1、前言
在自动化办公中,我们经常需要利用爬虫技能去批量获取网页的数据,但是有时候我们在利用爬虫的时候,会遇到一个问题,就是登录的时候要携带参数,不如账号、密码、其他的加密信息
就好比我现在公司,好多网址都要放一个加密的信息,例如:时间戳+账号+密码,在经过base64加密,但是我们公司的那个我实在不知道怎么加密。。。
所以曲线救国,如果在已登录的网页中,是否可以操控它,让他自动查询,并爬取下来想要的数据呢,这一点完全可行!
主要靠这行代码:
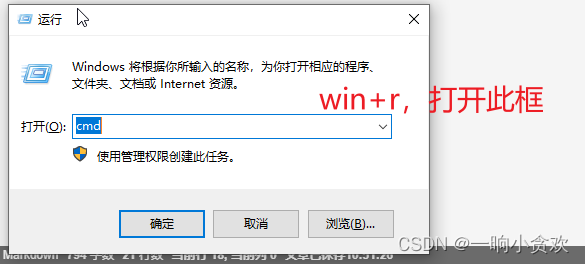
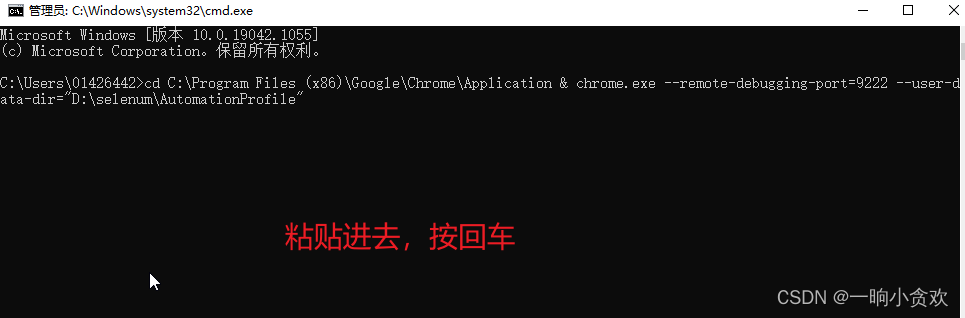
cd C:\Program Files (x86)\Google\Chrome\Application & chrome.exe --remote-debugging-port=9222 --user-data-dir="D:\selenum\AutomationProfile"
分析:
1、:cd C:\Program Files (x86)\Google\Chrome\Application,这是你的谷歌浏览器的位置
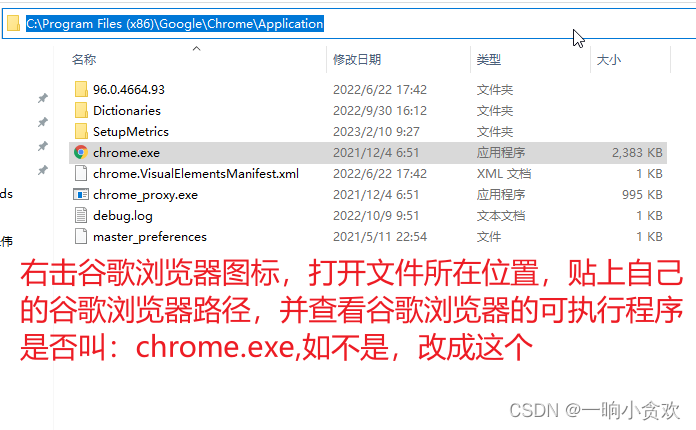
2、:& chrome.exe --remote-debugging-port=9222 --user-data-dir=“D:\selenum\AutomationProfile”
绑定一个端口号,可随意写一个,并在D盘创建一个文件及,忽略我单词写错了😂
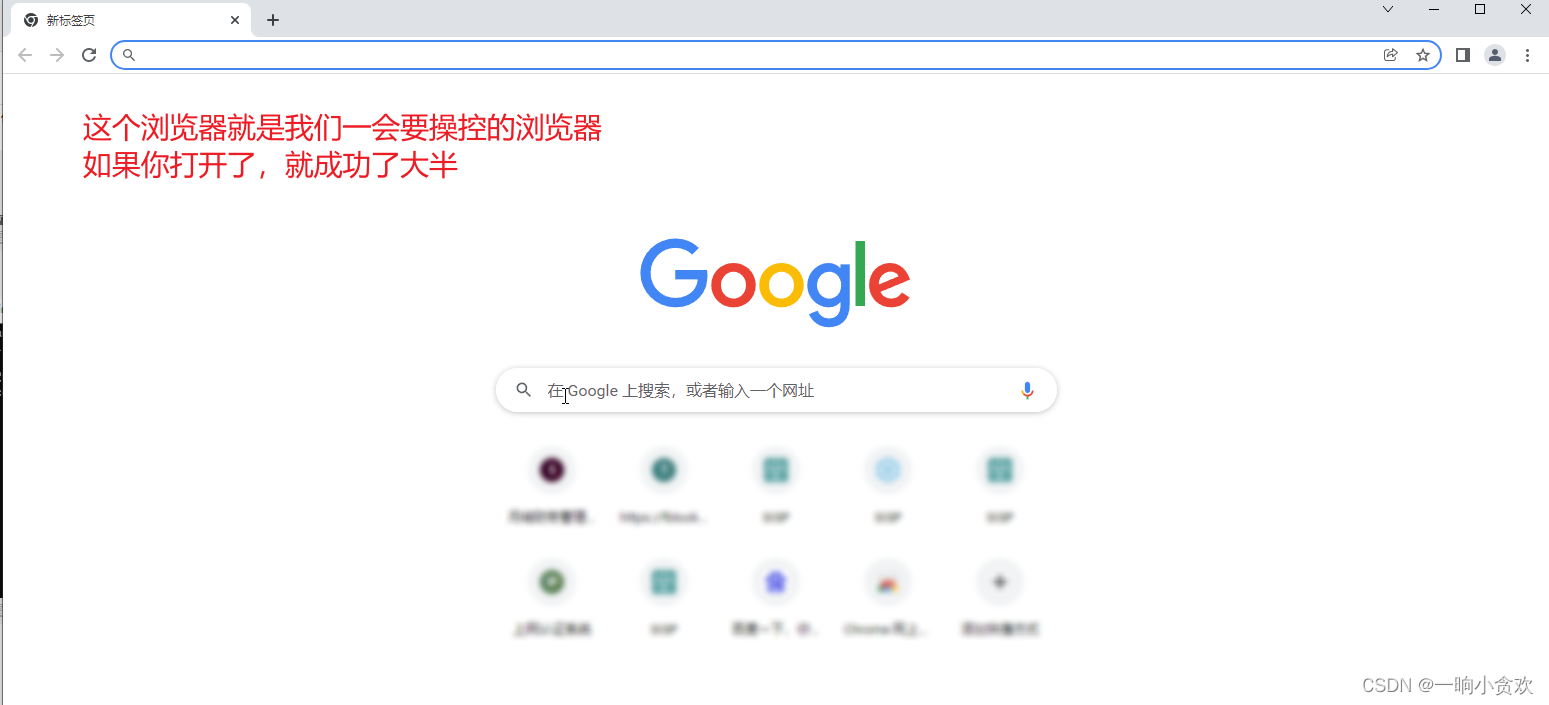
填好之后将代码,粘贴进cmd,按下回车,会打开一个新的浏览器,那么这个浏览器就是我们可控制的浏览器
视频展示

2、那么如何操控这个浏览器呢,代码如下:
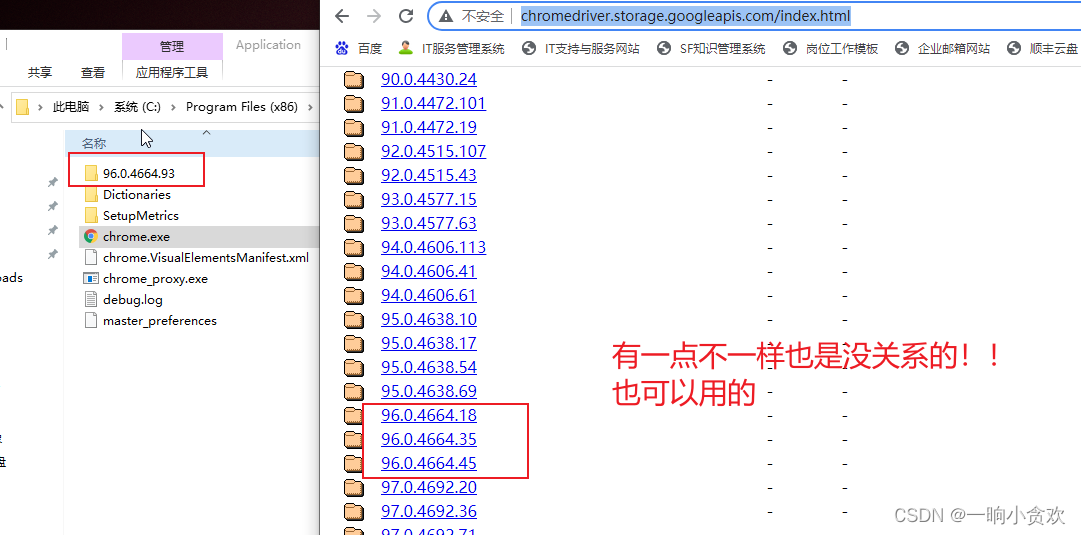
运行之前请将自己浏览器版本的chrome驱动器下载下来备用:点我进入官网下载
测试进入百度
查看目录
只要把谷歌驱动器放进去就好了
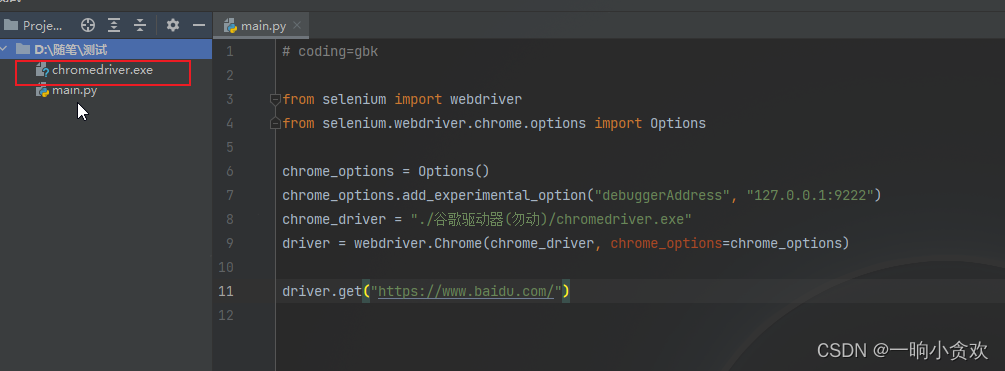
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
chrome_driver = "./谷歌驱动器(勿动)/chromedriver.exe"
driver = webdriver.Chrome(chrome_driver, chrome_options=chrome_options)
driver.get("https://www.baidu.com/")
如果您看到这,那么恭喜你,已经可以操作本地浏览器,即使在登录的情况下,也是可以正常操控!其实目的就是,在登录的情况下,去操控它!
视频展示
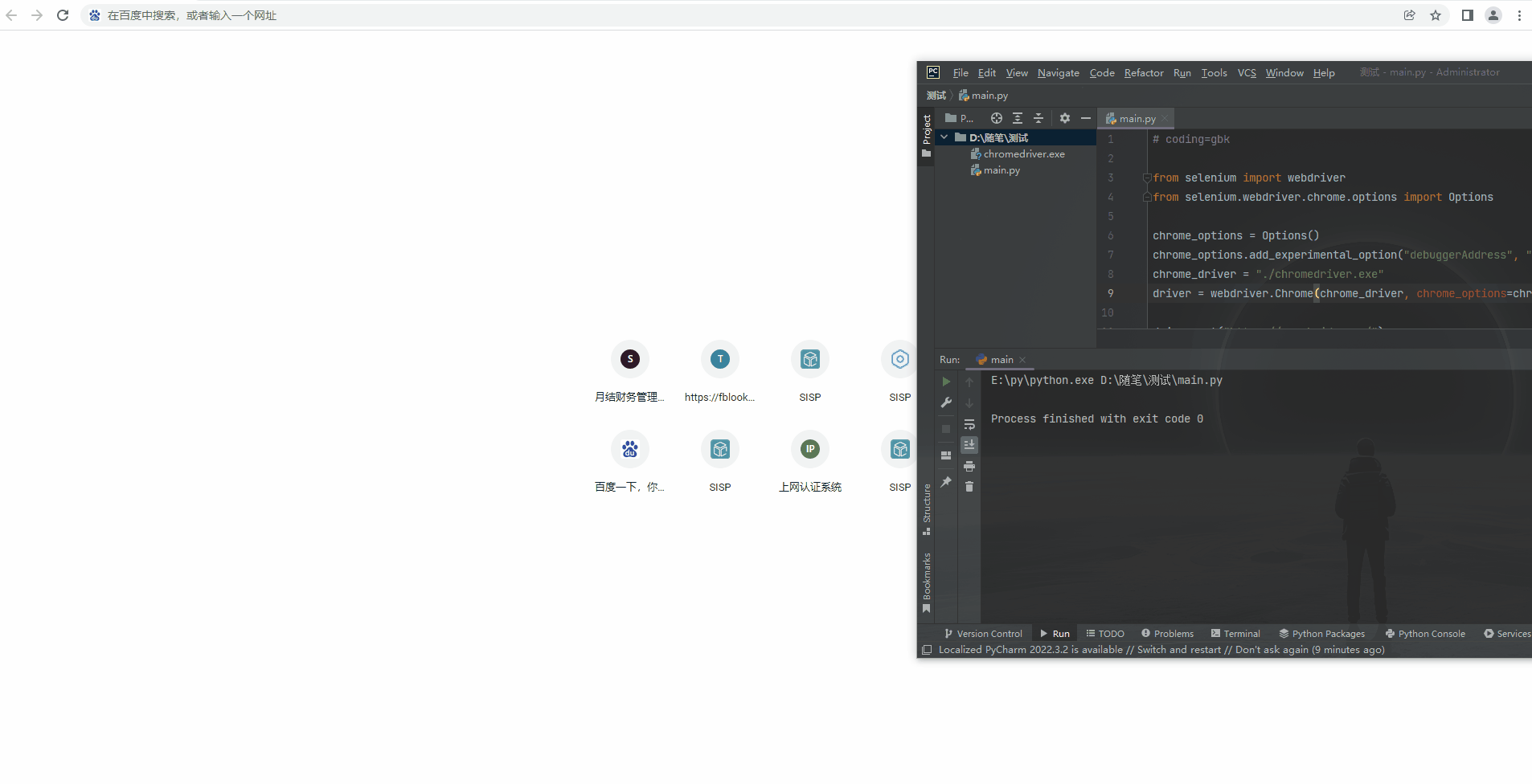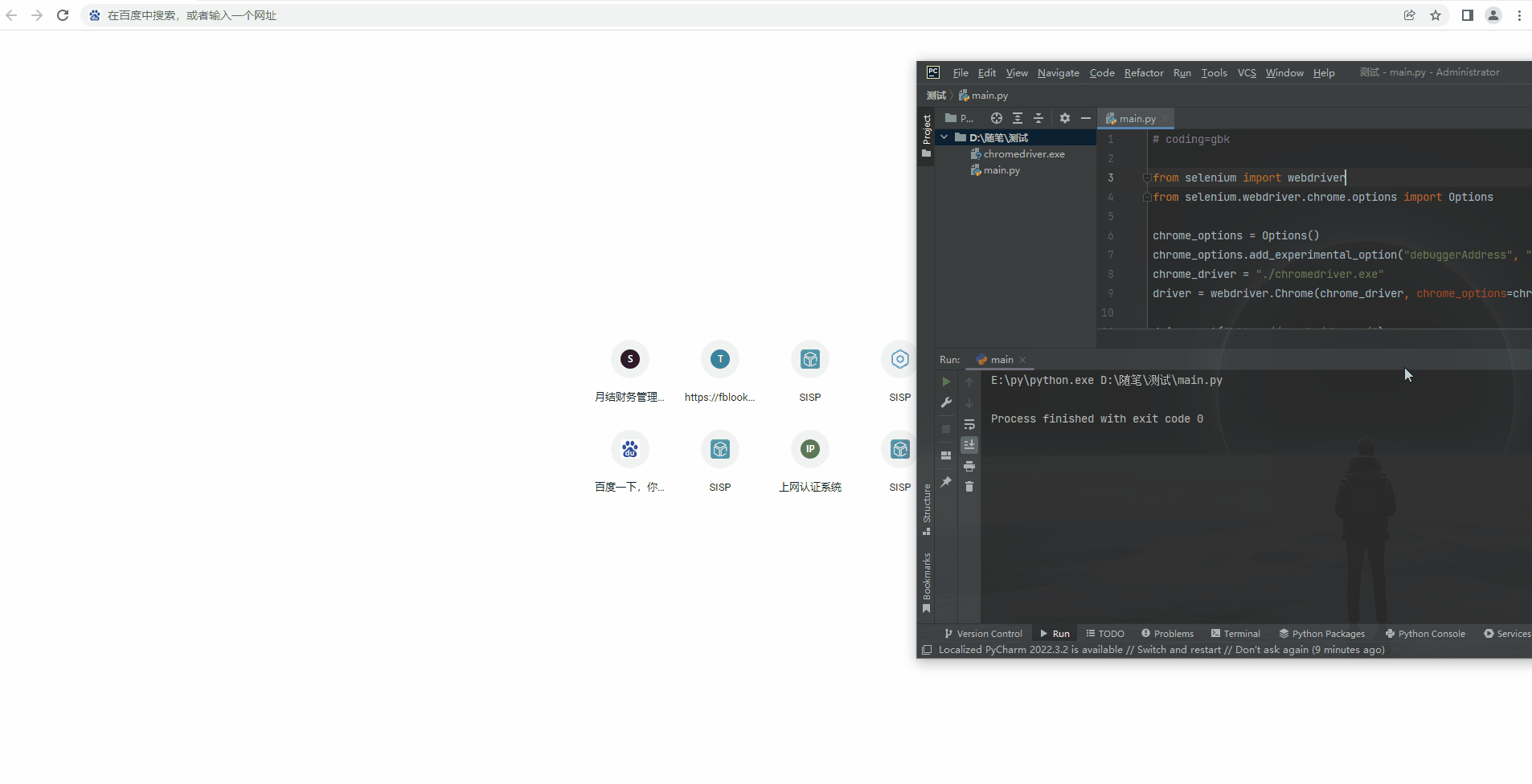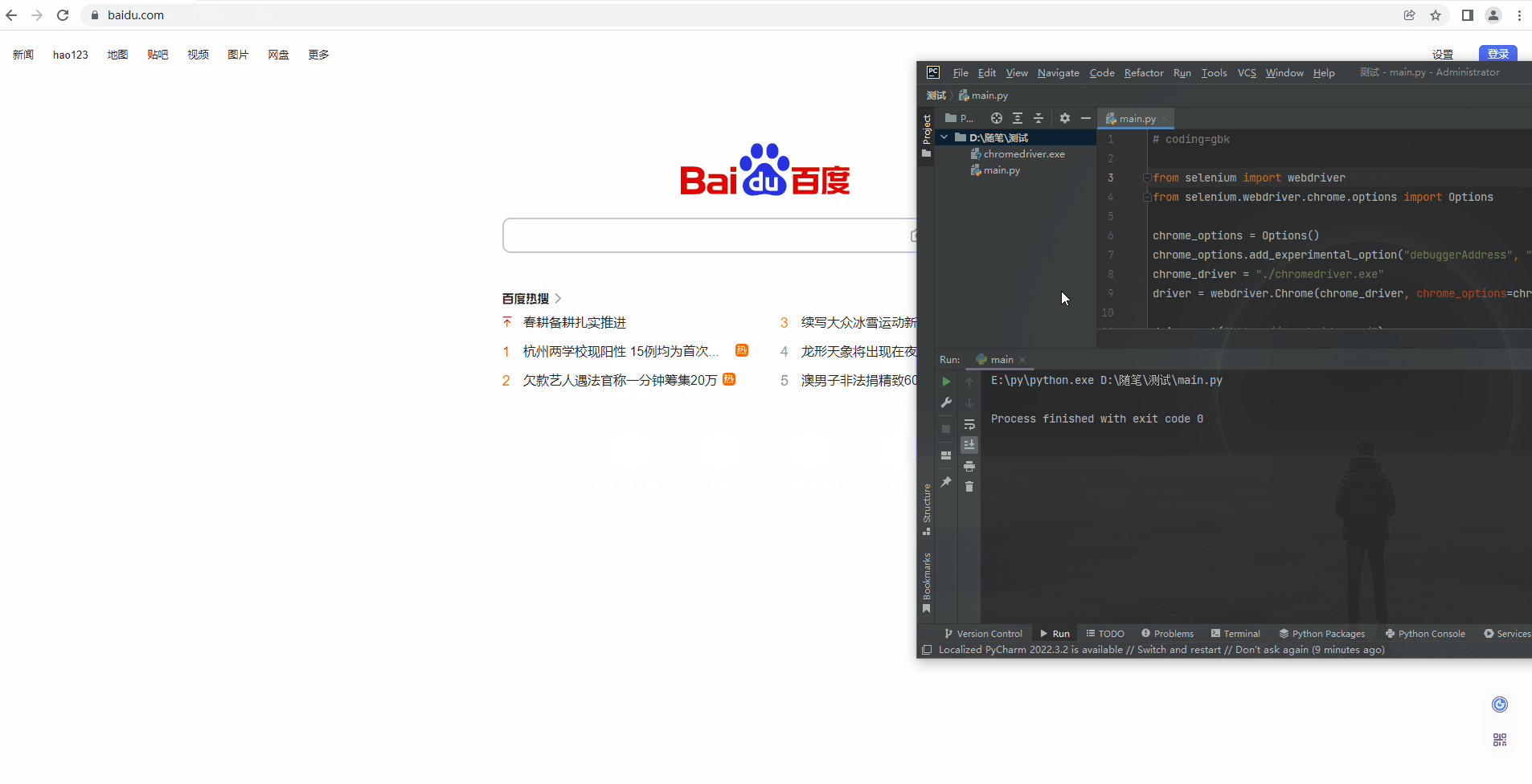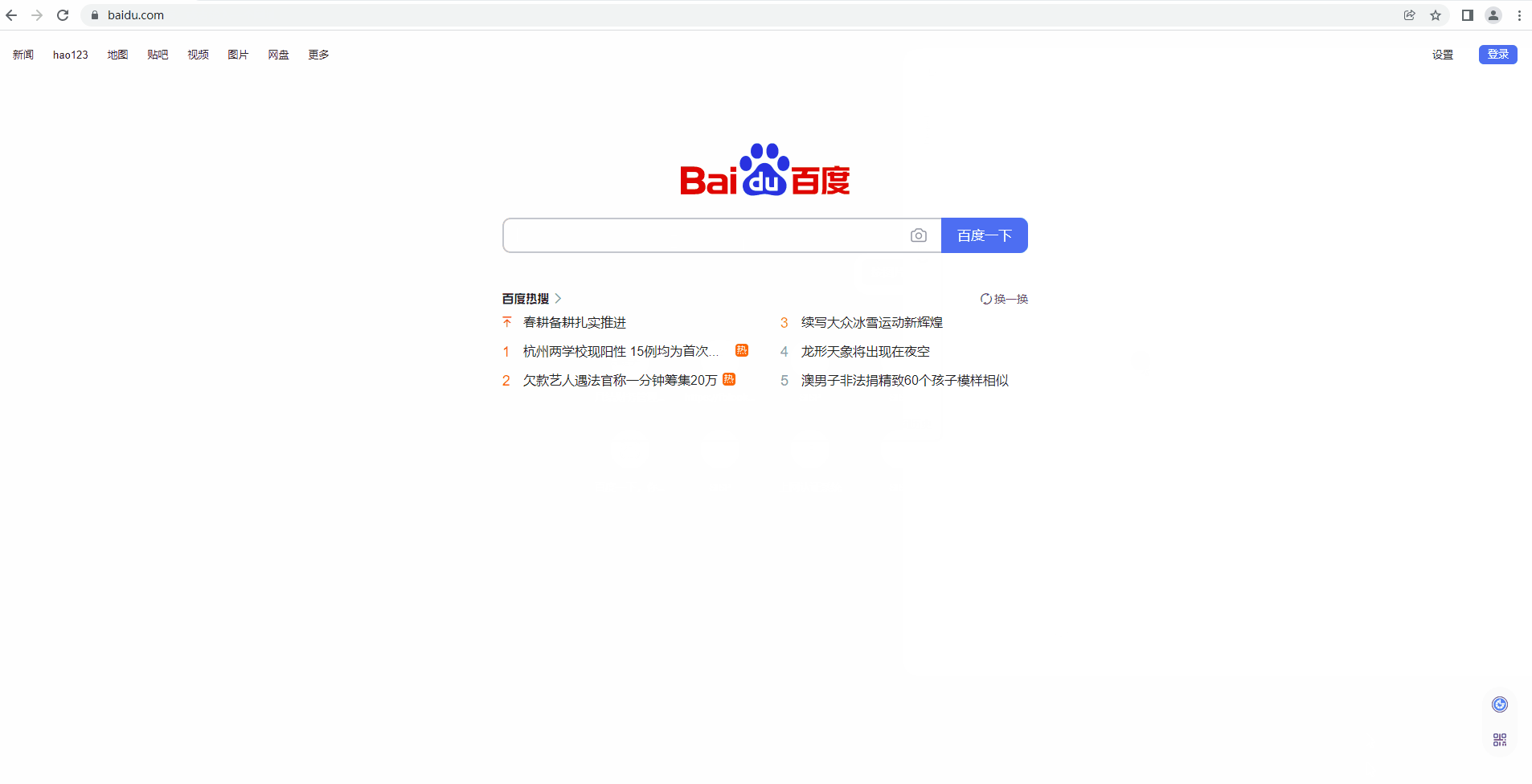
最后获取网页数据,我就不写了,因为下面就是靠Xpath去定位网页元素,如果,如果有小伙伴想学习,评论区说一下,我可以下期讲!
希望对大家有帮助,如有错误,欢迎指正
致力于办公自动化的小小程序员一枚
致力于写出清楚的博客
都看到这了,关注+点赞+收藏=不迷路!!