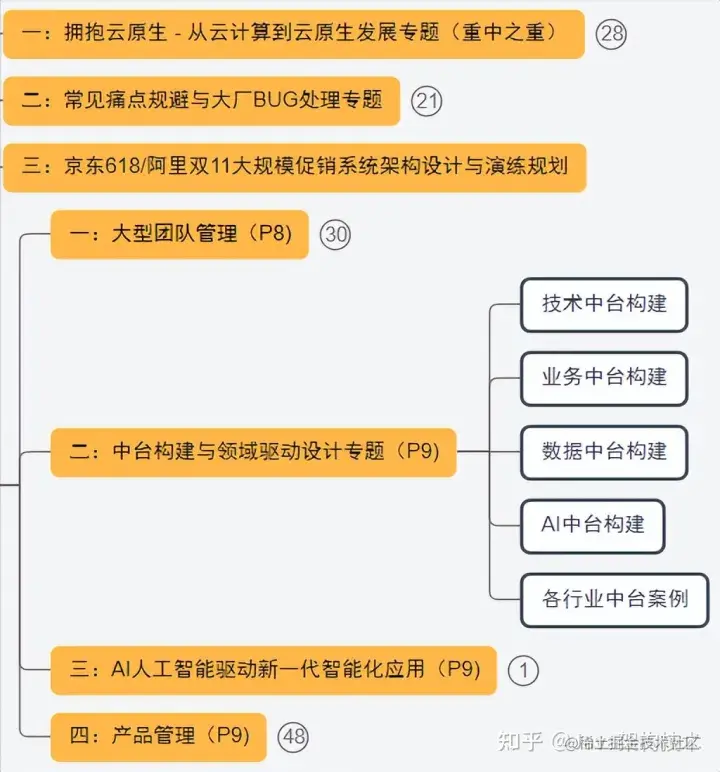
SPDK应用框架
- SPDK应用框架
- 1)对CPU core和线程的管理
- 2)线程间的高效通信
- 3)I/O的处理模型及数据路径的无锁化机制
- SPDK用户态块设备层
- 1.内核通用块层
- 2.SPDK用户态通用块层
- SPDK架构解析
- 3.通用块层的管理
- 4.逻辑卷
- 1)内核LVM
- 2)Blobstore
- 3)SPDK用户态逻辑卷
- 5.基于通用块的流量控制
SPDK应用框架
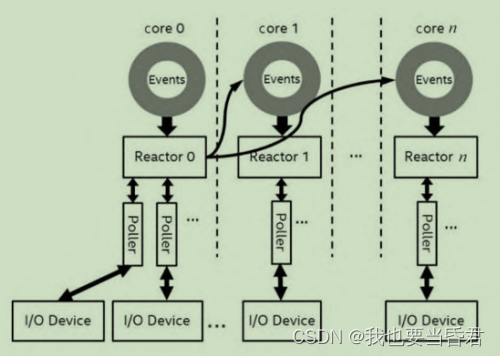
1)对CPU core和线程的管理
SPDK的原则是使用最少的CPU核和线程来完成最多的任务,为此SPDK在初始化程序的时候限定使用绑定CPU的哪些核。通过CPU核绑定函数的亲和性,可以限制对CPU的使用,并且在每个核上运行一个thread,这个thread在SPDK中叫作Reactor。目前SPDK的环境库默认使用了DPDK的EAL库来进行管理。总的来说,这个Reactor thread 执 行 一 个 函 数 _spdk_reactor_run , 这 个 函 数 的 主 体 包 含 一 个“while(1){}”,直到这个Reactor的state被改变。
也就是说,一个使用SPDK编程框架的应用,假设使用了两个CPU core,每个core上就会启动一个Reactor thread,那么用户怎么执行自己的函数呢?为了解决这个问题,SPDK提供了一个Poller机制。所谓Poller,其实就是用户定义函数的封装。
SPDK提供的Poller分为两种:基于定时器的Poller和基于非定时器的Poller。SPDK的Reactor thread对应的数据结构由相应的列表来维护Poller的机制,比如一个链表维护定时器的Poller,另一个链表维护非定时器的Poller,并且提供Poller的注册及销毁函数。在Reactor的while循环中,会不停地检查这些Poller的状态,并且进行相应的调用,这样用户的函数就可以进行相应的执行了。由于单个CPU核上,只有一个Reactor thread,所以同一个Reactor thread中不需要一些锁的机制来保护资源。当然位于不同CPU核上的thread还是有通信的必要的。为此,SPDK封装了线程间异步传递消息(Async Messaging Passing)的功能
2)线程间的高效通信
SPDK放弃使用传统的、低效的加锁方式来进行线程间的通信。为了使同一个thread只执行自己所管理的资源,SPDK提供了事件调用(Event)的机制。这个机制的本质是每个Reactor对应的数据结构维护了一个Event事件的环,这个环是多生产者和单消费者(Multiple Producer Single Consumer,MPSC)的模型,意思是每个Reactor thread可以接收来自任何其他Reactor thread(包括当前的Reactor thread)的事件消息进行处理。
目前SPDK中这个Event环的默认实现依赖于DPDK的机制,这个环应该有线性的锁的机制,但是相比较于线程间采用锁的机制进行同步,要高 效 得 多 。 毫 无 疑 问 的 是 , 这 个 Event 环 其 实 也 在 Reactor 的 函 数_spdk_reactor_run中进行处理。每个Event事件的数据结构包括了需要执行的函数和相应的参数,以及要执行的core。
简单来说,一个Reactor A向另外一个Reactor B通信,其实就是需要Reactor B执行函数F(X),X是相应的参数。基于这样的机制,SPDK就实现了一套比较高效的线程间通信的机制
3)I/O的处理模型及数据路径的无锁化机制
SPDK主要的I/O处理模型是运行直到完成。如前所述,使用SPDK应用框架,一个CPU core只拥有一个thread,这个thread可以执行很多Poller(包括定时器和非定时器)。运行直到完成的原则是让一个线程最好执行完所有的任务。
显而易见,SPDK的编程框架满足了这个需要。如果不使用SPDK应用编程框架,则需要编程者自己注意这个事项。比如使用SPDK用户态NVMe驱动访问相应的I/O QPair进行读/写操作,SPDK提供了异步读/写的函 数 spdk_nvme_ns_cmd_read , 以 及 检 查 是 否 完 成 的 函 数spdk_nvme_qpair_process_completions,这些函数的调用应当由一个线程去完成,而不应该跨线程去处理。
SPDK用户态块设备层
回顾内核态的通用块层来详细介绍SPDK通用块层,包括通用块层的架构、核心数据结构、数据流方面的考量等。最后描述基于通用块层之上的两个特性:一是逻辑卷的支持,基于通用块设备的Blobstore和各种逻辑卷的特性,精简配置(Thin-Provisioned)、快照和克隆等;二是对流量控制的支持,结合SPDK通用块层的优化特性来支持多应用对同一通用块设备的共享。
1.内核通用块层
Linux操作系统的设计总体上是需要满足应用程序的普遍需求的,因此在设计模块的时候,考虑更多的是模块的通用性。
一是容易引入新的硬件,只需要新硬件对应的设备驱动能接入通用的块层即可;
二是上层应用只需要设计怎么和通用块层来交互,而不需要知道具体硬件的特性。
通用块层的引入除了可以提供上面两个优点,还可以支持更多丰富的功能
- 软件I/O请求队列:更多的I/O请求可以在
通用块层暂时保存,尤其是某些硬件本身不支持很高的I/O请求并发量。 - 逻辑卷管理:包括对一个
硬件设备的分区化,多个硬件的整体化逻辑设备,比如支持不同的磁盘阵列级别和纠删码的逻辑卷。又如快照、克隆等更高级的功能。 - 硬件设备的插拔:包括在系统运行过程中的
热插拔。 - I/O请求的优化:比如
小I/O的合并,不同的I/O调度策略。 - 缓存机制:读缓存,不同的写缓存策略。
- 更多的软件功能:基于物理设备和逻辑设备。
由此可见,通用块层的重要性,除了对上层应用和底层硬件起承上启下的作用,更多的是提供软件上的丰富功能来支撑上层应用的不同场景。
2.SPDK用户态通用块层
上层应用是通过SPDK提供的API来直接操作NVMe SSD硬件设备的。这是一个典型的让上层应用加速使用NVMe SSD的场景。但是除了这个场景,上层应用还有更多丰富的场景,如后端管理多种不同的硬件设备,除了NVMe SSD,还可以是慢速的机械磁盘、SATA SSD、SAS SSD,甚至远端挂载的设备。又如需要支持设备的热插拔、通过逻辑卷共享一个高速设备等存储服务。复杂的存储应用需要结合不同的后端设备,以及支持不同的存储软件服务。值得一提的是,有些上层应用程序还需要文件系统的支持,在内核态的情况下,文件系统也是建立在通用块层之上的。类似的文件系统的需求在SPDK用户态驱动中也需要提供相应的支持。
由此可见,在结合SPDK用户态驱动时,也需要SPDK提供类似的用户态通用块层来支持复杂和高性能的存储解决方案。另外,在考虑设计用户态通用块层的时候,也要考虑它的可扩展性,比如是否能很容易地扩展来支持新的硬件设备,这个通用块层的设计是不是高性能的,是否可以最小限度地带来软件上的开销,以充分发挥后端设备的高性能。
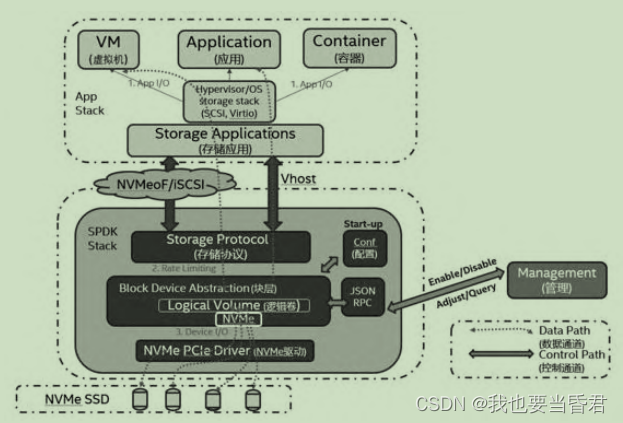
SPDK架构解析
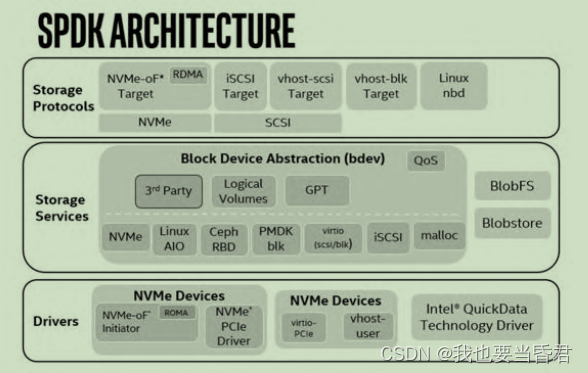
- 最下层为驱动层,管理物理和虚拟设备,还管理本地和远端设备
- 中间层为通用块层,实现对不同后端设备的支持,提供对上层的统一接口,包括逻辑卷的支持、流量控制的支持等存储服务。这一层也提供了对
Blob(Binary Larger Object)及简单用户态文件系统BlobFS的支持 - 最上层为
协议层,包括NVMe协议、SCSI协议等,可以更好地和上层应用相结合
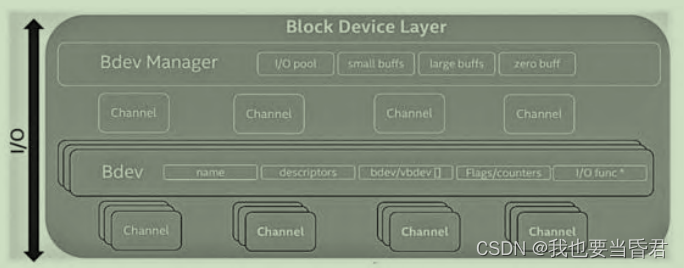
在通用块层引入了逻辑上的I/O Channel概念来屏蔽下层的具体实现。目前来说,I/O Channel和Thread的对应关系也是1∶1的匹配,I/O Channel是上层模块访问通用块层的I/O通道,因此当我们把I/O Channel和块设备暴露给上层模块后,可以很容易地对通用块层进行读/写等各种操作。基于I/O Channel,为了方便操作通用块设备,给每个I/OChannel分配了相应的Bdev Channel来保存块设备的一些上下文,比如I/O操作的相关信息。Bdev Channel和I/O Channel的对应关系也是1∶1匹配
核心的数据结构
- 通用块设备的数据结构:SPDK源码中的struct spdk_bdev结构体。
- 操作通用设备的函数指针表:SPDK源码中的struct spdk_bdev_fn_table结构体。
- 块设备I/O数据结构:SPDK源码中的struct spdk_bdev_io结构体。
能够让通用块层起到承接上层应用的读/写请求,高性能地利用下层设备的读/写性能,在实现高性能、可扩展性的同时,还需要考虑各种异常情况、各种存储特性的需求。这些都是在实现数据流时需要解决的问题。
3.通用块层的管理
管理通用块层涉及两方面问题,一方面是,
对上层模块、对具体应用是如何配置的,怎么样才能让应用实施到某个通用块设备。这里有两种方法,一种是通过配置文件,另一种是通过远程过程调用(RPC)的方法在运行过程中动态地创建和删除新的块设备。
还需要考虑的一个问题是当一个块设备动态创建后,需要做些什么,怎么和已经存在的块设备进行交互,比如提到的基础块设备和虚拟块设备之间的相互关系。这里主要是由struct spdk_bdev_module数据结构来支持的
4.逻辑卷
类似于内核的逻辑卷管理,SPDK在用户态也实现了基于通用块设备的逻辑卷管理。
1)内核LVM
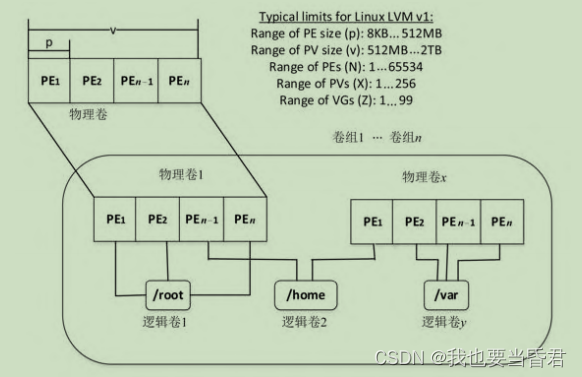
由物理卷入手,可以是硬盘、硬盘分区,或者是外部存储设备的LUN。LVM将每一个物理卷都视作是由一系列称为物理区段(Physical Extent,PE)的块组成的。
通常,物理卷只是简单地一对一映射到逻辑区域(Logical Extent,LE)中。通过镜像,多个物理区段映射到单个逻辑区域。物理区段从物理卷组(Physical Volume Group,PVG)中抽取,这是一组相同大小的物理卷,其作用类似于RAID1阵列中的硬盘。系统将逻辑区域集中到一个卷组中。合并后的逻辑区域可以被连接到称为逻辑卷(简称为LV)的虚拟磁盘分区中。系统可以使用LV作为原始块设备,就像磁盘分区一样,在其上创建可安装的文件系统,或者使用它们作为块存储空间。
2)Blobstore
Blobstore本质上是一个Block的分配管理。如果后端的具体设备具有数据持久性的话,如NVMe SSD,那么Block分配的这些信息,或者元数据可以在断电的情况下被保留下来,等下次系统正常启动时,对应的Block的分配管理依旧有效。
这个Block的分配管理可为上层模块提供更高层次的存储服务,比如这里提到的逻辑卷管理,以及下面将要介绍的文件系统。这些基于Blobstore的更高层次的存储服务,可以为本地的数据库,或者Key/Value仓库(RocksDB)提供底层的支持。
另外,目前的考虑是不去支持复杂的可移植操作系统接口语义。因此,为了避免和传统通用文件系统相混淆,这里我们使用Blob(Binary Large Object)术语,而不是用文件或对象这些在通用文件系统的常用术语。Blobstore的设计初衷和核心思想是要自上而下地实现相同的优化思想——异步与并行,对多个Blob采用的是无锁的、异步并行的读/写操作
通常来说Blob设计的大小是可以配置的,特别针对NAND NVMe SSD硬件设备,Blob的大小可以是NAND NVMe SSD最小擦除单位(块大小)的整数倍。这样可以支持快速的随机读/写性能,同时避免了进行后端NAND管理的垃圾回收工作。
SPDK Blobstore定义了类似的层次结构,需要注意的是这些都是逻辑上的概念,所以如果需要考虑Blobstore在断电的情况下恢复的问题,这些相关的配置信息要么是在本身设计的时候固定的,要么是通过配置在非易失后端设备的特定位置上固定下来的。
- 逻辑块(Logical Block):一般就是指后端具体
设备本身的扇区大小,比如常见的512B或4KiB大小,整体空间可以相应地划分成逻辑块0~N 。 - 页:一个页的大小定义成
逻辑块的整数倍,在创建Blobstore时固定下来,后续无法再进行修改。为了管理方便,比如快速映射到某个具体的逻辑块,往往一个页是由物理上连续的逻辑块组成的。同样地,页也会有相应的索引,从0~N 来指定。 - Cluster:类似于页的实现,
一个Cluster的大小是多个固定的页的大小,也是在Blobstore创建的时候确定下来的。 - Blob:一个Blob是一个
有序的队列,存放了Cluster的相关信息。Blob物理上是不连续的,无法通过索引来读/写某个Cluster,而是需要队列的查找来操作某个特定的Cluster。在SPDK Blobstore的设计中,Blob是对上层模块可见、可操作的对象,隐藏了Cluster、页、逻辑块的具体实现。 - Blobstore:如果
SPDK通用设备的空间被初始化成通过Blob接口来访问,而不是通过固有的块接口来操作,那么这个通用块设备就被称为一个Blobstore(Blob的存储池)
3)SPDK用户态逻辑卷
SPDK用户态逻辑卷基于Blobstore和Blob。每个逻辑卷是多个Blob的组合,它有自己唯一的UUID和其他属性,如别名。
对上层模块而言,这里我们引入一个类似的概念,逻辑卷块设备。对逻辑卷块设备的操作会转换成对SPDK Blob的操作,最终还是依照之前Blob的层次结构,转换成对Cluster、页和设备逻辑块的操作。这里Cluster的大小,如之前所说的,在不考虑原子操作的情况下,可以动态地配置它的大小。
5.基于通用块的流量控制
- 多个应用需要共享一个设备,不希望出现的场景是某个应用长时间通过高I/O压力占用该设备,而影响其他应用对设备的使用。
- 给某些应用指定预留某些带宽,这类应用往往有高于其他应用的优先级。
- 当流量控制功能启用后,静态配置文件或RPC动态配置文件,
需要分配特定的资源和指定特定的线程。这个线程只是逻辑上的概念,本质上是SPDK应用框架分配的单核上唯一的那个线程。 - 在执行流量控制的线程上,
启动一个周期性操作的Poller,或者一个任务来周期性地做些工作。在SPDK的实现中,为了简化这个控制的操作,将1s要达到的流量目标,比如IOps和带宽,对应到更小粒度的目标,比如1ms,或者500μs,所以这个周期性的任务就是每个这样的小周期来处理允许的I/O流量 - 当上层应用关闭掉所有I/O Channel,或者RPC动态停用流量控制后,
所有未处理的I/O请求会被及时处理,完成后释放相应的流量控制分配的资源。
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习