文章目录
- 中间指令格式
- 解码模块的实现
编译器将汇编语句翻译成机器指令,而虚拟机做的工作正好相反,就是将机器指令解码成可以识别的中间形式,然后执行。
为什么要这么做?拿 mov 指令举例,看下它的机器指令的格式:
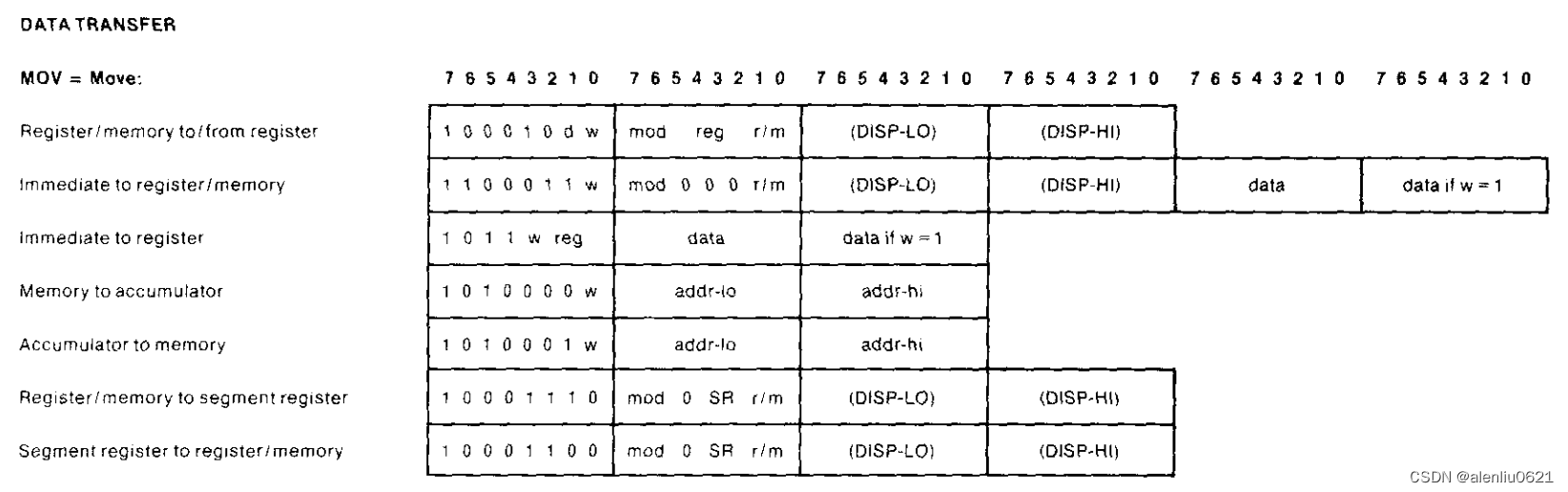
一共有 7 大类,每一类的格式不同,一共有 28 种形式。如果不把机器指令转换成另一种中间格式,那么在写 EU 执行的代码时,必然要将指令解码和执行的逻辑混合在一起,使得代码变得难以维护和扩展。因此我在实现时将解码的部分单独剥离出来,所有的解码都交给解码模块去做。
解码模块提供的解码函数 Decode 原型如下:
func Decode(instructions []byte) []byte
它的输入是机器指令,输出是中间形式的指令格式。
中间指令格式
我定义的中间指令格式是这样的:
指令类型,指令详细类型,[源操作数],[目的操作数]
以下是定义的指令类型,每一个都表示解码模块支持的指令:
const (
InstructionMov uint8 = iota
InstructionAdd
InstructionOr
InstructionAdc
InstructionSbb
InstructionAnd
InstructionSub
InstructionXor
InstructionCmp
InstructionInc
InstructionDec
InstructionNot
InstructionNeg
InstructionMul
InstructionImul
InstructionDiv
InstructionIdiv
InstructionSegPrefix
InstructionPush
InstructionPop
InstructionJmp
InstructionCall
InstructionRet
InstructionRetf
InstructionIret
InstructionLoop
InstructionInt
InstructionNop
InstructionTest
)
比如 mov 指令解码后的中间格式第一字节就是 InstructionMov 。
第二字节表示详细的指令类型,比如 mov 指令,可能是寄存器之间的移动,寄存器和内存直接的移动等等,mov 指令详细类型定义如下:
const (
MovReg8ToReg8 uint8 = iota
MovReg16ToReg16
MovReg8ToMemory
MovReg16ToMemory
MovMemoryToReg8
MovMemoryToReg16
MovRegToSeg
MovMemoryToSeg
MovSegToReg
MovSegToMemory
MovImmediateToReg8
MovImmediateToReg16
MovMemoryToAL
MovMemoryToAX
MovALToMemory
MovAXToMemory
MovImmediate8ToMemory
MovImmediate16ToMemory
)
接下来的几个字节就是操作数了。
- 如果是寄存器操作数,那么操作数就是寄存器的ID:
const (
AL uint8 = iota
CL
DL
BL
AH
CH
DH
BH
)
const (
AX uint8 = iota
CX
DX
BX
SP
BP
SI
DI
)
这些 ID 是和机器指令格式中的 ID 一样的,而不是随意确定的。
-
如果是立即数,那么操作数就是立即数的值。
-
如果是内存操作数,那么格式如下:
mod | rm,[偏移量]
rm 字段是 3 位,mod 字段是 2 位。实现的解码函数如下:
func decodeMemoryOperand(mod uint8, rm uint8, disp []byte) []byte {
var decoded []byte
decoded = append(decoded, mod<<3|rm)
if mod == 0b00 && rm != 0b110 {
return decoded
}
decoded = append(decoded, disp...)
return decoded
}
它的参数 mod,rm ,偏移量都是从机器指令中提取的。
解码模块的实现
要实现解码模块,首先要将机器指令分类,然后将每一种类的机器指令与解码函数关联。机器指令的第一字节包含操作码和D,W字段,我们就可以用它来做分类,区分是哪一类指令。
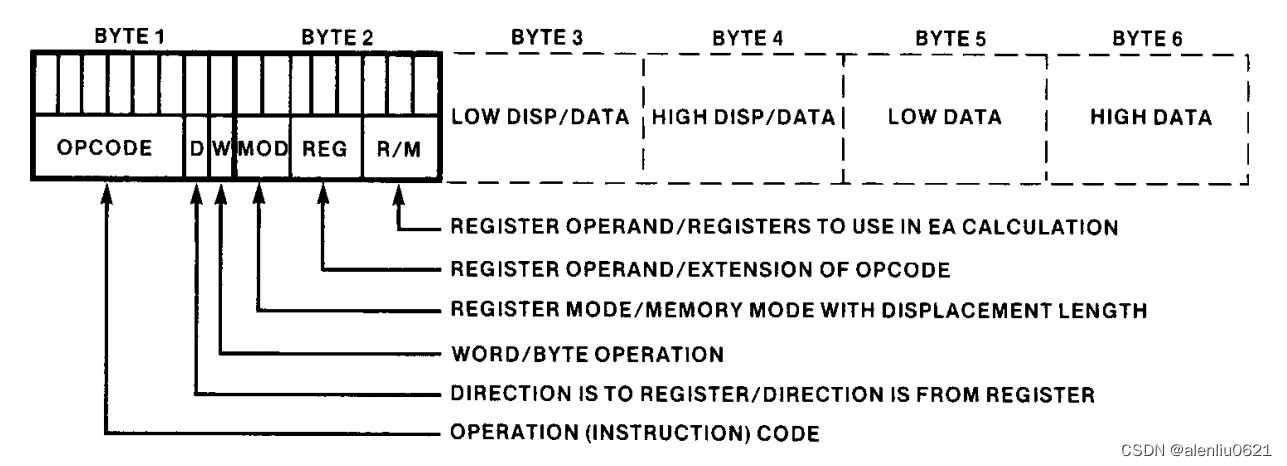
比如上文提到的 mov 指令第一字节就有 28 种不同的值,我们需要将每一种指令都与一个解码函数关联。
但是仅仅使用第一字节做分类还是不行的,因为有些指令的第一字节都是相同的,
比如:

ADD,OR,ADC,SBB,AND,SUB,XOR,CMP 这 8 个指令第一节都是 0x80,只有第二字节的 REG 字段的值不一样,所以,有时还需要根据机器指令第二字节的 REG 字段做区分。
然后需要将机器指令与解码函数关联,当识别到某种指令时,调用它的解码函数。
于是我在解码模块定义了如下的结构体和变量来表示每种机器指令对应的解码函数。
// 解码函数
type decodeFunc func([]byte) []byte
// 指令的解码结构体
type decodeInstruction struct {
InnerDecode [8]*decodeInstruction
Decode decodeFunc
}
// 所有指令的解码结构体数组
var decodeInstructions [256]*decodeInstruction
当需要添加指令【该指令可以通过第一字节区分】和它的解码函数时,就调用 AddDecodeInstruction 函数:
func AddDecodeInstruction(firstByte byte, Func decodeFunc) {
if decodeInstructions[firstByte] == nil {
decodeInstructions[firstByte] = &decodeInstruction{Decode: Func}
} else {
log.Fatalf("duplicated!!")
}
}
当需要添加只能通过第二字节区分的指令和它的解码函数时,就调用 AddDecodeInstruction2 函数:
func AddDecodeInstruction2(firstByte byte, reg byte, Func decodeFunc) {
if decodeInstructions[firstByte] == nil {
decodeInstructions[firstByte] = &decodeInstruction{}
}
d := decodeInstructions[firstByte]
if d.InnerDecode[reg] == nil {
d.InnerDecode[reg] = &decodeInstruction{Decode: Func}
} else {
log.Fatalf("duplicated 2!!")
}
}
比如,要将所有的 28 种 mov 指令和解码函数关联,我创建一个 decode_mov.go 文件,它的初始化函数如下:
func init() {
var firstByte byte
for firstByte = 0x88; firstByte <= 0x8B; firstByte++ {
AddDecodeInstruction(firstByte, decodeMovRegOrMemoryToFromReg)
}
AddDecodeInstruction(0x8C, decodeMovSegToFromRegOrMemory)
AddDecodeInstruction(0x8E, decodeMovSegToFromRegOrMemory)
for firstByte = 0xA0; firstByte <= 0xA3; firstByte++ {
AddDecodeInstruction(firstByte, decodeMovMemoryToFromAccumulator)
}
for firstByte = 0xB0; firstByte <= 0xBF; firstByte++ {
AddDecodeInstruction(firstByte, decodeMovImmediateToReg)
}
AddDecodeInstruction(0xC6, decodeMovImmediateToRegOrMemory)
AddDecodeInstruction(0xC7, decodeMovImmediateToRegOrMemory)
}
当需要新增一种指令,那就新建一个文件,调用 AddDecodeInstruction 或 AddDecodeInstruction2 函数将指令与解码函数注册到解码模块。
解码函数实现如下:
func Decode(instructions []byte) []byte {
d := decodeInstructions[instructions[0]]
if d == nil {
log.Fatalf("unsupported instruction 0x%X", instructions[0])
}
if d.Decode != nil {
return d.Decode(instructions)
}
//d.Decode 为nil,说明指令第一字节是相同的,要靠第二字节REG字段分为
if len(instructions) < 2 {
return nil
}
reg := (instructions[1] & 0b111000) >> 3
d = d.InnerDecode[reg]
if d == nil {
log.Fatalf("unsupported instruction[0] 0x%X, instruction[1] 0x%x",
instructions[0], instructions[1])
}
return d.Decode(instructions)
}
它根据机器指令的第一字节【有时加上第二字节的REG字段】调用相应的解码函数生成中间指令格式。EU 会调用它生成中间指令,然后执行。
后文讲述 mov 指令和 jmp 指令解码函数的实现。