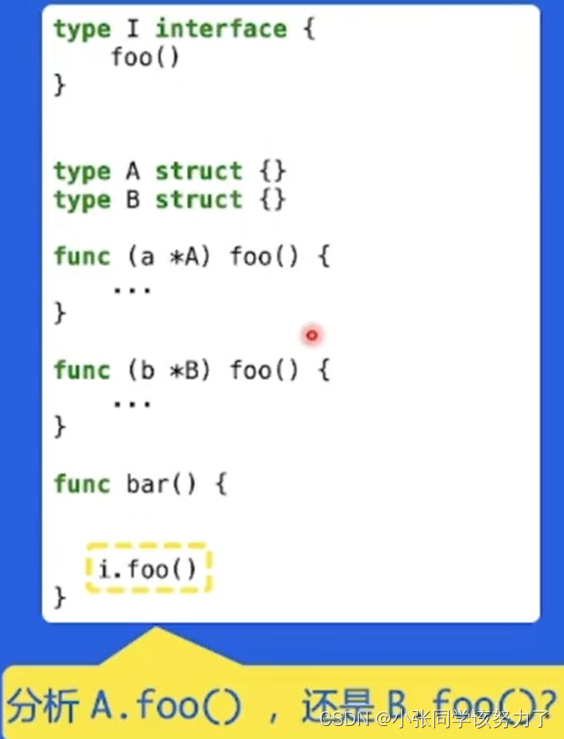
MathBERT:
耗时:2-3hours(昨天和人聊天聊完了,今天九点才到实验室,呜呜呜一早上就看了个论文)
读论文:BERT-Based Embedding Model for Formula Retrieval
Corpus Description:
resource:
from MSE;the formulas extracted from the question, answer, and comment posts
the formulas are represented in three different formats:
L
ATE
X, Presentation MathML,Content MathML format.
Each format has five distinct attributes:
formula_id, post_id,thread_id, type, formula
early system:
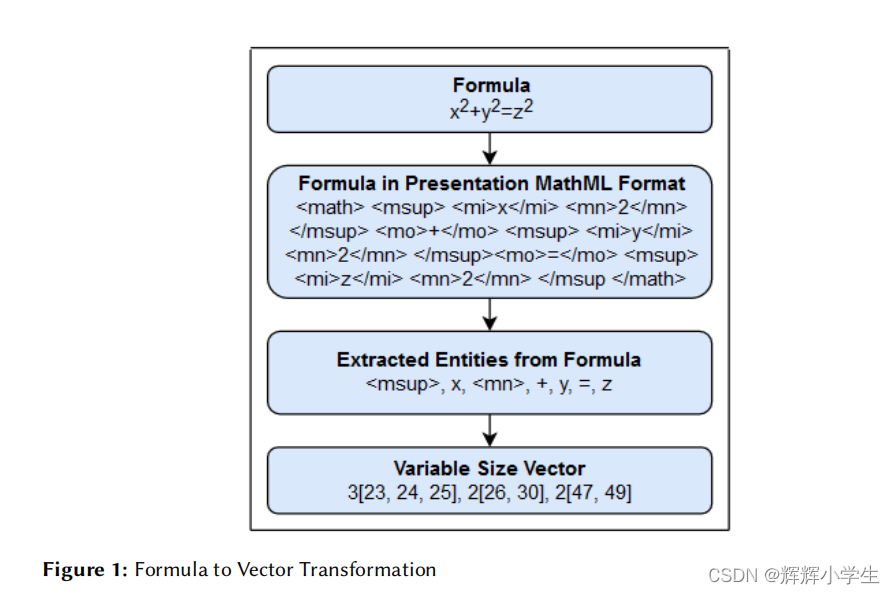
variable-size vector motivated by
Bit Position Information Table(BPIT) and Term-Document matrix
The prime objective of this system :
to transform the formula
into the variable size vector.
Each weight of the vector represents the occurrence count of a particular entity in a formula and corresponds to entity position in BPIT
.
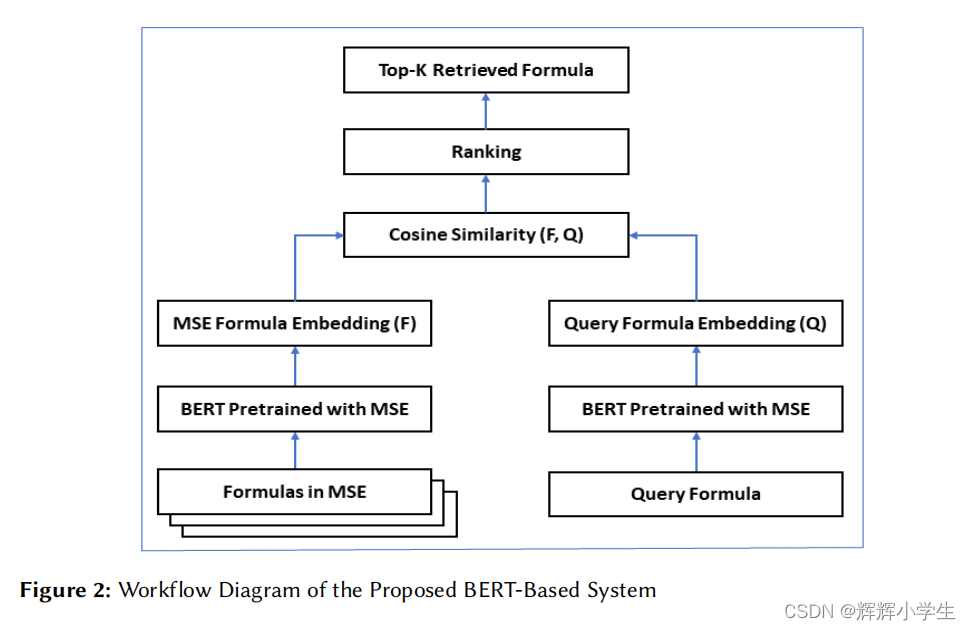
the proposed system in ARQMath2:

无语,看了半天这篇工作的预训练好像是照搬的BERT。我也是醉了...
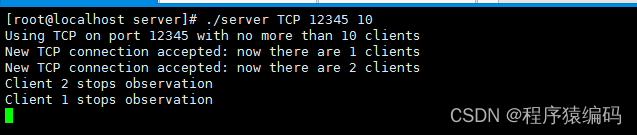
爬虫 and NER 加上 TC:
耗时:4-6hours
学会了怎么做一份粗糙的csvNER打标数据。
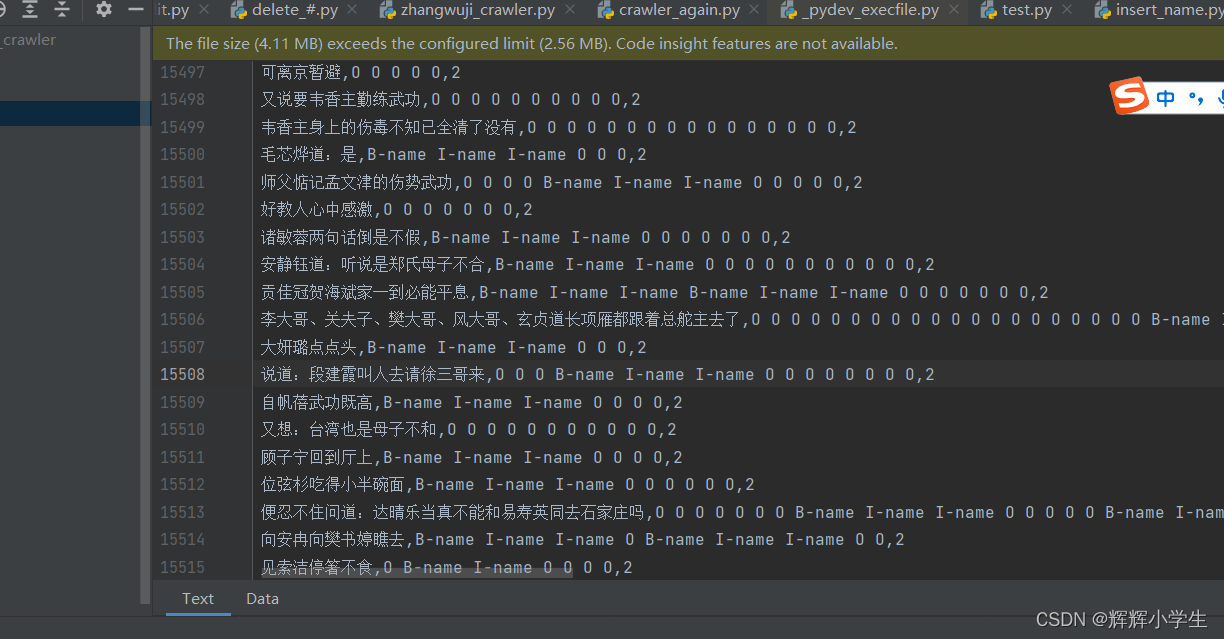
分完了数据集,构建了词表,明天写模型。
尽量一个月内学完这本鱼书:

回家看了一下深度学习的花书。