论文链接:Revisiting Distributed Synchronous SGD
ABS
本文介绍了用于分布式机器学习的同步和异步 S G D SGD SGD,同时指出各自的缺点: s t r a g g l e r s stragglers stragglers和 s t a l e n e s s staleness staleness。
同时为了解决同步
S
G
D
SGD
SGD存在
s
t
r
a
g
g
l
e
r
s
stragglers
stragglers的问题,本文提出了一种新的算法,通过back-up来加速同步
S
G
D
SGD
SGD的速度。
注:我第一次接触到
s
t
r
a
g
g
l
e
r
s
stragglers
stragglers是在MapReduce的论文中,MapReduce中也提出了back-up的解决办法,当然MapReduce中的back-up的方法不是由MapReduce提出的,而是引用了另一篇文章中的方法。当然本文的back-up与MapReduce中的有着一些不同的地方。
MapReduce的back-up引用的文章是:Arash Baratloo, Mehmet Karaul, Zvi Kedem, and Peter Wyckoff. Charlotte: Metacomputing on the web. In Proceedings of the 9th International Conference on Parallel and Distributed Computing Systems, 1996
1 INTRO
异步 S G D SGD SGD解决分布式机器学习中的通信速率的问题的同时引入了新的问题:过期的梯度。
过期的梯度对模型的收敛速度以及收敛精度都有着不小的影响。
而如果使用同步 S G D SGD SGD有存在 s t r a g g l e r s stragglers stragglers(完成时间远远低于其他结点的节点)的问题。
本文采用同步 S G D SGD SGD但是引入了 b a c k − u p back-up back−up机制,能够一定程度的环节 s t r a g g l e r s stragglers stragglers的情况,本文的主要贡献如下:
- 阐明了异步 S G D SGD SGD中过期的梯度对测试精度的负面影响;
- 阐明了通过 S G D SGD SGD中 s t r a g g l e r s stragglers stragglers对训练时间的影响;
- 提出带有 b a c k − u p back-up back−up机制的同步 S G D SGD SGD;
- 做了实验来验证新方法的收敛速度以及收敛精确度;
- 通过实验证明新方法比异步 S G D SGD SGD更加优秀(不论是收敛速度还是收敛精度)
1.1 Preliminaries and Notation
通常我们的训练需要让损失函数最小。
而我们可以通过梯度下降的方法来求出一个局部的最优解。
当将机器学习通过分布式来实现的时候,所需要做的事情是类似的,只是我们需要定期的从各个节点收集数据进行一次数据的汇总再将新的数据分发给各个节点进行新的训练。正是有了数据收集和分发的过程,才产生了两种不同算法同步 S G D SGD SGD和异步 S G D SGD SGD。
2 Asynchronous Stochastic Optimization
异步 S G D SGD SGD的算法如下所示:

需要注意的是,虽然叫做异步算法,但是上述的过程还是存在一些同步机制,例如工作结点在从参数服务器读取参数的时候,必须要保证读取到的参数比上一轮读取到参数新(如果不这样,那么工作结点就会做多余的计算,当然这往往是必然的,因为在自己进行下一轮的读取的时候,自己本轮的参数应该会上传到服务器进行更新),也就是说在读取参数的时候不需要所有的工作结点都完成自己本轮的工作再上传参数,这也就是异步的意思。
这样做能够充分的利用资源,但是也同样存在问题,在一个工作结点进行计算的过程中 A l g o r i t h m 1 l i n e 3 − 7 Algorithm\ 1\ line 3 -7 Algorithm 1 line3−7时,其他的工作结点可能完成了某一轮的计算,将参数上传到服务器进行更新,这也就代表正在进行工作的工作结点的参数过时了,也就是出现了 s t a l e n e s s staleness staleness。
后续的实验会说明过时梯度对最终的影响有多大。
T
a
b
l
e
1
Table\ 1
Table 1展示了ImageNet上使用Inception模型进行训练,工作结点个数为
40
40
40的异步
S
G
D
SGD
SGD在各层出现梯度过期情况。

虽然异步 S G D SGD SGD存在过期梯度的问题,但是在工作结点的个数比较少的情况下,异步 S G D SGD SGD的效果还是不错的,但是当工作结点的个数增加时,异步 S G D SGD SGD就变得力不从心了。
2.1 Impact of Staleness on Test Accuracy
实验的细节可以在原文的附录中找到。
F i g u r e 2 Figure\ 2 Figure 2展示了平均过期梯度数量与测试精度的关系。

从 F i g u r e 2 Figure\ 2 Figure 2可以看出当梯度过期出现的次数越多的时候,整体的错误率会有着明显上升,特别是从 100 100 100到 120 120 120这一段。
事实上当梯度过期的平均值达到 15 15 15的时候就已经出现错误率剧烈上升了,为了能够做更大数值的梯度过期,作者使用了一些技巧:
- 前三个 e p o c h s epochs epochs过期的数量增长较慢;
- 当梯度过期的数量过大时候,降低学习率;
- 如果上述两点依然会导致非常大的错误率,那么就多次进行实验,取最好的结果。
3 Revisiting Synchronous Stochastic Optimization
过去提出了同步 S G D SGD SGD该方法解决了异步 S G D SGD SGD中过期梯度的问题,但是同时又引入了新的问题,现在每一次同步的时间,取决于服务器最后收到的参数的时间(通常是完成本轮本地计算最慢的工作结点,也就是 s t r a g g l e r s stragglers stragglers)。
s t r a g g l e r s stragglers stragglers的出现是很常见的,在规模越大的分布式集群中收到 s t r a g g l e r s stragglers stragglers的影响就会越大,而出现本地计算变慢的原因也是多种多样的:例如硬件出现故障,其他进程占用资源等等。
为了解决
s
t
r
a
g
g
l
e
r
s
stragglers
stragglers的问题,作者提出了back-up的方法,作者将参与训练的工作结点划分为两部分:
N
N
N个正常工作者和
b
b
b个备用工作者。
这 N + b N+b N+b个结点依然执行不同的数据上的计算,当服务器收到任意 N N N个结点的参数之后,服务器就可以进行本轮的参数聚合。
注意,上述的过程中 N N N和 b b b仅仅只是两个参数,在算法的过程中并没有实实在在地标注那个结点属于正常工作者还是备用工作者,而是类似于自动分配的,通常(网络不出现卡顿)情况下,先完成本地计算的 N N N个结点会成为正常工作者,剩下的 b b b个结点此时就是备用工作者,也可以看做是 b b b个 s t r a g g l e r s stragglers stragglers,每一轮更新的备用工作者可能会发生变化。
A l g o r i t h m 3 , 4 Algorithm 3, 4 Algorithm3,4分别描述了工作结点的执行步骤和参数服务器执行的步骤:

工作结点开始之前先从参数服务器读取本轮的参数(如果本轮的参数还没准备好,那么此时会阻塞),之后工作结点计算自己本地的梯度,计算完成后将梯度发送给服务器。可以看到工作结点的步骤与传统的同步 S G D SGD SGD没有任何区别,而不同的地方出现在参数服务器。
参数服务器会收集本轮工作结点梯度信息(梯度信息带有时间戳,会丢弃之前的梯度,因为可能在进行新的一轮的时候,之前的 s t r a g g l e r s stragglers stragglers才完成),当收集到 N N N个梯度信息的时候就进行参数的聚合,之后就可以将参数发送给工作结点进行新的一轮计算。
上面算法中的 θ ‾ \overline {\theta} θ是用于性能估计的。
说明:个人认为上面的算法存在一个问题。从我的理解来看,当一个工作结点在某一轮成为了 s t r a g g l e r straggler straggler之后,那么其他正常工作结点再开始下一轮计算的时候,该结点可能还没有完成本轮的计算,如果正常工作结点没有出现“卡顿”的情况,那么该工作结点在下一轮依然有很大的可能再一次成为掉队者,这样下去就会一直出现恶性循环, s t r a g g l e r s stragglers stragglers会更有可能成为 s t r a g g l e r s stragglers stragglers。这就相当于这些 s t r a g g l e r s stragglers stragglers的数据完全没有参与到更新,这等价于在一开始训练的时候我们人工的丢弃一些固定的数据,这样并不能很好的利用数据。关于这个问题,我认为至少有两种可以解决的方法:
- 根据 k k k折交叉验证的想法,我想到了一个改进的想法,每一次参数服务器完成本轮更新后,应该向所有的工作结点发送信息(这条信息的数据量非常小,所以不会称为瓶颈),当收到这条信息的时候,还没有完成本轮本地计算结点应该停止本轮计算(因为参数已经进行更新了,再计算也没有意义了),然后直接开始下一轮的读取参数操作,这样当前的 s t r a g g l e r s stragglers stragglers在下一轮的时候才有公平竞争的机会,因为这些 s t r a g g l e r s stragglers stragglers的性能可能在下一轮的时候恢复,这个时候新的 s t r a g g l e r s stragglers stragglers就很有可能是其他出现性能下降的结点,这样每轮丢弃的数据具有随机性,很类似于 k k k折交叉验证。
- 除了上面的方法,服务器参数还可以在收到之前的梯度的时候不进行丢弃,而是将该部分的梯度也对参数进行修改,但是并不增加本轮收到的梯度个数,这样做的目的就相当于是延迟修改,这似乎比直接丢弃掉要好一些。但是延迟丢弃可能会对整体造成不好的影响,这个就需要具体进行实验分析了,或者设计更加合理的延迟更新操作。
3.1 Straggler Effects
这一部分的实验是展示 s t r a g g l e r s stragglers stragglers的负面影响,实验的细节可以在原文的附录找到。
F i g u r e 3 Figure\ 3 Figure 3展示了某个模型上等待不同个数的结点完成本地计算需要的时间(一共有 100 100 100个工作结点), F i g u r e 4 Figure\ 4 Figure 4代表的是等待 k k k个结点完成本地计算所需要的平均数(Mean)和中位数(Median):

F i g u r e 3 Figure\ 3 Figure 3的纵轴代表的是整个迭代过程的占比,横轴代表所需要的时间, k k k代表等待 k k k个结点完成本地计算。
从上图中我们可以看到的是,如果要等待 100 100 100个工作结点都完成本轮的计算,需要的时间比等待的 90 90 90个结点的时候增加了很多,而且图片的说明还指出:最大的一次等待时间达到了 310 s 310s 310s。这表明 s t r a g g l e r s stragglers stragglers的影响是非常大的,同时上面的图片也说明 s t r a g g l e r straggler straggler的占比是非常低的。
为了确定 N , b N,b N,b的取值,作者做了实验 F i g u r e 5 Figure\ 5 Figure 5是不同的 N N N收敛所需要的迭代次数( N + b = 100 N+b=100 N+b=100),可以看到 N = 100 , b = 0 N=100, b = 0 N=100,b=0的时候所需要的迭代次数最少。不过需要注意的时候迭代次数少时间并不一定短,如果 N = 100 N=100 N=100那么需要等待所有的工作结点完成计算,那么由上一个实验可以看到这样的时间会非常长,于是作者作者用 F i g u r e 6 Figure\ 6 Figure 6来展示时间与 N N N的关系。

可以看到 N = 96 , b = 4 N=96,b=4 N=96,b=4的时候收敛所花费的时间最少。
注意:并不是 N = 1 , 2 , 3 , . . . , 100 N=1, 2, 3, ..., 100 N=1,2,3,...,100的实验均做了,作者只做了部分的实验,其余的地方的是通过线性插值计算得来。
4 Experiments
更多的实验细节可以原文的附录中找到,这里只介绍一些重要的结果。
4.1 Metrics of Comparison: Faster Convergence, Better Optimum
评价的指标有两个:收敛速度和准确率。
做了关于不同学习率的实验,学习率初始化后会随着训练的进行进行指数级别的衰减。
Table 2展示了不同的初始学习率下的收敛速率以及收敛后的准确。

Figure 7的左边展示了不同学习率初始值的测试集精度随着迭代次数的变化,右边则展示了不同学习率到达某个精度所需要的迭代次数。

从上面的实验结果可以看出来,较大的学习率具有较慢的收敛速度,但是收敛速度变慢的情况下,精确度相对也有所提高。有时候较小的学习率也有可能既不能获得更高的准确度,也不能获取更快地收敛。
4.2 Inception
Inception是一个2016年提出的一个训练模型,本部分的实验数据集是ImageNet,更多该实验的细节可以在原文的附录部分找到。

Figure 8展示了这一部分的实验结果:
- (a)图展示了不同工作结点个数下各算法的测试准确度与迭代次数的变换关系。
- (b)图展示了不同工作结点个数下各算法最终收敛的测试精度。
- ©图展示了不同工作结点个数下各算法收敛所需要的迭代次数。
- (d)图展示了不同工作结点个数下各算法收敛所需要的时间。
- (e)图展示了不同工作结点个数下各算法每一次迭代的平均时间。
从上面的结果可以看出本文提出的算法收敛的更快,准确度更加高。
4.3 Pixel CNN Experiments
Pixel CNN是2016年提出的一个模型,数据集是CIFAR-10。
实验结果如Figure 9所示:
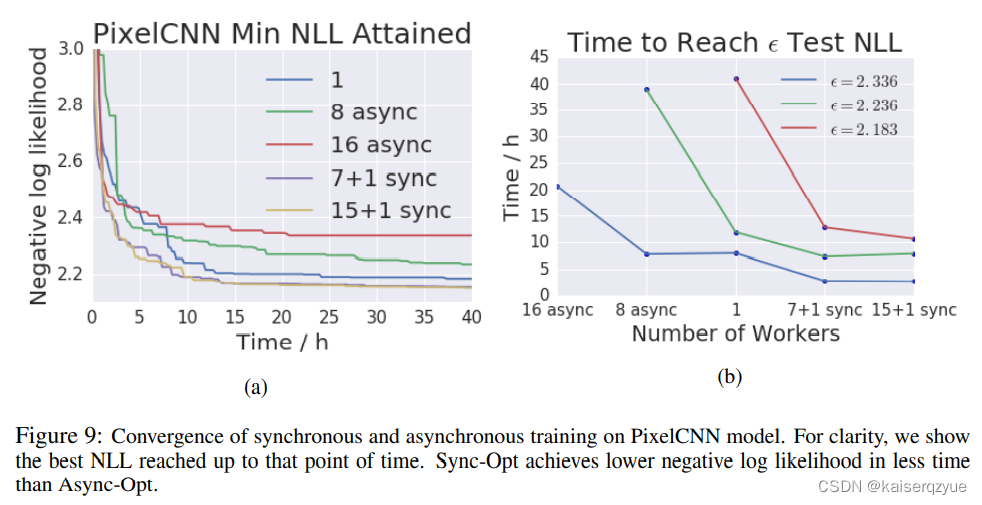
左图展示的是NLL和训练时间的变化(NLL越小效果越好),右图则是达到某个NLL值所需要的时间。
值得指出的异步的 S G D SGD SGD的效果不如串行的 R M S P r o RMSPro RMSPro,这也表明过期的梯度对训练结果有着较大的影响。
5 Related Work
这一部分介绍了一些相关工作,个人认为其中有两篇很有参考意义,后续会做这两篇论文的精读:
软同步:Staleness-Aware Async-SGD for distributed deep learning,在进行异步 S G D SGD SGD先进行一部分的本地聚合。
不需要参数服务器进行分布式机器学习:Ako: Decentralised deep learning with partial gradient exchange使用轮转的方式来实现参数的聚合。
6 Conclusion and Future Work
随着数据集的以及模型的增大,分布式机器学习会变得越来越重要。
本文介绍了同步 S G D SGD SGD和异步 S G D SGD SGD各自的缺点,并且提出了一定程度上解决同步 S G D SGD SGD缺点的新方法。
未来可以将能够共享的工作结点先进行本地的聚合,再在服务器进行参数聚合。亦或是可以将back-up机制更改为超时机制,这也意味着每轮参与参数聚合的结点个数将不再固定。