文章目录
- 进程程序替换
- 替换原理
- 替换函数
- 函数返回值
- 函数命名理解
- 在makefile文件中一次生成两个可执行文件
- 总结:
- 程序替换时运行其它语言程序
进程程序替换
程序要运行要先加载到内存当中 , 如何做到? 加载器加载进来,然后程序替换
为什么? ->冯诺依曼 因为CPU读取数据的时候只能和内存打交道 CPU执行程序的时候离内存最近.CPU要从内存拿数据和代码,前提条件是外设当中的可执行程序加载到内存中
替换原理
用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支), 那如果我们想让子进程执行一个“全新”的程序要怎么做呢? 我们就需要通过程序替换实现
子进程往往要调用一种exec*函数以执行另一个程序
- 当进程调用一种exec*函数时**,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行**
- 调用exec并不创建新进程,所以调用exec前后该进程的id并未改变
什么叫做进程程序替换?
进程不变,仅仅替换当前进程的代码和数据的技术,并没有创建新的进程(所以进程的id没有改变) 叫做进程程序替换
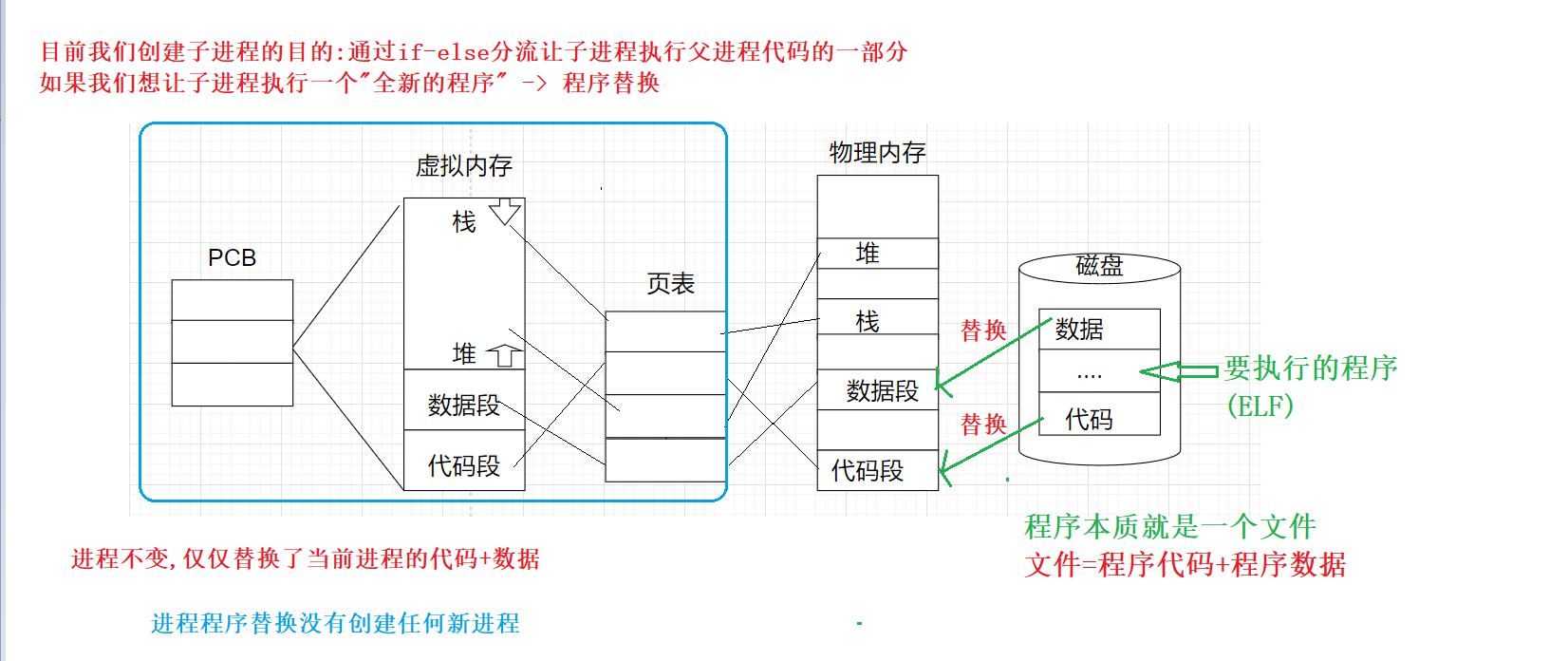
老程序的壳子不变,把新程序的代码和数据替换进去, 进程替换是把磁盘上的程序加载到内存中
进程程序替换时有没有创建新的进程?
进程程序替换之后,该进程对应的PCB.进程地址空间以及页表等数据结构都没有发生改变,只是进程在物理内存当中的数据和代码发生了改变,所以并没有创建新的进程,而且进程程序替换前后该进程的pid并没有改变
程序替换的本质是什么?
本质是把程序的代码+数据加载到特定进程的上下文中, C/C++程序要运行,必须要先加载到内存中
程序运行是如何加载到内存中的呢?
通过加载器,加载器的底层原理就是一系列的exec*程序替换函数
直接打开和程序替换打开有什么区别?
直接打开是要形成新的进程,而进程替换不形成新进程, ->没有PCB的创建,先有的进程然后才能执行程序替换
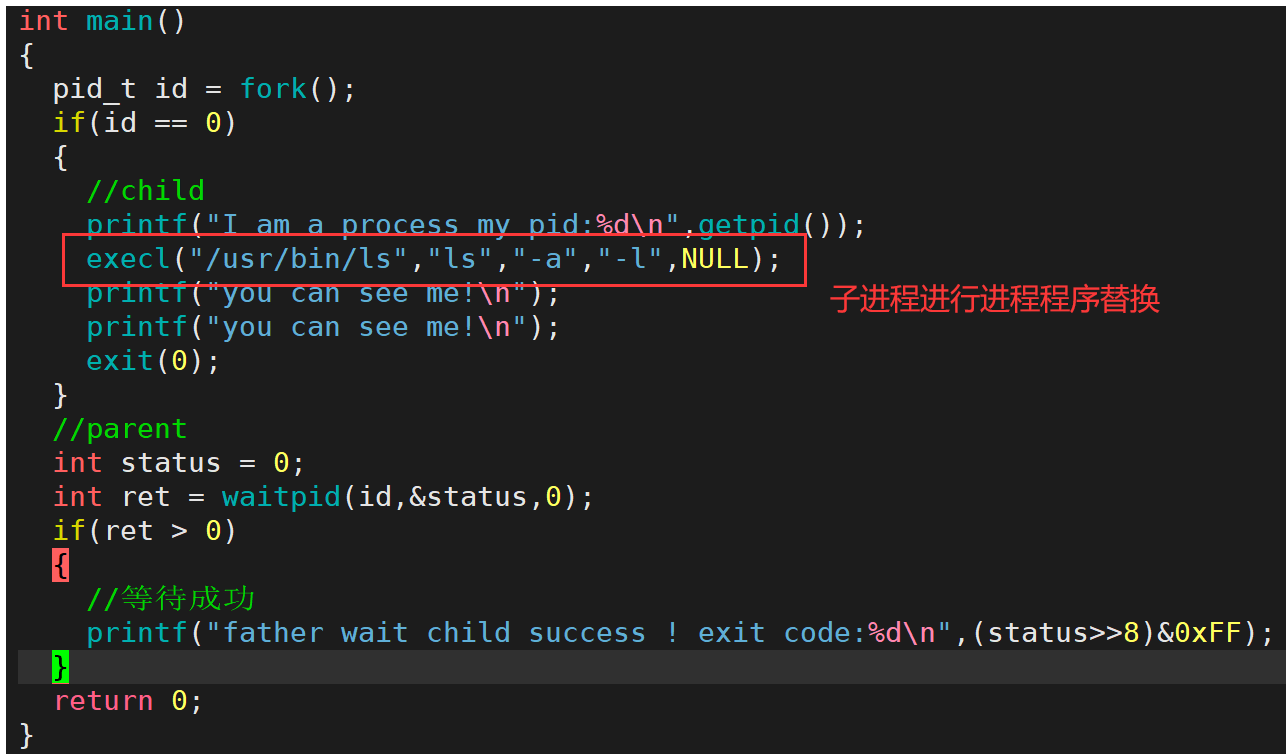
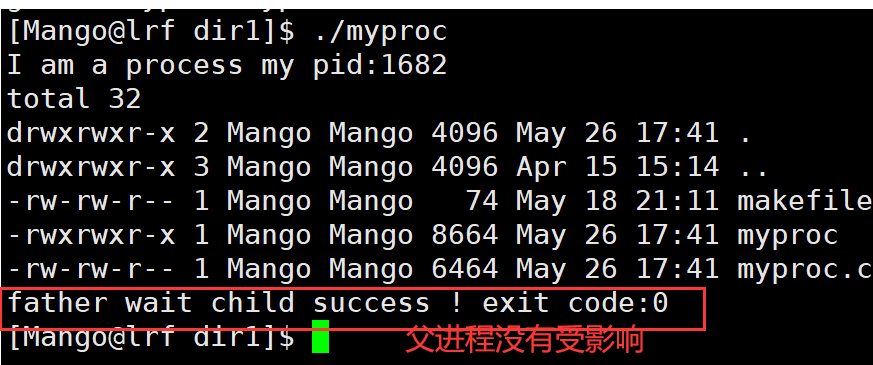
我们fork子进程,然后让子进程进行程序替换,会影响父进程吗? 父子代码是共享的吗?
父进程不会受影响,因为进程是具有独立性的!没有修改数据的时候,父子共享代码,修改就会发生写时拷贝 进程替换会更改代码区的代码,要发生写时拷贝,这样就可以让子进程执行全新的程序
子进程刚被创建时,与父进程共享代码和数据,但当子进程需要进行进程程序替换时,也就意味着子进程需要对其数据和代码进行写入操作,这时便需要将父子进程共享的代码和数据进行写时拷贝,此后父子进程的代码和数据也就分离了,因此子进程进行程序替换后不会影响父进程的代码和数据
替换函数
其实有六种以ex为ec开头的函数,统称exec函数
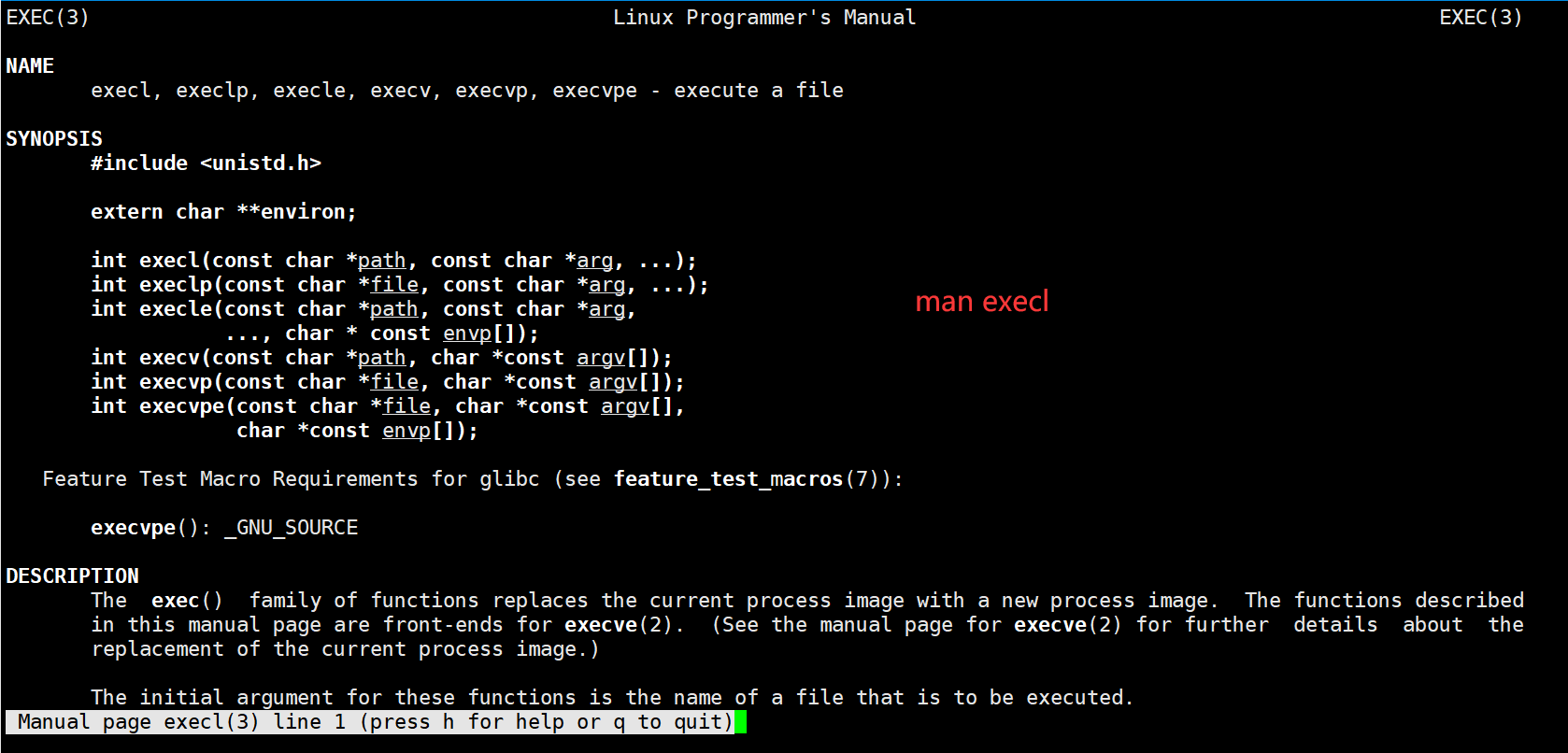
#include <unistd.h>`
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
函数返回值
- 这些函数如果调用成功 则加载新的程序从启动代码开始执行,不再返回.
- 如果调用出错则返回-1
- 所以exec函数只有出错的返回值而没有成功的返回值, exec系列的函数,只要返回了,就一定是调用失败
关于exec*系列函数的返回值:
只要进程的程序替换成功,就不会执行后序的代码, 所以,exec*函数成功是不需要进行返回值检测,只要返回了,就一定是因为调用失败了,直接退出程序就好
调用失败的例子:
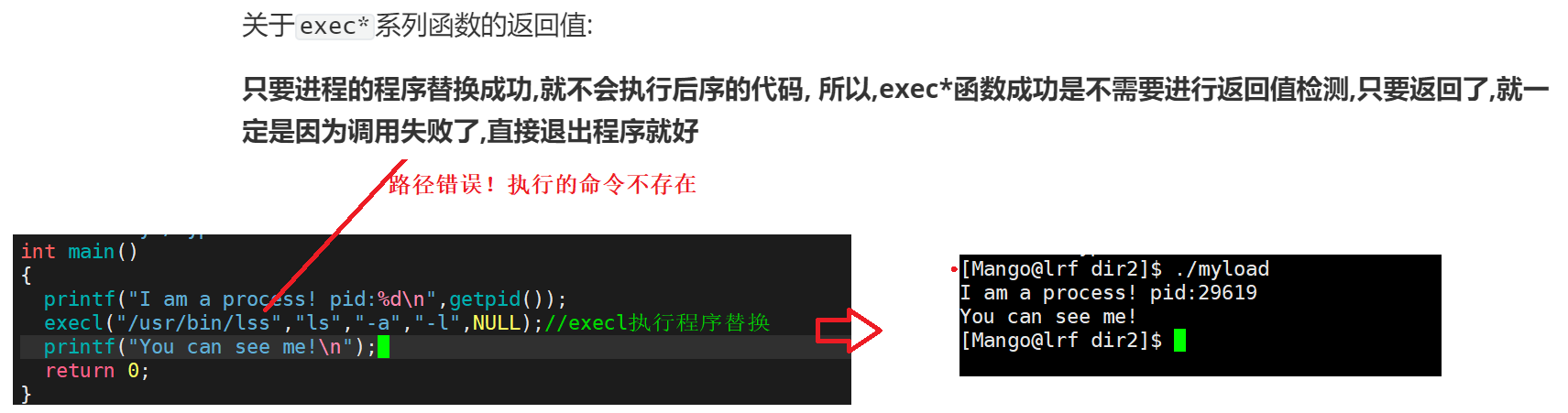
如何证明它是调用失败呢?

函数命名理解
上述函数名看起来很容易混乱,我们理解他们的命名含义就好记了
| 替换函数接口后后缀 | 含义 |
|---|---|
| l(list) | 参数采用列表方式 |
| v(vector) | 参数采用数组方式 |
| p(path) | 自动搜索环境变量PATH,进行程序查找 |
| e(env) | 自己维护环境变量,或者说自定义环境变量,可以传入自己设置的环境变量 |
| 函数名 | 参数格式 | 是否带路径 | 是否使用当前环境变量 |
|---|---|---|---|
| execl | 列表 | 否 | 是 |
| execlp | 列表 | 是 | 是 |
| execle | 列表 | 否 | 否,需自己组装环境变量 |
| execv | 数组 | 否 | 是 |
| execvp | 数组 | 是 | 是 |
| execve | 数组 | 否 | 否,需自己组装环境变量 |
事实上,只有execve才是真正的系统调用,其它五个函数最终都是调用的execve,所以execve在man手册的第2节,而其它五个函数在man手册的第3节,也就是说其他五个函数实际上是对系统调用execve进行了封装,以满足不同用户的不同调用场景的
- 手册3:代表库函数 手册2:代表系统调用
用一张图描述exec系列函数之间的关系:
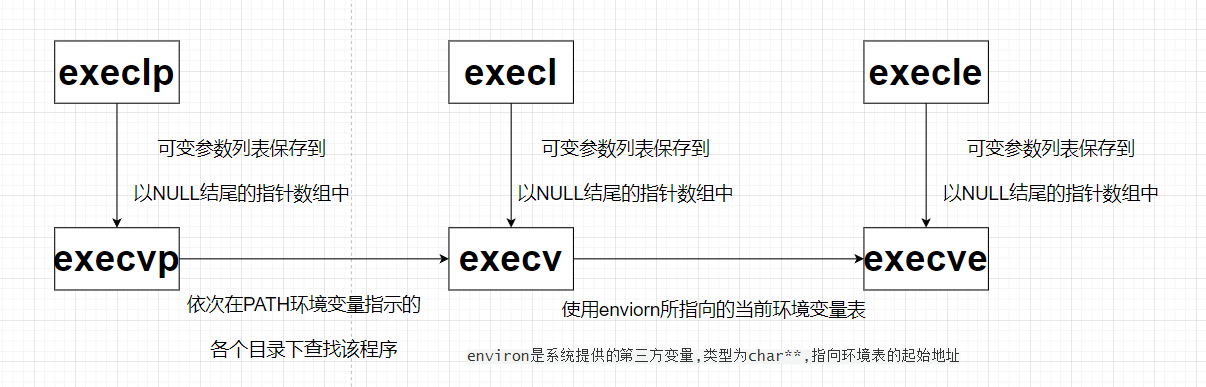
execl
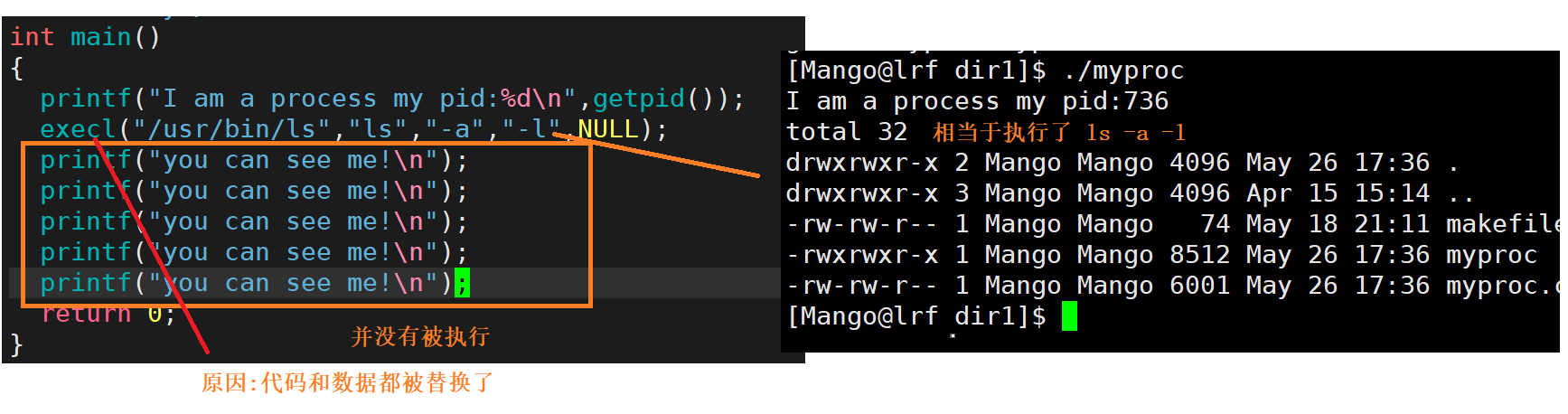
int execl(const char *path, const char *arg, ...)
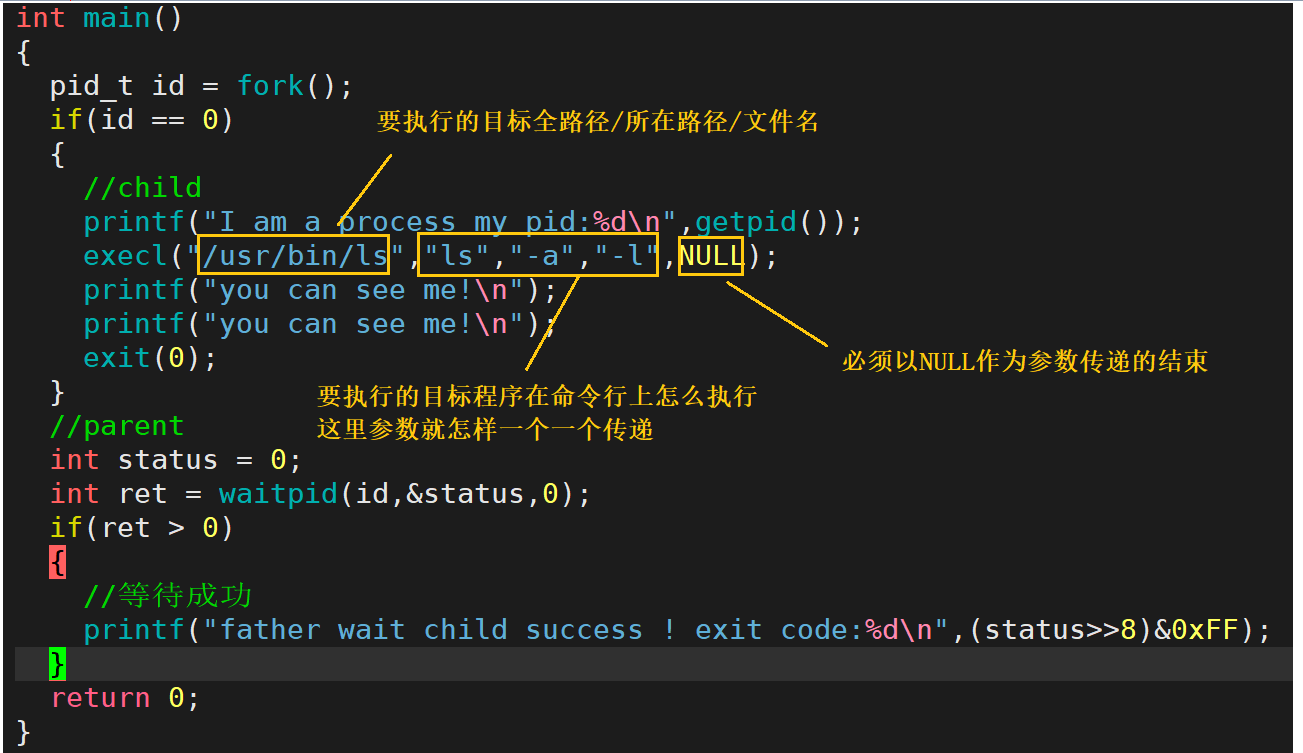
第一个参数是要执行程序的路径,第二个后面的是可变参数列表,表示你要如何执行这个程序, 注意以NULL为参数传递的结尾
后缀为l:即参数用列表传递
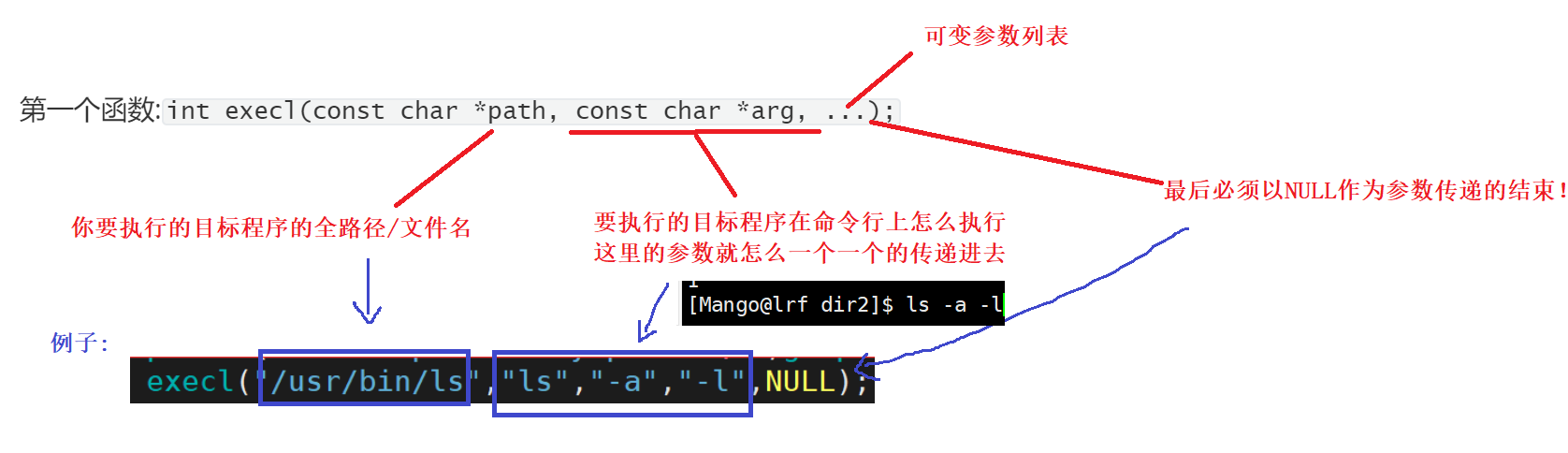
例子:
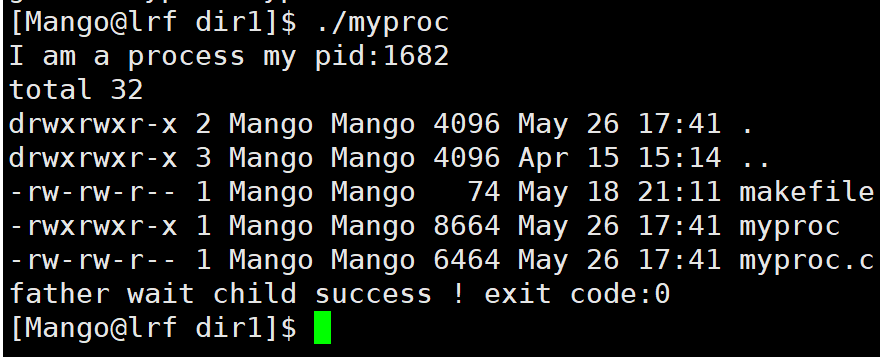
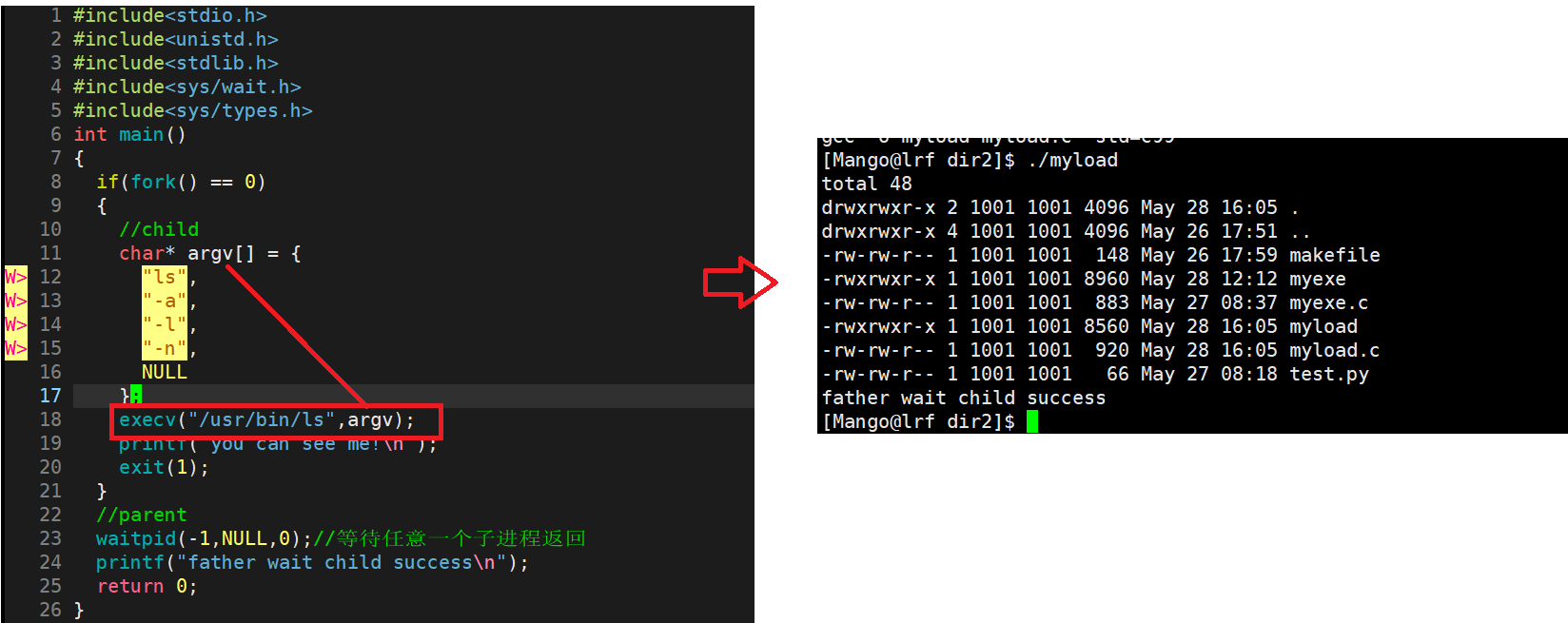
execl("/usr/bin/ls","ls","-a","-l",NULL);//相当于执行ls -a -l
执行结果:
execv
int execv(const char *path, char *const argv[])
第一个参数是要执行程序的路径,第二个参数是一个指针数组,数组当中的内容表示你要如何执行这个程序,数组以NULL结尾
后缀为v:即参数用数组传递
//例子
char* argv[] = {"ls","-a","-l",NULL};
execv("/usr/bin/ls",argv);//相当于执行ls -a -l
使用例子:
main函数是可以携带参数的,argv是一个指针数组,指针指向命令行参数字符串,我们可以理解为:通过exec函数,把argv给了ls程序
execlp && execvp
后缀为p:表示会自动在环境变量PATH中搜索,只需要直到程序名即可
**int execlp(const char file, const char arg, …)
第一个参数是要执行程序的名字(只需要写名称,不需要带路径,会自动找),第二个参数是可变参数列表,表示你要如何执行这个程序,并以NULL结尾
//例子:
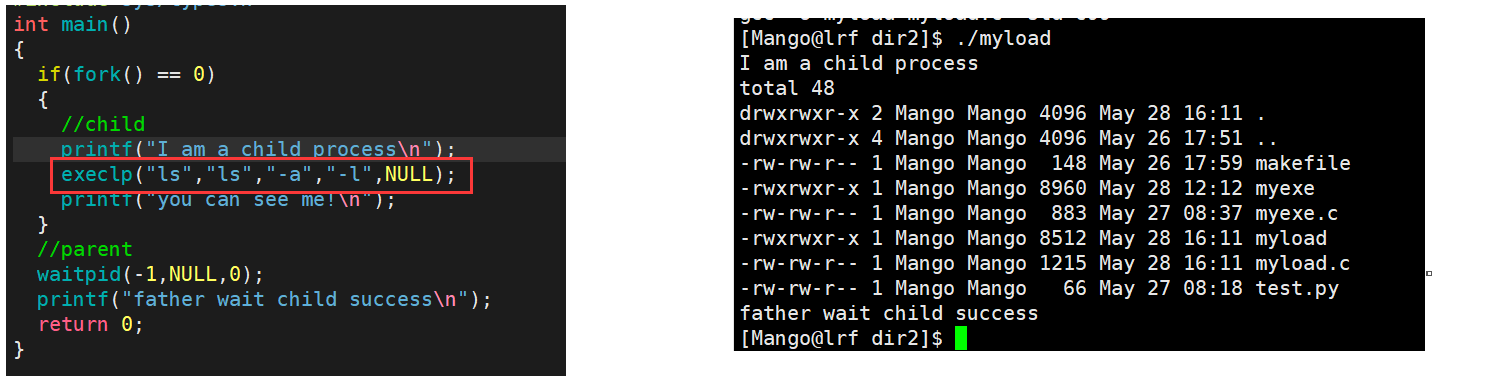
execlp("ls","ls","-a","-l",NULL); //相当于执行ls -a -l
//第一个ls表示你要执行谁,execlp会自动在环境变量PATH中根据这个程序名搜索这个程序在什么位置
//后面的ls表示我们要如何执行它
例子:
**int execvp(const char file, char const argv[])
第一个参数是要执行程序的名字,第二个参数是一个指针数组,数组当中的内容表示你要如何执行这个程序,数组以NULL结尾
//例子
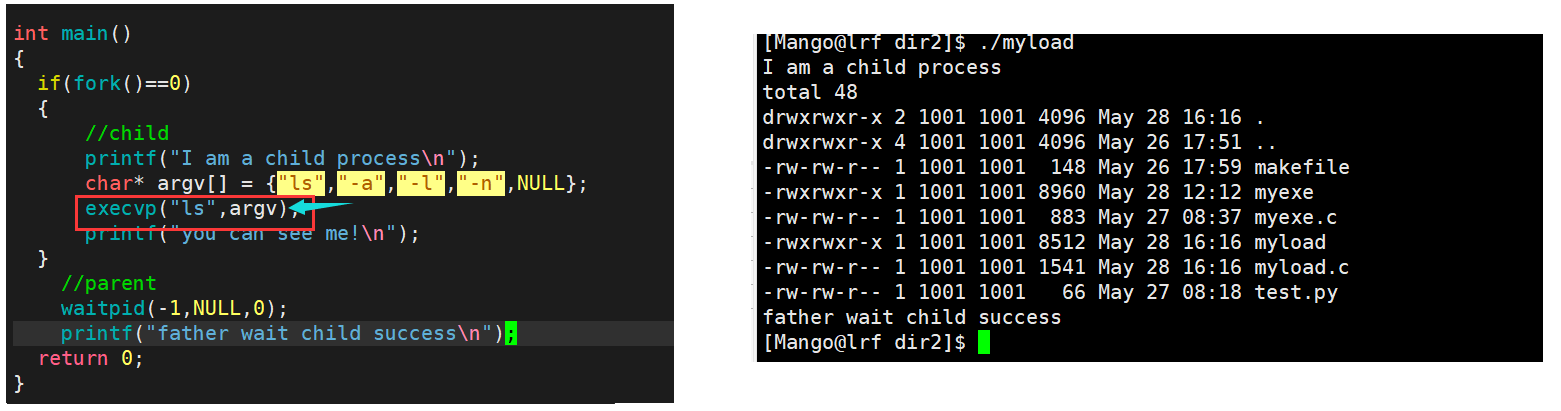
char* argv[] = {"ls","-a","-l",NULL};
execvp("ls",argv);//相当于执行ls -a -l
例子:
execle && execve
后缀为e:表示会自己维护环境变量,用自己设置的环境变量
**int execle(const char *path, const char arg, …,char const envp[])
第一个参数是要执行程序的路径,第二个参数是可变参数列表,表示你要如何执行这个程序,并以NULL结尾,第三个参数是你自己设置的环境变量
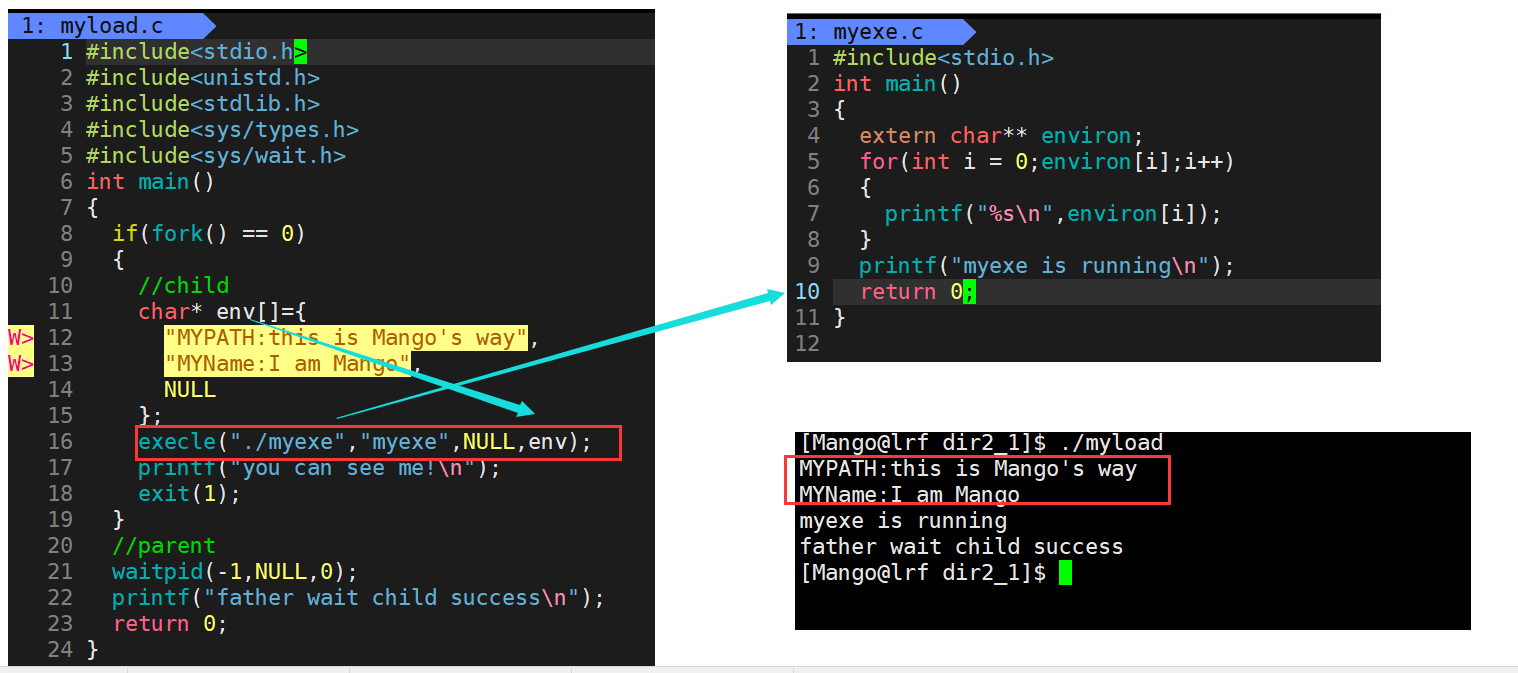
//例如有两个文件:myload 和myexe,如果我们在myload中设置了环境变量,在myexe文件就可以使用该环境变量
//myload:
char* env[] = {"MYPATH:hello world",NULL};
execle("./myexe","myexe",NULL,env) //注意这里先传NULL结尾 再传env
// 因为要执行程序所在的位置已经找到了,所以第二个参数可以写成:./myexe 也可以直接写成myexe
//myexe
可以使用myload文件中的环境变量MYPATH
如果我们直接执行myexe: 默认使用的是系统的环境变量
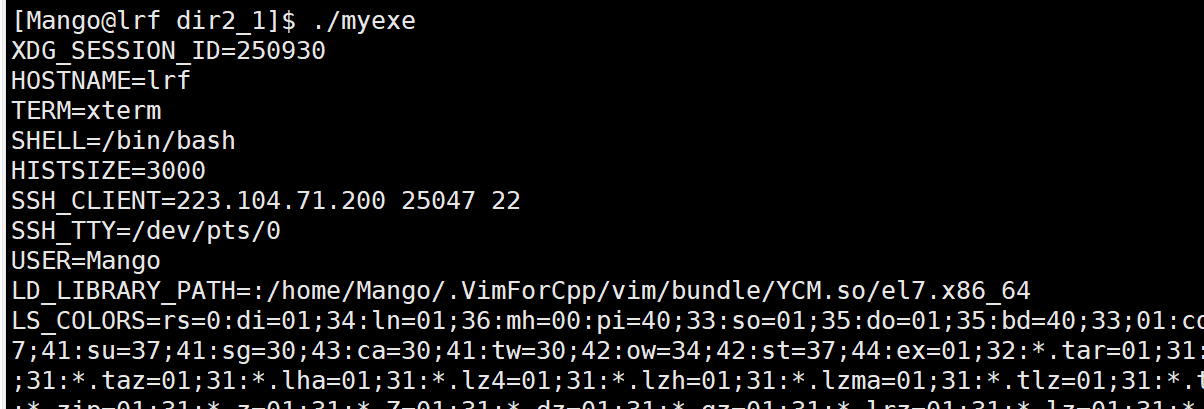
我们运行myload去运行myexe,执行的就是我们导入的环境变量
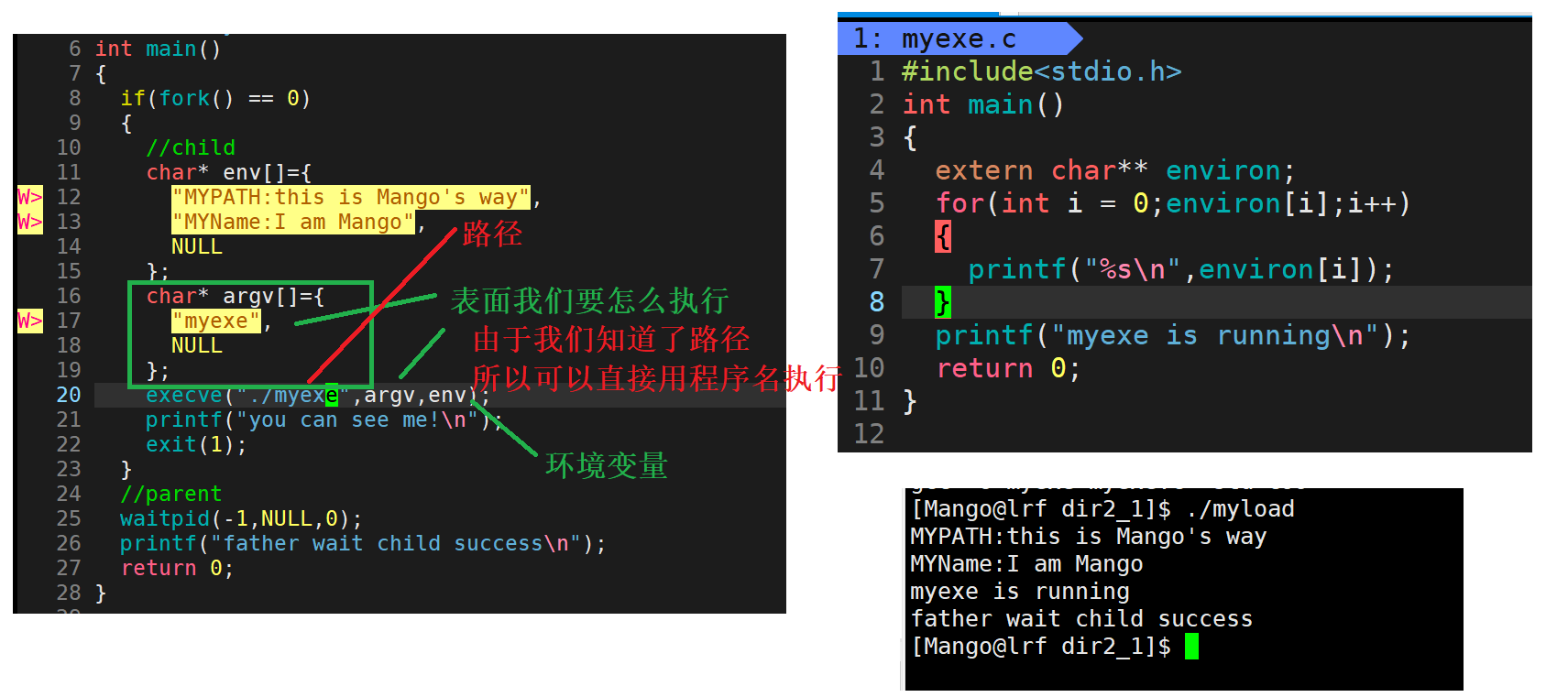
**int execve(const char *path, char const argv[], char const envp[])
第一个参数是要执行程序的路径,第二个参数传你要怎么执行的,是一个指针数组,数组当中的内容表示你要如何执行这个程序,数组以NULL结尾,第三个参数是你自己设置的环境变量
//例如有两个文件:myload 和myexe,如果我们在myload中设置了环境变量,在myexe文件就可以使用该环境变量
//myload:
char* env[] = {"MYPATH:hello world",NULL};
char* argv[]={"myexe",NULL};
execve("./myexe",argv,env);
//myexe
可以使用myload文件中的环境变量MYPATH,MYVAL
 exec*也可也调用我们自己的程序
exec*也可也调用我们自己的程序
在makefile文件中一次生成两个可执行文件
makefile默认会形成在依赖关系当中形成第一个它所碰到的依赖文件 (makefile默认会形成第一个碰到的目标文件)
那么如何在一个makefile文件中一次形成两个可执行文件呢?
.PHONY:all
all:myload myexe
myload:myload.c
gcc -0 $@ $^ -std=c99
myexe:myexe.c
gcc -0 $@ $^ -std=c99
.PHONY:clear
clear:
rm -f myload myexe
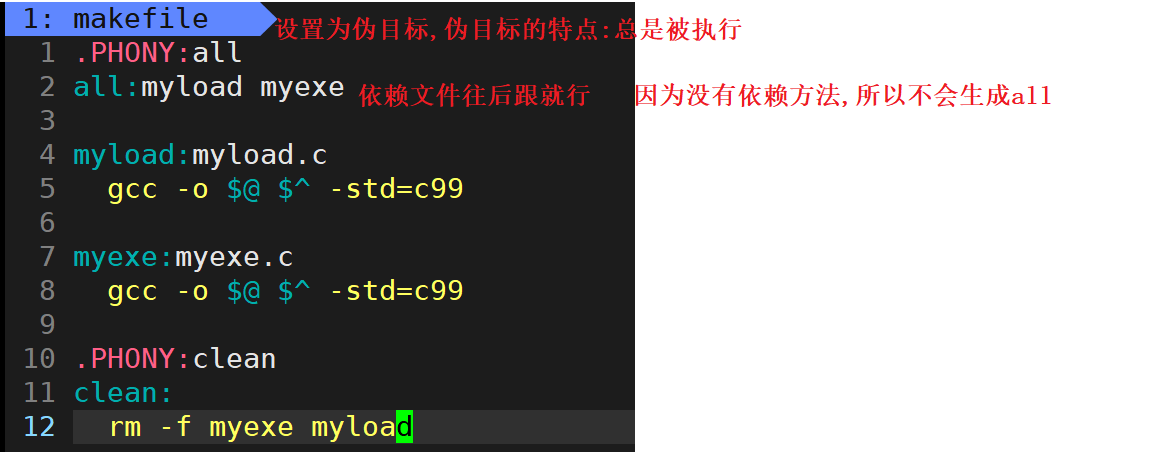
解析:利用伪目标总是被执行的特点, all依赖的是myexe和myload, 因为all 没有依赖方法,所以不会生成all. 但是因为有依赖文件,所以makefile在执行的时候,一定想先形成的是all,形成all就得先形成myexe和myload. 所以会分别执行myexe和myload的gcc代码 而因为all没有依赖方法,所以形成myexe和myload之后,并不会再形成all
如何我们想形成5个呢?
只需要把依赖文件往all后面不断去添加, all : my1 my2 my3 然后后面再给依赖关系和依赖方法
总结:
所以的接口,看起来没有太大的差别,只有一个就是参数的不同,为什么会有这么多接口?是为了满足不同的应用场景
程序替换时运行其它语言程序
例子:
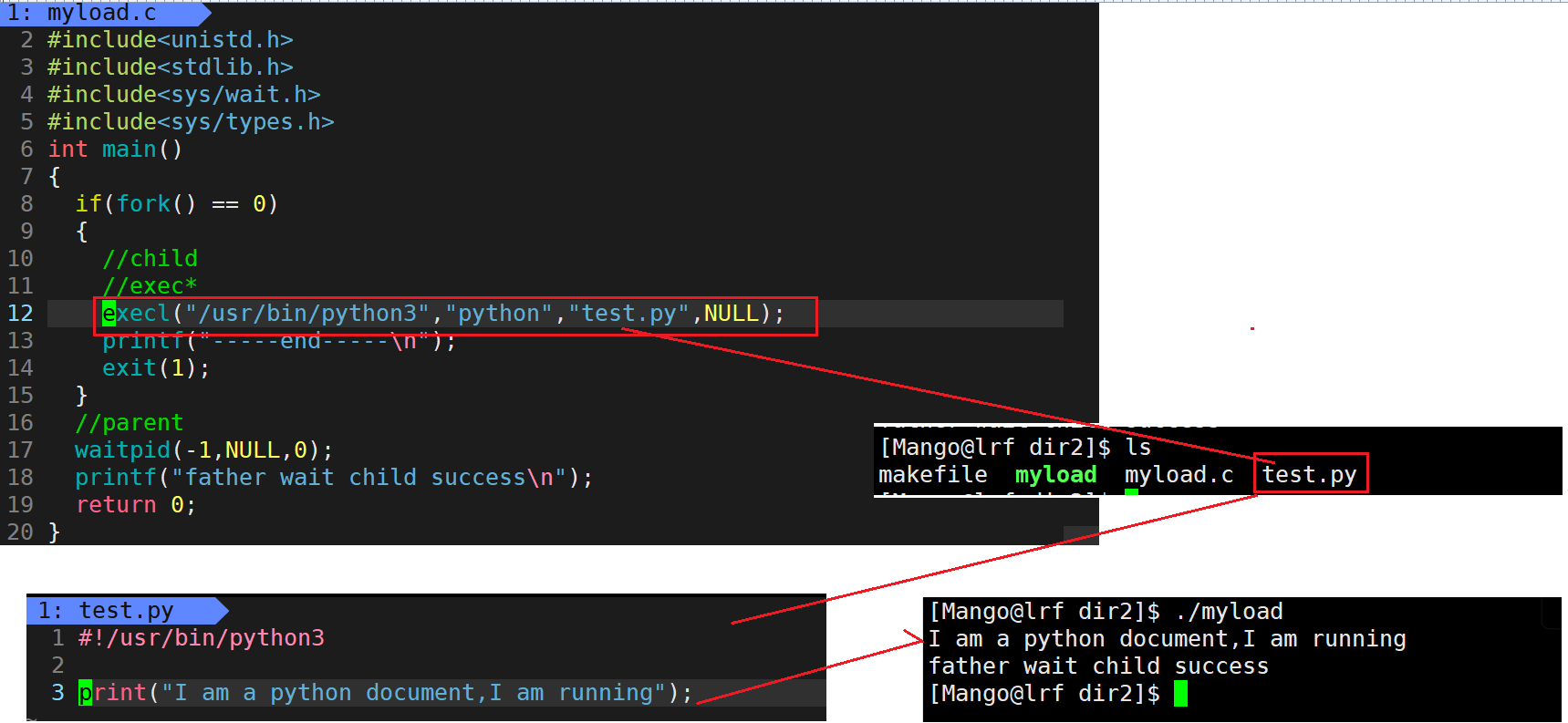
想要执行的是/usr/bin/python3路径下的python程序, 如何执行呢? python test.py
![[python]win10安装gym](https://img-blog.csdnimg.cn/fba4761327f74caa9bcbbacdf828f22f.png)