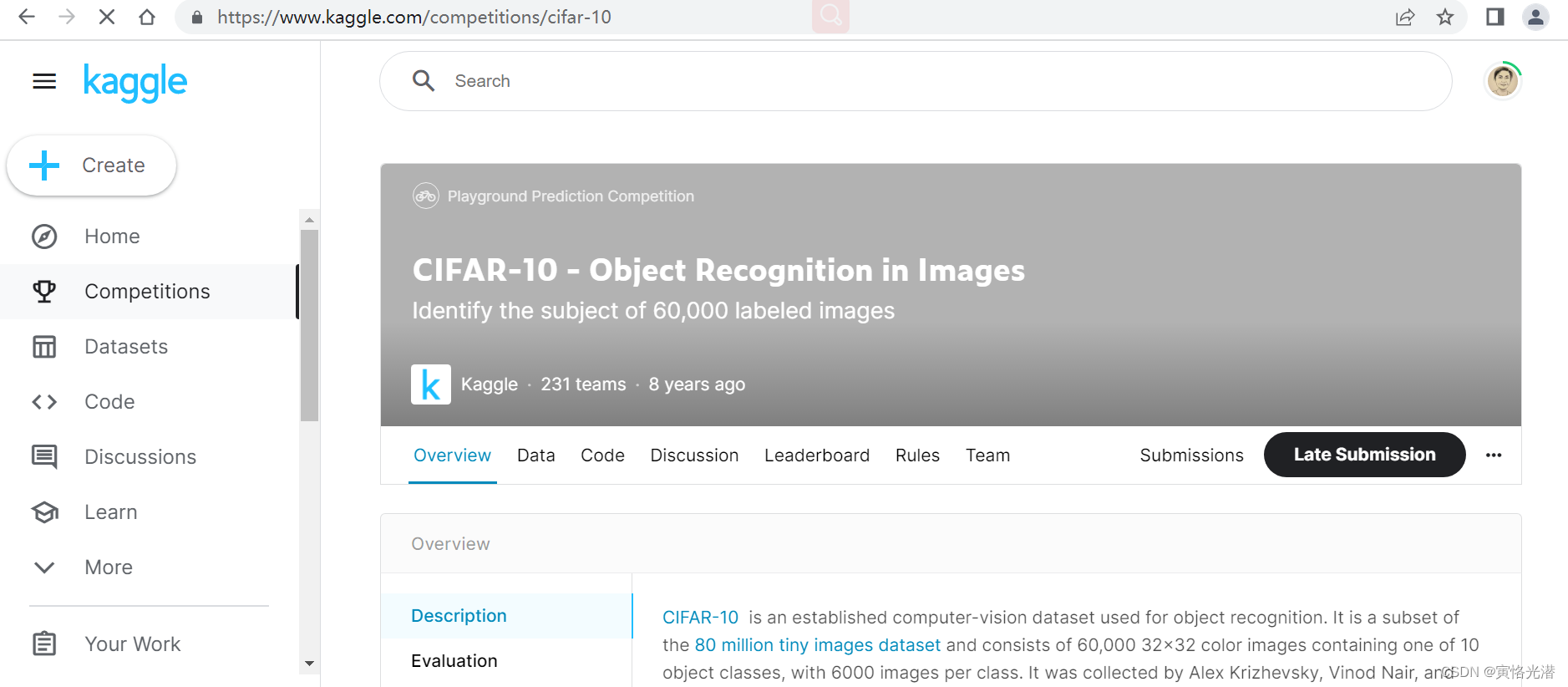
CIFAR-10是8000万小图像数据集的一个子集,由60000张32x32彩色图像组成,包含10个分类,每个类有6000张图像。
官方数据中有5万张训练图片和1万张测试图片。我们保留了原始数据集中的训练/测试分割
在Kaggle比赛提交的时候,为了阻止某些形式的作弊(比如手标),我们在测试集中添加了29万张垃圾图片。这些图像在评分时被忽略。我们还对官方的10000个测试图像进行了微小的修改,以防止通过文件散列查找它们。这些修改不应明显影响得分。您应该预测所有30万张图像的标签。
对于刷排行榜这些我们不用去管,秉持着学习为主的想法,我们来训练这个数据集。分成10个类别,分别为:airplane、automobile、bird、cat、deer、dog、frog、horse、ship、truck
这些类是完全相互排斥的,比如汽车和卡车之间没有重叠。automobile:包括轿车、suv之类的东西。truck:只包括大卡车。这两项都不包括皮卡车。
将下载的数据集放入到dataset目录,解压之后,在这个目录下面有train目录、test目录、trainLabels.csv标签文件,其中train里面是5万张图片、test里面是30万张图片
1、整理原始数据集
1.1读取训练集的标签文件
def read_label_file(data_dir,label_file,train_dir,valid_ratio):
'''
读取训练集的标签文件
参数
valid_ratio:验证集样本数与原始训练集样本数之比
返回值
n_train // len(labels):每个类多少张图片
idx_label:50000个id:label的字典
'''
with open(os.path.join(data_dir,label_file),'r') as f:
lines=f.readlines()[1:]
tokens=[l.rstrip().split(',') for l in lines]
idx_label=dict(((int(idx),label) for idx,label in tokens))
#{'cat', 'ship', 'frog', 'dog', 'truck', 'deer', 'horse', 'bird', 'airplane', 'automobile'}
labels=set(idx_label.values())#去重就是10个类别
n_train_valid=len(os.listdir(os.path.join(data_dir,train_dir)))#50000
n_train=int(n_train_valid*(1-valid_ratio))
assert 0<n_train<n_train_valid
return n_train // len(labels),idx_label我们测试下,先熟悉下这个方法:
data_dir,label_file="dataset","trainLabels.csv"
train_dir,valid_ratio="train",0.1
n_train_per_label,idx_label=read_label_file(data_dir,label_file,train_dir,valid_ratio)
print(n_train_per_label,idx_label)#4500,{id:label,...}读取标签文件,返回每个类有多少个训练样本(id:label这样的id对应标签的字典)
1.2切分验证数据集
上面读取标签的方法中有参数"valid_ratio",用来从原始训练集中切分出验证集,这里设定为0.1
接下来我们将切分的45000张图片用于训练,5000张图片用于验证,将它们分别存放到input_dir/train,input_dir/valid目录下面,这里的input_dir,我这里设置为train_valid_test,在train目录下面是10个分类的目录(这个将定义一个方法自动创建),每个分类目录里面是4500张所属类别的图片;在valid目录下面也是10个分类的目录(同样自动创建),每个分类目录里面是500张所属类别的图片;还有一个train_valid目录,下面同样是10个分类目录,每个类别目录包含5000张图片。
本人的路径如下:
D:\CIFAR10\ dataset\train_valid_test\train\[airplane...]\[1-4500].png
D:\CIFAR10\ dataset\train_valid_test\valid\[automobile...]\[1-500].png
D:\CIFAR10\ dataset\train_valid_test\train_valid\[bird...]\[1-5000].png
这里定义一个辅助函数,新建不存在的路径,将递归新建目录:
#辅助函数,路径不存在就创建
def mkdir_if_not_exist(path):
if not os.path.exists(os.path.join(*path)):
os.makedirs(os.path.join(*path))
def reorg_train_valid(data_dir,train_dir,input_dir,n_train_per_label,idx_label):
'''
切分训练数据集,分别生成train、valid、train_valid文件夹
在这些目录下面分别生成10个类别目录,遍历图片拷贝到对应的类别目录
'''
label_count={}#{'frog': 4500, 'cat': 4500, 'automobile': 4500,...}
for train_file in os.listdir(os.path.join(data_dir,train_dir)):
idx=int(train_file.split('.')[0])
label=idx_label[idx]#类别
mkdir_if_not_exist([data_dir,input_dir,'train_valid',label])
src1=os.path.join(data_dir,train_dir,train_file)
dst1=os.path.join(data_dir,input_dir,'train_valid',label)
shutil.copy(src1,dst1)#将图片拷贝到train_valid_test\train_valid\类别\
if label not in label_count or label_count[label]<n_train_per_label:
mkdir_if_not_exist([data_dir,input_dir,'train',label])
src2=os.path.join(data_dir,train_dir,train_file)
dst2=os.path.join(data_dir,input_dir,'train',label)
shutil.copy(src2,dst2)
label_count[label]=label_count.get(label,0)+1#每个类别数量累加,小于n_train_per_label=4500
else:
mkdir_if_not_exist([data_dir,input_dir,'valid',label])
src3=os.path.join(data_dir,train_dir,train_file)
dst3=os.path.join(data_dir,input_dir,'valid',label)
shutil.copy(src3,dst3)
input_dir='train_valid_test'
reorg_train_valid(data_dir,train_dir,input_dir,n_train_per_label,idx_label)这个图片数量比较多,拷贝过程比较耗时,所以我们可以使用进度条来显示我们拷贝的进展。
from tqdm import tqdm
with tqdm(total=len(os.listdir(os.path.join(data_dir,train_dir)))) as pbar:
for train_file in tqdm(os.listdir(os.path.join(data_dir,train_dir))):
......更多关于进度条的知识,可以参阅:Python中tqdm进度条的详细介绍(安装程序与耗时的迭代)最终结果是训练数据集的图片都拷贝到了各自所对应类别的目录里面。
1.3整理测试数据集
训练与验证的数据集做好,接下来做一个测试集用来预测的时候使用。
def reorg_test(data_dir,test_dir,input_dir):
mkdir_if_not_exist([data_dir,input_dir,'test','unknown'])
for test_file in os.listdir(os.path.join(data_dir,test_dir)):
src=os.path.join(data_dir,test_dir,test_file)
dst=os.path.join(data_dir,input_dir,'test','unknown')
shutil.copy(src,dst)
reorg_test(data_dir,'test',input_dir)这样就将dataset\test中的测试图片拷贝到了dataset\train_valid_test\test\unknown目录下面,当然简单起见直接手动拷贝过去也可以。
2、读取整理后的数据集
2.1、图像增广
为了应对过拟合,我们使用图像增广,关于图像增广在前面章节有讲过,有兴趣的也可以查阅:
计算机视觉之图像增广(翻转、随机裁剪、颜色变化[亮度、对比度、饱和度、色调])
这里我们将训练数据集做一些随机翻转、缩放裁剪与通道的标准化等处理,对测试与验证数据集只做个标准化处理
# 训练集图像增广
transform_train = gdata.vision.transforms.Compose([gdata.vision.transforms.Resize(40),
gdata.vision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
gdata.vision.transforms.RandomFlipLeftRight(),
gdata.vision.transforms.ToTensor(),
gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])
])
#测试集图像增广
transform_test = gdata.vision.transforms.Compose([gdata.vision.transforms.ToTensor(),
gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])])2.2、读取数据集
读取增广后的数据集,使用ImageFolderDataset实例来读取整理之后的文件夹里的图片数据集,其中每个数据样本包括图像和标签。
#ImageFolderDataset加载存储在文件夹结构中的图像文件的数据集
train_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train'), flag=1)
valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'valid'), flag=1)
train_valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train_valid'), flag=1)
test_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'test'), flag=1)
print(train_ds.items[0:2],train_ds.items[-2:])
'''
[('dataset\\train_valid_test\\train\\airplane\\10009.png', 0), ('dataset\\train_valid_test\\train\\airplane\\10011.png', 0)]
[('dataset\\train_valid_test\\train\\truck\\5235.png', 9), ('dataset\\train_valid_test\\train\\truck\\5236.png', 9)]
'''打印的items来看,返回的是列表,里面的元素是元组对,分别是图片路径与标签(类别)值。
然后我们使用DataLoader实例,指定增广之后的数据集,返回小批量数据。在训练时,我们仅用验证集评价模型,因此需要保证输出的确定性。在预测时,我们将在训练集和验证集的并集上训练模型,以充分利用所有标注的数据。
#DataLoader从数据集中加载数据并返回小批量数据
batch_size = 128
train_iter = gdata.DataLoader(train_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
valid_iter = gdata.DataLoader(valid_ds.transform_first(transform_test), batch_size, shuffle=True, last_batch='keep')
train_valid_iter = gdata.DataLoader(train_valid_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
test_iter = gdata.DataLoader(test_ds.transform_first(transform_test), batch_size, shuffle=False, last_batch='keep')3、定义模型
数据集处理好了之后,我们就可以开始定义合适的模型了,我们选用残差网络ResNet-18模型,在此之前我们先使用基于HybridBlock类构建残差块:
#定义残差块
class Residual(nn.HybridBlock):
def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs):
super(Residual, self).__init__(**kwargs)
self.conv1 = nn.Conv2D(num_channels, kernel_size=3,padding=1, strides=strides)
self.conv2 = nn.Conv2D(num_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2D(
num_channels, kernel_size=1, strides=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm()
self.bn2 = nn.BatchNorm()
def hybrid_forward(self, F, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y+X)
定义好了残差块,就可以方便的构建残差网络了。
#ResNet-18模型
def resnet18(num_classes):
net = nn.HybridSequential()
net.add(nn.Conv2D(64, kernel_size=3, strides=1, padding=1),nn.BatchNorm(), nn.Activation('relu'))
def resnet_block(num_channels, num_residuals, first_block=False):
blk = nn.HybridSequential()
for i in range(num_residuals):
if i == 0 and not first_block:
blk.add(Residual(num_channels, use_1x1conv=True, strides=2))
else:
blk.add(Residual(num_channels))
return blk
net.add(resnet_block(64, 2, first_block=True), resnet_block(128, 2), resnet_block(256, 2), resnet_block(512, 2))
net.add(nn.GlobalAvgPool2D(), nn.Dense(num_classes))
return net定义好了模型,在训练之前我们使用Xavier随机初始化,我们这里是CIFAR10数据集,有10个分类,所以最终的稠密层我们输出的是10:
def get_net(ctx):
num_classes = 10
net = resnet18(num_classes)
net.initialize(ctx=ctx, init=init.Xavier())
return net
loss=gloss.SoftmaxCrossEntropyLoss()4、训练模型
模型初始化好了之后,就可以对其进行训练了,定义一个训练函数train:
def train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay):
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr, 'momentum': 0.9, 'wd': wd})
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
if epoch > 0 and epoch % lr_period == 0:
trainer.set_learning_rate(trainer.learning_rate*lr_decay)
for X, y in train_iter:
y = y.astype('float32').as_in_context(ctx)
with autograd.record():
y_hat = net(X.as_in_context(ctx))
l = loss(y_hat, y).sum()
l.backward()
trainer.step(batch_size)
train_l_sum += l.asscalar()
train_acc_sum += (y_hat.argmax(axis=1) == y).sum().asscalar()
n += y.size
time_s = "time %.2f sec" % (time.time()-start)
if valid_iter is not None:
# 评估给定数据集上模型的准确性《使用验证集》
valid_acc = d2l.evaluate_accuracy(valid_iter, net, ctx)
epoch_s = ("epoch %d,loss %f,train acc %f,valid acc %f," %
(epoch+1, train_l_sum/n, train_acc_sum/n, valid_acc))
else:
epoch_s = ("epoch %d,loss %f,train acc %f," %
(epoch+1, train_l_sum/n, train_acc_sum/n))
print(epoch_s+time_s+',lr '+str(trainer.learning_rate))定义好了train函数,就可以进行训练了
# 开始训练
ctx, num_epochs, lr, wd = d2l.try_gpu(), 1, 0.1, 5e-4
lr_period, lr_decay, net = 80, 0.1, get_net(ctx)
net.hybridize()
train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay)这里我们可以简单的将num_epochs设置为1,只迭代一次看下程序有没有什么bug与运行的怎么样:
epoch 1,loss 2.033364,train acc 0.294133,valid acc 0.345600,time 288.89 sec,lr 0.1
运行是没有什么问题,接下来就正式进入到分类的主题了
5、测试集分类
模型训练没有什么问题,超参数什么的也设置好了,我们使用所有训练数据集(包括验证集)重新训练模型,对测试集进行分类,这里我使用5个迭代来看下效果会是怎么样的:
num_epochs, preds = 5, []
net.hybridize()
train(net, train_valid_iter, None, num_epochs,lr, wd, ctx, lr_period, lr_decay)
for X, _ in test_iter:
y_hat = net(X.as_in_context(ctx))
preds.extend(y_hat.argmax(axis=1).astype(int).asnumpy())
sorted_ids = list(range(1, len(test_ds)+1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.synsets[x])
df.to_csv('submission.csv', index=False)
'''
epoch 1,loss 2.192931,train acc 0.253960,time 346.49 sec,lr 0.1
epoch 2,loss 1.663164,train acc 0.390080,time 118.79 sec,lr 0.1
epoch 3,loss 1.493299,train acc 0.456140,time 118.91 sec,lr 0.1
epoch 4,loss 1.356744,train acc 0.509440,time 117.40 sec,lr 0.1
epoch 5,loss 1.235666,train acc 0.556580,time 114.41 sec,lr 0.1
'''可以看到损失在降低,精度在增加,一切正常,训练完毕将生成一个提交文件:submission.csv
然后将这个submission.csv文件提交看下打分与排名,当然这里可以将迭代次数调大,准确度也是会上来的,我迭代了100次然后提交看下分数如何,结果还是不错的
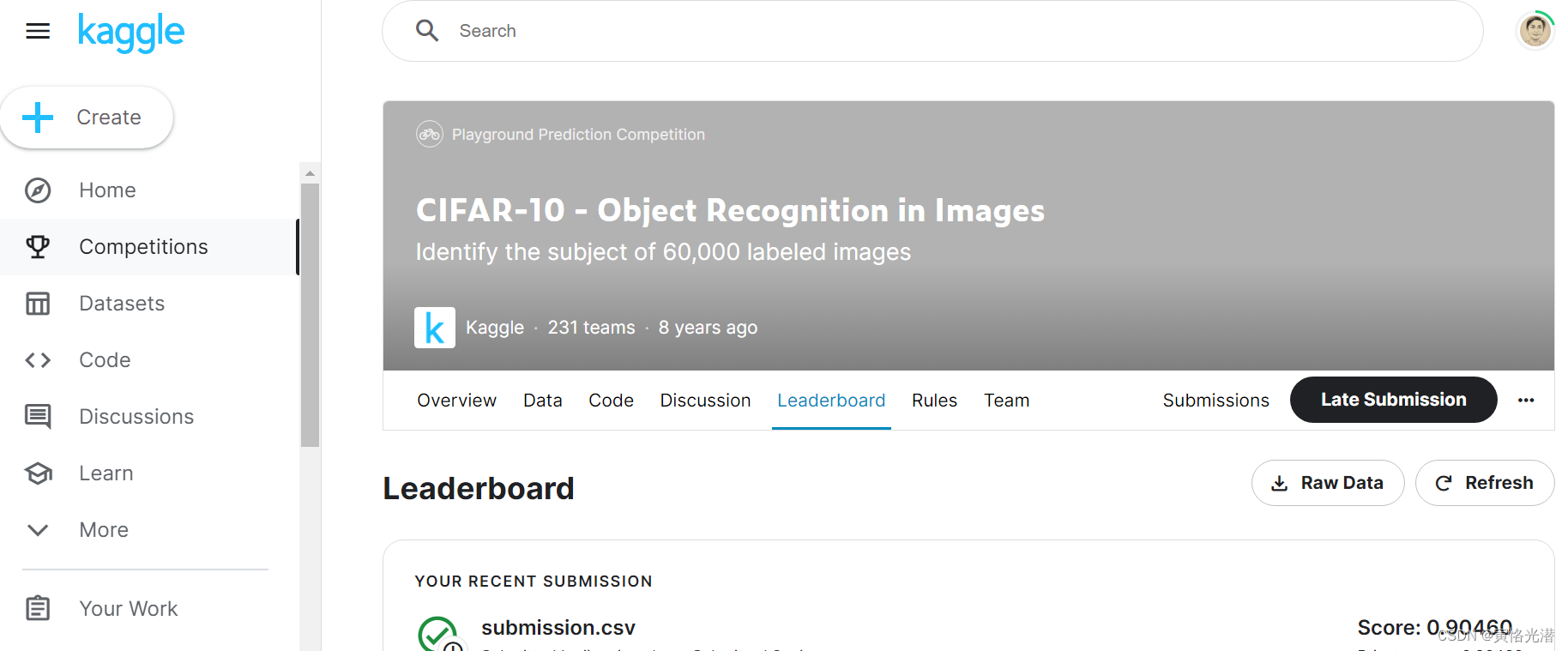
附上全部代码:
import pandas as pd
import d2lzh as d2l
import os
from mxnet import autograd,gluon,init
from mxnet.gluon import data as gdata,loss as gloss,nn
import shutil
import time
def read_label_file(data_dir,label_file,train_dir,valid_ratio):
'''
读取训练集的标签文件
参数
valid_ratio:验证集样本数与原始训练集样本数之比
返回值
n_train // len(labels):每个类多少张图片
idx_label:50000个id:label的字典
'''
with open(os.path.join(data_dir,label_file),'r') as f:
lines=f.readlines()[1:]
tokens=[l.rstrip().split(',') for l in lines]
idx_label=dict(((int(idx),label) for idx,label in tokens))
#{'cat', 'ship', 'frog', 'dog', 'truck', 'deer', 'horse', 'bird', 'airplane', 'automobile'}
labels=set(idx_label.values())#去重就是10个类别
n_train_valid=len(os.listdir(os.path.join(data_dir,train_dir)))#50000
n_train=int(n_train_valid*(1-valid_ratio))
assert 0<n_train<n_train_valid
return n_train // len(labels),idx_label
data_dir,label_file="dataset","trainLabels.csv"
train_dir,valid_ratio="train",0.1
n_train_per_label,idx_label=read_label_file(data_dir,label_file,train_dir,valid_ratio)
#print(n_train_per_label,len(idx_label))
#辅助函数,路径不存在就创建
def mkdir_if_not_exist(path):
if not os.path.exists(os.path.join(*path)):
os.makedirs(os.path.join(*path))
def reorg_train_valid(data_dir,train_dir,input_dir,n_train_per_label,idx_label):
'''
切分训练数据集,分别生成train、valid、train_valid文件夹
在这些目录下面分别生成10个类别目录,遍历图片拷贝到对应的类别目录
'''
label_count={}#{'frog': 4500, 'cat': 4500, 'automobile': 4500,...}
from tqdm import tqdm
with tqdm(total=len(os.listdir(os.path.join(data_dir,train_dir)))) as pbar:
for train_file in tqdm(os.listdir(os.path.join(data_dir,train_dir))):
idx=int(train_file.split('.')[0])
label=idx_label[idx]#类别
mkdir_if_not_exist([data_dir,input_dir,'train_valid',label])
src1=os.path.join(data_dir,train_dir,train_file)
dst1=os.path.join(data_dir,input_dir,'train_valid',label)
#shutil.copy(src1,dst1)#将图片拷贝到train_valid_test\train_valid\类别\
if label not in label_count or label_count[label]<n_train_per_label:
mkdir_if_not_exist([data_dir,input_dir,'train',label])
src2=os.path.join(data_dir,train_dir,train_file)
dst2=os.path.join(data_dir,input_dir,'train',label)
#shutil.copy(src2,dst2)
label_count[label]=label_count.get(label,0)+1#每个类别数量累加,小于n_train_per_label=4500
else:
mkdir_if_not_exist([data_dir,input_dir,'valid',label])
src3=os.path.join(data_dir,train_dir,train_file)
dst3=os.path.join(data_dir,input_dir,'valid',label)
#shutil.copy(src3,dst3)
input_dir='train_valid_test'
#reorg_train_valid(data_dir,train_dir,input_dir,n_train_per_label,idx_label)
def reorg_test(data_dir,test_dir,input_dir):
mkdir_if_not_exist([data_dir,input_dir,'test','unknown'])
for test_file in os.listdir(os.path.join(data_dir,test_dir)):
src=os.path.join(data_dir,test_dir,test_file)
dst=os.path.join(data_dir,input_dir,'test','unknown')
#shutil.copy(src,dst)
#reorg_test(data_dir,'test',input_dir)
# 训练集图像增广
transform_train = gdata.vision.transforms.Compose([gdata.vision.transforms.Resize(40),
gdata.vision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
gdata.vision.transforms.RandomFlipLeftRight(),
gdata.vision.transforms.ToTensor(),
gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])
])
#测试集图像增广
transform_test = gdata.vision.transforms.Compose([gdata.vision.transforms.ToTensor(),
gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])])
#读取增广后的数据集
#ImageFolderDataset加载存储在文件夹结构中的图像文件的数据集
train_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train'), flag=1)
valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'valid'), flag=1)
train_valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train_valid'), flag=1)
test_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'test'), flag=1)
#print(train_ds.items[0:2],train_ds.items[-2:])
'''
[('dataset\\train_valid_test\\train\\airplane\\10009.png', 0), ('dataset\\train_valid_test\\train\\airplane\\10011.png', 0)]
[('dataset\\train_valid_test\\train\\truck\\5235.png', 9), ('dataset\\train_valid_test\\train\\truck\\5236.png', 9)]
'''
#DataLoader从数据集中加载数据并返回小批量数据
batch_size = 128
train_iter = gdata.DataLoader(train_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
valid_iter = gdata.DataLoader(valid_ds.transform_first(transform_test), batch_size, shuffle=True, last_batch='keep')
train_valid_iter = gdata.DataLoader(train_valid_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
test_iter = gdata.DataLoader(test_ds.transform_first(transform_test), batch_size, shuffle=False, last_batch='keep')
#-----------------定义模型--------------------
#定义残差块
class Residual(nn.HybridBlock):
def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs):
super(Residual, self).__init__(**kwargs)
self.conv1 = nn.Conv2D(num_channels, kernel_size=3, padding=1, strides=strides)
self.conv2 = nn.Conv2D(num_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2D(num_channels, kernel_size=1, strides=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm()
self.bn2 = nn.BatchNorm()
def hybrid_forward(self, F, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y+X)
#ResNet-18模型
def resnet18(num_classes):
net = nn.HybridSequential()
net.add(nn.Conv2D(64, kernel_size=3, strides=1, padding=1),nn.BatchNorm(), nn.Activation('relu'))
def resnet_block(num_channels, num_residuals, first_block=False):
blk = nn.HybridSequential()
for i in range(num_residuals):
if i == 0 and not first_block:
blk.add(Residual(num_channels, use_1x1conv=True, strides=2))
else:
blk.add(Residual(num_channels))
return blk
net.add(resnet_block(64, 2, first_block=True), resnet_block(128, 2), resnet_block(256, 2), resnet_block(512, 2))
net.add(nn.GlobalAvgPool2D(), nn.Dense(num_classes))
return net
def get_net(ctx):
num_classes = 10
net = resnet18(num_classes)
net.initialize(ctx=ctx, init=init.Xavier())
return net
loss=gloss.SoftmaxCrossEntropyLoss()
#---------------------训练函数---------------------
def train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay):
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr, 'momentum': 0.9, 'wd': wd})
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
if epoch > 0 and epoch % lr_period == 0:
trainer.set_learning_rate(trainer.learning_rate*lr_decay)
for X, y in train_iter:
y = y.astype('float32').as_in_context(ctx)
with autograd.record():
y_hat = net(X.as_in_context(ctx))
l = loss(y_hat, y).sum()
l.backward()
trainer.step(batch_size)
train_l_sum += l.asscalar()
train_acc_sum += (y_hat.argmax(axis=1) == y).sum().asscalar()
n += y.size
time_s = "time %.2f sec" % (time.time()-start)
if valid_iter is not None:
# 评估给定数据集上模型的准确性《使用验证集》
valid_acc = d2l.evaluate_accuracy(valid_iter, net, ctx)
epoch_s = ("epoch %d,loss %f,train acc %f,valid acc %f," %
(epoch+1, train_l_sum/n, train_acc_sum/n, valid_acc))
else:
epoch_s = ("epoch %d,loss %f,train acc %f," %
(epoch+1, train_l_sum/n, train_acc_sum/n))
print(epoch_s+time_s+',lr '+str(trainer.learning_rate))
# 开始训练
ctx, num_epochs, lr, wd = d2l.try_gpu(), 1, 0.1, 5e-4
lr_period, lr_decay, net = 80, 0.1, get_net(ctx)
#net.hybridize()
#train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay)
num_epochs, preds = 100, []
net.hybridize()
train(net, train_valid_iter, None, num_epochs,lr, wd, ctx, lr_period, lr_decay)
for X, _ in test_iter:
y_hat = net(X.as_in_context(ctx))
preds.extend(y_hat.argmax(axis=1).astype(int).asnumpy())
sorted_ids = list(range(1, len(test_ds)+1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
#apply应用synsets方法,将0~9的数字分别转换为airplane、automobile...对应的类别
#synsets方法大家可以看定义,就是获取文件夹名称(类别)
df['label'] = df['label'].apply(lambda x: train_valid_ds.synsets[x])
df.to_csv('submission.csv', index=False)

![[ 对比学习篇 ] 经典网络模型 —— Contrastive Learning](https://img-blog.csdnimg.cn/efd2df2692f540e3bca5e89c2c9e7660.png#pic_center)