这是一篇半娱乐性的吐槽文章,权当给广大技术人员解解闷:)。
哈哈哈,然后我要开始讲一个经常在发生的事实了。(程序员们可能会感到一些不适

)
99.999999999%做技术的都会被问到或者被吐槽到:“你的程序怎么又出bug了!”
▲图片来源于网络,版权归原作者所有
反正,我作为程序员的内心世界是:如同一万只草泥马飞奔而过,难以压抑内心的激动,每次都差点忍不住想说“你写篇几百字的作文还有错别字呢,我码个几万行的代码还不允许出错了?“
可能同样是做技术的你此时在不断点头,哈哈。
但是这么讲毕竟也缓解不了矛盾,我们还是得摆事实讲道理不是?
啥都不怕,就怕程序员有文化!
所以,Z哥想来带你好好分析一下这个事情,当你再遇到这个情况的时候,可以拿这些观点来反驳(不是做技术的也可以了解下程序员的难处,谁没个难处呢,多多包容)
什么是Bug
任何一个「问题」的产生,本身是没有好坏之分的,但是为什么会有的就不被care,甚至还会很喜欢,而有的会被吐槽呢?根本原因是因为产生了利益损失。
比如年前拼多多出问题送了很多无门槛券。
作为一个用户,自然很喜欢,夸你夸到飞起,怎么会吐槽你呢。但是作为利益损失方,必然破口大骂,害我倾家荡产!
所以,如果没有产生利益损失,我想其他人也不会来找你吐槽。
但是「问题」就等于「bug」吗?我认为并不是,「问题」不等于「 bug」。
因为程序员的职责是什么?拿造房子来比喻的话,我认为最核心的工作真的和“搬砖”(非贬义词)无异,就是根据设计师(产品经理)设计好的设计图砌砖(编码),建成和设计图纸上一模一样的建筑。
所以,如果一个东西造出来与设计不符,那么它可以说是bug或者缺陷(缺斤少两不完整)。否则,并不是bug,但可以被称之为「漏洞」(完全没考虑到的),表示不在预料之内的情况。
之前看到过一个形象的比喻:你家里的窗可以从外面打开,那叫漏洞。你家里的窗打不开,那叫bug。
但是要承认,bug是必然存在的。为什么?它是如何出现的呢?
Bug是如何出现的
正如前面所说,程序员做的是“造房子”的事情。这件事完整的步骤分为3步。
与产品经理讨论并确定功能(确定一个可以实现的设计图纸)
将每个单独的元件抽象出来(确定施工方案)
将相关的元件实现并进行组合,完成建设(带上材料开始施工)
第一步,“与产品经理讨论并确定功能”主要是沟通,靠“看”和“理解”。
但是沟通本身是一个有损耗的过程,特别是在职责非常明确的组织中,产品经理啪啦啪啦讲了很多,到实际做的时候你必然还是会去翻阅需求原型、需求文档之类的重新理解一下。这个时候就是一个非常危险的时期。
比如像下面这个的答案是什么?

▲图片来源于网络,版权归原作者所有
答案是17?不对。
我猜你可能没注意到这些地方。
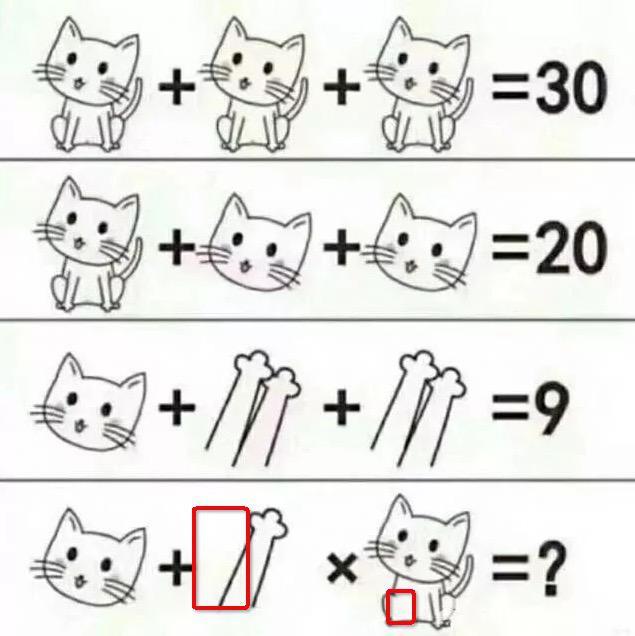
▲图片来源于网络,版权归原作者所有
为了让你有深刻的印象,这个举例可能比较刻意和夸张一些,但是我想在你的身边,由于没注意到或者理解有误的现象肯定很常见。
沟通是相互的,这锅只让程序员背的话的确太委屈了点。
第二步,“将每个单独的元件抽象出来”这主要是一个人抽象能力的体现。
但是抽象是啥?抽象是“透过现象看到本质”的能力,这个能力理论上是可以无限增长的。随着你对相关信息的掌握越多,这个能力会越强,会无限趋近于100%,但永远不会真正达到100%,因为没人知道怎么才算100%。
所以,当你具备的信息没那么多的时候,是不是就抽象的不是那么合理?不合理会导致什么?虽然不会直接产生bug,但是会更容易产生bug。但是人不都是需要经历这么一个成长的过程么?
可以说,精通一项能力的背后都是踩着无数的bug过来的。要么在来这个组织之前已经踩过了,要么在这个组织里踩。因此,前者的薪资也比后者高。
所以,如果过分苛求没有bug,等于是在扼杀每个人成长的机会,并且在透支未来的可能性。人会变得非常保守、不敢尝试新事物。
但是外部环境在不断变化,新事物总会被动的需要去接纳(技术的更新越来越快,趋势不可逆),然而对新事物的接受能力又得不到锻炼,一旦遇到这种情况,在接触新事物的时候会产生更多的问题(欠下的债总要还的)。
第三步,“将相关的元件实现并进行组合,完成建设”这就是实际的coding过程,而coding是一个主观的,完全由人主观掌控的事情。
人毕竟不是机器,不可能不犯错,就如前面提到的写文章的时候出现错别字一样。
可能你会说,有测试人员啊,测试的工作不就是通过逆向思维来给程序员查缺补漏吗?
的确是的,但测试的介入只是降低错误率,只是让不出现bug的概率小数点后多几位
,指望发现100%的问题还是不太现实的。至少在当下的条件下是这样,为什么呢?因为代码的本质是各种逻辑的组合。
比如,一个完整的业务流程有10个环节,每个环节有3种可能性,这是一个什么复杂度的系统?3 ^ 10 = 59049个分支(理论上存在的可能性数量),想要100%覆盖这些场景,付出的成本几乎是不可接受的。
然而我们实际的系统中遇到的个别场景甚至还要复杂的多。
其实每个正在运行的系统都有bug,包括我们每天在使用一些热门系统(玩游戏的小伙伴们肯定熟悉“卡bug”这个词)。只是这些bug有没有被执行到,有没有被发现,被多少人发现而已。
那么,我们只能举手投降吗?那倒不至于,办法还是有的。
减少bug的惯性想法
首先最容易想到的一点是,增加测试人员。
这也是最容易看得到的“成本”一种方式,毕竟招一个人就得支出一份工资啊。所以,增加测试人员这个方案是最不容易被老板们采纳的方案。除非你可以说服这个人力成本的投入小于获得的价值。
另外,这个方案其实还增加了沟通成本,沟通的「隐性成本」其实非常大,但是往往容易被忽略。(关于沟通成本,感兴趣的可以看我之前写的《就简单聊聊沟通效率问题》)
其次会想到的就是程序员代码写的严谨一点,仔细一点啊。这也是一种缺啥补啥的惯性思维。
先撇开到底能不能达到严谨一点,仔细一点的目的。那怕达到了,他会产生什么结果呢?可能是下面3种。
更多的条件验证
更多的单元测试
更多的抽象提炼
可以确定的是,这些工作会增加2样硬性的东西,投入的时间和整体的复杂度。时间很好理解,我们就来聊聊复杂度。
一个常识是,越简单的东西越不容易产生bug。比如1+1=2,出现bug的可能性无非就是加号写成来减号,1写成了4之类。但是,1+1=2,并且1*1=1,并且1/1=1,。。。等等这些验证条件越多,那么由于验证条件自身的错误而产生问题的可能性反而更多。
所以,代码的复杂度和产生bug的概率是成正比的,并且具有「边际效用递减」的效果。这就意味着,做更多的验证带来的收益会越来越小。

因此,这个方案哪怕真能执行到位,也不是一个特别好的方案。
那有没有相对靠谱一些的办法呢?有,但需要我们换一个角度来看待这个问题。
换一个角度看待bug
既然无法100%避免bug,那我们可以换个角度考虑一下,如何让解决bug的过程更快,甚至快到你都没有察觉。
解决bug主要就是做2件事,找到bug的产生点,然后修复它。
每天都在解决bug的程序员们应该知道,这事最费时间的是“找bug”的过程。
因为“修复bug”是一个技术性问题,这个对不同人的差异其实是很小的,因为程序员们每天在写的代码都是差不多的,非常同质化的,况且还有标准答案“文档”可以参考。比如,都知道string.concat()是拼接,string.split()是分割。该用分割的地方不小心用了拼接,那改掉就好。
但是“找bug”就不是这样了。比如,你刚刚改完一行代码后发布出现的问题,你不用找就知道问题出现在哪。但是让你排查一个刚接手没多久的系统肯定是一脸懵逼。
根本原因在于,这个过程不像技术性问题具有确定性,它是充满不确定性的,处在一个“混沌”的环境中。
所以,对待bug的重点就变成了:如何更快的发现和找到bug。
关于这点Z哥的建议是:
打好日志
学会利用工具
每次的迭代规模尽可能的小
首先,打好日志。日志其实就是我们在编码的时候安插在程序中“记录员”,它替我们记录着我们认为容易出现问题的地方所产生的信息。
但是系统无时无刻都在运行着,必然会产生大量的日志信息,如何从这些信息中快速的找到关键信息,就是需要考虑的问题。
另外,如果每个人都随意的用自己喜欢的记录日志的方式,那么从风格迥异的日志中找你需要的信息就变得很头疼,时间不一致,格式不一致等等。
所以,要做好打日志这个事情,就需要定义一个标准,比如必须要有时间,包含当前上下文的参数等等。
我们还可以给日志做一下归类,定义不同的日志级别,在记录的时候带上前缀。比如【info】、【warning】、【error】之类。如此一来,平时更着重关注的就是error级别的信息,而且由于将其他级别的信息剥离了出去,使得这里的数据量大大减少,更便于查看。
不过,日志记录毕竟是一个在做“预判”,如果日志中没有记录到怎么办呢?这里提醒大家不要先想着怎么调试。
如果你面对的系统是一个单体应用倒还好。如果你面对的是一个大型的分布式系统,调试的效率低不说,这事你一个人可能还完不成。而且,如果你直接调试生产环境的话,说不准还会产生什么副作用,摊上新的问题

找bug本质上是一个排除法的过程,设断点调试也是如此。但是从起点开始一步一步的做排除法效率太低了。应该先通过自己的经验、拥有的部分信息先逻辑推理一下,缩小排查的范围。哪怕你最终还是需要调试的话,先做这个事情也会让后续的工作更高效一些。
第二点,利用工具。这里的“工具”不要简单的理解成利用“调试工具”。正如上面提到的,找bug的本质是一个排除法的过程,那么任何能够帮你更高效的做排除法的工具都是可以利用的。比如,
从系统的「事件查看器」中获取更多的环境信息。
利用windows平台的windbg、lunix平台的MAT之类的工具直接分析抓到的dump文件。
借助可视化工具更高效的发现问题,如FlameGraph等。
另外,如果能主动的告诉你哪里出现bug了,就更棒了。所以,我们可以搭建一套查看方便,信息同步及时的日志框架,以便让有价值的信息第一时间呈现在你的面前。如果有高效的筛选功能就更好了。
很多日志框架Z哥没用过,就不发表什么言论了,但是elasticsearch + logstash + kibana这套用起来还是很爽的,体系也比较成熟,部署起来也很简单,大家可以尝试一下。再配上ElastAlert或者Sentinl,可以把实时预警机制也包含了。
最后,每次的迭代规模尽可能的小。这个说起来容易,做起来难,因为这是由整个团队的文化来决定的。这个点的内容完全可以单独开一篇讲,这里就简要阐述下。
MVP(Minimum Viable Product)式的小步快跑,其实除了让系统或者产品的功能演进更科学之外,还可以让每次迭代所面临的风险更小。正如前面提到的,你改一行代码发布上去,如果出问题,你说问题在哪?
相对的,再想象一下,一次性发布一个开发了半年的版本,前一晚能睡的安稳不?