一、x64程序的内存和通用寄存器
随着游戏行业的发展,x32位的程序已经很难满足一些新兴游戏的需求了,因为32位内存的最大值为0xFFFFFFFF,这个值看似足够,但是当游戏对资源需求非常大,那么真正可以分配的内存就显得捉襟见肘了,于是很多公司尝试并成功的开发了64位的游戏。并且很多32位的游戏也在向64位转型。
很多初学者在刚刚接触64位程序时会觉得很陌生,想象着这是一个新的领域,会比32位的分析难度高很多。其实当你对32位的逆向有一定的基础和理解的时候,再来看64位就不那么难了。
64位与32位最直观的区别就是他可分配的内存最大值是0xFFFFFFFFFFFFFFFF。有人可能会说这也就比32位的多了一倍,其实不然,他的大小是32位的0x100000000倍。这个大小就足够我们去使用了,甚至当你在分析64位的游戏时会发现,很多地址也仅仅是1XXXXXXXX,因为目前来说这些也就足够了。
64位与32位逆向的第二个区别就是他的通用寄存器,他的通用寄存器为16个而不是8个(如图)
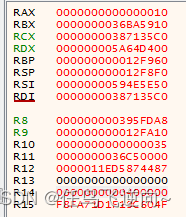
在这16个寄存器中,前面8个的名字与32位的很像,只是前面的E改为了R。后面的8个则以R8-R15命名。当然我们所说的这16个是通用寄存器,而后面还有16个128位的XMM寄存器(如图)以及16个256位的YMM寄存器

在初学者的学习中,我们主要来学习通用寄存器的使用。
RAX与EAX的作用是类似的,他主要用来存放函数的返回值,他的数值也是经常会变化的(如图)

图中是一个随意截取的一断64位函数代码,函数后面的RAX传递给RDI,其实就是将返回值进行传递,这里了解一下即可,后面还会详细讲解。
RCX,RDX,R8,R9则常常会做为第1-4个参数(如图)
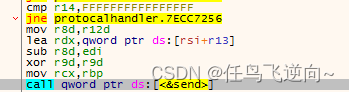
图中是一个程序调用send函数的代码,RCX-R9分别为函数的s,buf,len,flags,当然这只是前4个参数,详细的内容我们放到后面来讲。
RSP和32位中的ESP是类似的,同样作为堆栈指针(如图)
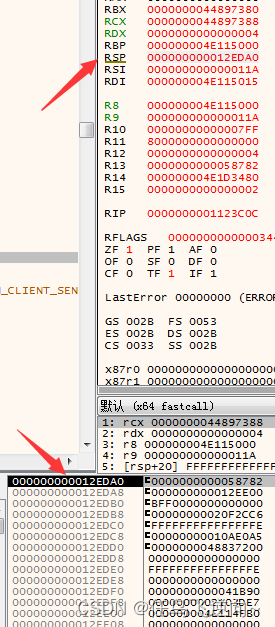
RBP虽然偶尔会用来作为帧指针,也就是所谓的栈底,但是显然没有32位用的频繁,下图则是RBP在函数头部被赋值的情况(如图)

当然RBP也常常会被用作普通的寄存器去进行传址。
R10和R11在syscall/sysret 指令中会被使用,暂时只需要了解一下即可。
而这些寄存器中,除了RAX,RCX,RDX,R8,R9,RSP之外的寄存器,如果在函数过程中被调用,则必须在调用前对其数值进行保留(如图)


以上就是初学者对x64通用寄存器需要掌握的内容,这只是寄存器最基本的分析方法和用法。
至于XMM和YMM寄存器,虽然在32位中也有应用,但是并没有x64应用的那么广泛,甚至在OllyIDE调试器中都没有显示XMM和YMM寄存器的数值。
由于这两种寄存器的指令比较复杂,所以我们在后面的实际应用中再进行学习。
二、64位数据扫描及工具介绍
x64位程序的分析,主要用到两款工具,而这两款工具同x32位程序的分析工具类似,一款是CE,另一款则是x64dbg。
CE与32位的用法大致相同,主要用来对数据的突破口及地址进行扫描(如图)
有人可能会说64位程序应该用8字节来扫描,其实大部分作为突破口的数据都是从4字节开始扫描的,因为64位地址的需求还不是那么大,有些程序数据中只有地址和一小部分数值是8字节的,其他大部分基础数据还是习惯用4字节来存放。比如某个存放血量值的数据,由于数值的范围并不需要太大,所以DWORD就足够了,此时一个8字节的地址就可能会在低32位和高32位分别存放当前血量和最大血量两个数值。此时,如果我们用8字节来扫描血量的话,可能就扫描不到了。
有时候,在x64的程序里,我们也会遇到只有8字节有效数值的地址,但这并不是代表这个地址只有8字节,因为所有的地址都是8字节的,就好比x32程序里的所有地址都是4字节的一样。
ce的其他功能和32位都大体相同,毕竟是同一款软件的不同版本,这里就不过多的讲解了。
下面我们来看一下x64dbg,xdbg也分为32和64版本,他的界面和功能都和OD很像。随着对OD的检测力度越来越大,xdbg也逐渐成为逆向调试器的主流。不过xdbg的插件和OD是有一些差异的,所以初学者用起来并不是特别习惯。
由于OD并没有更新比较实用的x64版本,而且还没有大量插件做辅助,所以在我们调试x64程序的时候只能实用x64dbg。当然有时候我们也会用ida做一些静态分析,来配合xdbg使用。

图中是一款xdbg64的界面,从左到右,从上到下,依次为反汇编窗口,寄存器窗口,参数窗口,数据窗口,以及堆栈窗口。这些都是xdbg64的常用显示窗口,除了参数窗口是为了让我们更加清晰和容易的分析x64程序的函数参数,其他的和OD都没有什么差别。这些调试器的用法在其他的文章里都做过详细的讲解,这里就不做过多的描述了。
三、x64函数约定
在默认情况下,x64程序使用fastcall函数约定,与大部分32位程序最大的区别就是他的参数并不是通过push来进行传递的,而是默认将前4个参数存放在rcx,rdx,r8,r9中。

图中我们传递是4个int型数值,所以传递的寄存器为低32位寄存器,不难看出,这个x64程序是符合我们上面所说的函数约定的。
但是并不是所有的函数都只会用到不超过4个参数,所以,我们还要考虑有更多参数的情况。
当参数多于4个时,x64程序会将多出来的参数传递给[rsp+0x20],[rsp+0x28]......[rsp+(n+1)*8]

图中的第5个参数传递给了[rsp+0x20]。
有人可能在翻阅资料的时候会看到,有的人说第5个参数是[rsp+28],这种说法也没错,因为这两种情况观察参数的位置是不同的
如果我们在函数调用处观察参数,第5个参数是[rsp+0x20],如果我们在函数内部去观察,由于步进call的过程中会push RIP,所以此时的rsp是要-8的,所以第五个参数自然就变成了[rsp+0x28]。
虽然在x64程序中,我们默认的前4个参数是rcx-r9,但是也有例外,如果我们传递的参数是浮点型的话,那么传入浮点数的参数则会使用xmm0-xmm3来代替。

图中的第3个参数,也就是原本的r8的位置,此时已经变成了xmm2,而r8并没有做为参数传递到函数里。也就是说,如果在前4个参数中存在浮点数的话,那么,它所对应的4个通用寄存器则会被xmm寄存器所替代。
现在参数我们已经有个大概的了解了,接下来则是函数的返回值。
之前我们说过,函数的返回值是存放在rax寄存器中的,这一点和32位程序是一样的。

图中的返回值是传递给rax,如果我们返回的是个int型数值的话,那么返回值还是会像32位程序一样传给eax的。
但是这个返回值也会有例外,比如我们要返回一个浮点型的话,那么此时的返回值就会传递给xmm0,在函数执行之后rax就没有用武之地了。

在返回 __m128、 __m128i、 __m128d、float、double时,返回值会传递给xmm0,其他情况则会传递给rax。
四、x64的堆栈
32位的堆栈可以说是初学者的噩梦,很多人在学习堆栈时耗费了大量的时间,这不仅仅是因为堆栈先进后出的抽象概念,同样也是因为32位的函数运行中常常使用push,pop来传递参数和维持堆栈平衡。
x64程序的函数约定可以说是初学者的福音,在汇编代码中没有了满窗口的push、pop、add esp,xxx、sub esp,xxx,这使得堆栈的运算变得格外的简单。

比如图中我们想要分析[rsp+F8]的来源,如果他是作为参数来源于上面的某个CALL中的话,那么我们只需要高亮F8,就可以轻松的找到他所在的CALL,并不需要担心rsp在这个过程中的变化,因为rsp基本上不会改变。很明显,他的来源就在上面的一个call里

这里他作为第三个参数传递到了call里,那么如果他不是来源于某个call里,而是来源于外层的呢?那也很简单,我们直接来到函数头部,计算一下他在函数头部是rsp+?,然后在返回接着去分析就可以了。

比如这里有一个[rsp+90],他并没有来源于本层调用的某个函数,那么我们只需要在头部进行计算,减去push rdi和sub rsp,60改变的偏移,变成[rsp+0x28],再减去push RIP的8个字节,就可以得出他来源于外层的[rsp+20],很明显这是第五个参数

执行到返回后我们会发现这个函数的确有第五个参数,他的来源是r12。
在一些程序中,我们还会发现如下代码

此时的寻址方式并不是以rsp为基地址来传递局部变量和参数,那么如果我们想知道一个rbp+xxxx是局部变量还是参数,就需要到头部去进行一个相对复杂的运算,比如图中的rcx来源rbp-59,虽然我们明知他是一个局部变量(因为前面是lea),但是我们也要到头部去算一算,-59-5F= -B8,在头部的地址是rsp-B8,也就是说他是一个局部变量。
这种方式看似复杂,其实很简单,以为他不需要去计算头部的push和sub rsp,事实上这些偏移都是相对于头部的RIP的。
类似的代码还有很多种,不过我们如果单纯的去逆向数据的话,不必考虑这些寻址方式,只要能正确的去进行计算就可以了。