exists用法
大白话的说,exists的执行,是依次拿外层表的每条记录,去和exsits后的子查询表按你所定义的运算规则(如果有的话)做运算,如果存在结果,也就是有返回数据,无论这部分数据有几条,这部分数据内容是什么,exists后的子查询都会返回true,外层表参与运算的这条记录被保留,反之返回false,外层表参与运算的这条记录被舍弃。也就是强调的子查询有返回,而不关注子查询返回什么。下面是从文档中截取的几句话,可以印证说明。
文档中第一段话说的是对于一个查询结果非空的子查询,如果前面是exists,则子查询返回true,如果是not exists,则返回false。
第二段话说的是exists子查询里面的select子句,通常写成select *,但也可以写成select '任意值’和select 列名的形式。因为像上面说的,外层只关注内层子查询是否有结果数据,而不关注数据本身。需要注意的是如果是select '任意值’的形式例如select 5,那么每次都会返回true,外层所有记录都会被保留。
第三段话其实说的还是只关注子查询是否有结果,不关心结果是什么,哪怕查询的结果行中都是null都没问题,同样返回true。
关于第三段话“对于上面的例子,如果t2包含任何行,哪怕行的内容为null,都会返回true”这里可能有些难理解,我个人当初和null值混淆,当时写的一个例句“select * from t1 exists (select null)”,按照前面所说的exists执行过程来看,子查询没有运算结果时返回false外层表数据舍弃,所以觉得应该是t1表的数据都应该被舍弃,结果是把t1表的所有数据都返回了。后来找了些书看知道为什么开始的想法是错误的了。要想搞清楚这个问题,首先要理解SQL是一个面向集合的语言,也就是操作和返回的数据都是建立在集合的基础上。上面的执行过程其实就是说,当运算结果是一个非空集合时,则返回true,如果是空集,则返回false。其次要明白null在数据库中的含义,null表示的是不确定,未知,可能有值、可能无值、可能存在、可能不存在、可能是任何值、可能不是任何值。更确切的表示的更像是一种状态,而非空值。空值的前提是必须存在,只是没有值。所以从这也能理解null和空集并不等价。如果把null作为集合中一个元素的话,返回null则是返回了一个包含了null元素的集合,而非空集。
这也是开始困扰我的地方,如果没有这方面的困扰这段话可以跳过。
下面直接写几个Demo举例说明一下。
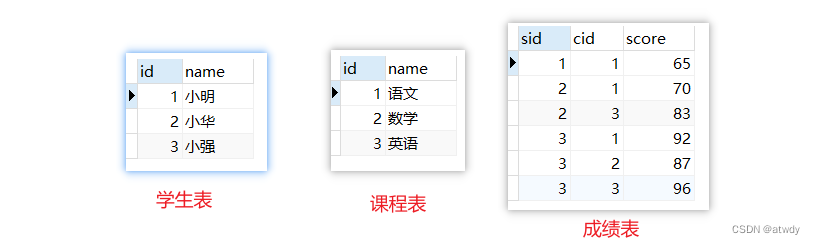
创建3张测试表,学生表student(id,name),课程表course(id,name),成绩表score(sid,cid,score)
-- 创建学生表
drop table if exists student;
create table student(
id int,
name varchar(10)
);
insert into student values(1,'小明'),(2,'小华'),(3,'小强');
select * from student;
-- 创建课程表
drop table if exists course;
create table course(
id int,
name varchar(10)
);
insert into course values(1,'语文'),(2,'数学'),(3,'英语');
select * from course;
-- 创建成绩表
drop table if exists score;
create table score(
sid int,
cid int,
score int
);
insert into score values(1,1,65),(2,1,70),(2,3,83),(3,1,92),(3,2,87),(3,3,96);
select * from score;
Q1:找出小华选修的课程课程名。(简单)
select
name
from course -- 选课程,所以外层表为课程表
where exists( -- 用外层课程表中的记录逐一和学生表成绩表关联并按指定规则过滤,存在结果返回true,不存在结果返回false
select
*
from student,score
where score.cid=course.id
and score.sid=student.id
and student.name='小华' -- 限定小华
);
返回的结果是语文和英语。
Q2:找出选修了全部课程的学生姓名。(这个是有难度的,觉得下面这个sql看懂了exists也差不多懂了)
-- 选修了全部课程,可以翻译成没有一门课程是这个学生不选的。用双重not exists嵌套实现
-- not exists和exists相反,子查询结果为空集时返回true,否则返回false
select
name
from student s
where not exists( -- 如果所有的课程记录都被舍弃,说明学生选修了全部,此时select结果为空集,not exists返回true,该学生被保留
select
name
from course c
where not exists( -- 对于该门课程,如果该学生存在成绩记录则返回false,则舍弃该门课程,继续往下依次查找其它课程
select
*
from score sc
where sc.sid=s.id -- 限定学生
and sc.cid=c.id -- 限定课程
)
)
查询结果是小强。
其实上面这个sql难理解的地方在于要知道对于中间那一层course表的记录,也是根据最内层子查询的查询结果一条条依次做筛选的,当对所有的课程筛选完才会对外层返回一个true或false的结果。
exists和in的区别
关系上,二者都属于子查询,但区别是in是不相关子查询,exists是相关子查询。因为执行过程中in是先执行子查询得到一张中间结果表,再在外层表和中间表之间做匹配查询。而exists是每次拿外表的数据到子查询中做校验。
执行上,in是将子查询结果表和外层表做hash连接,exists是将外表做loop循环,每次循环再对内表做查询。
执行效率上,普遍说法是in查询时以子查询结果表为驱动表,外表为被驱动表,所以适合子查询数据集小外表数据集大的情况。而exists查询时以外表为驱动表,子查询表为被驱动表,所以适合外表数据集小子查询数据集大的情况。这只是理论上,实际执行时以谁为驱动表谁为被驱动表还要经过优化器的优化,同时还涉及到走不走索引,具体还是要以实际的执行计划为准。
本来想深入的学习一下mysql具体是怎么选择驱动表的,但目前精力和水平都有限。(失业人员,哈哈,还在到处找工作),以后有时间了把这些东西搞清楚再来补上。
参考
1.https://dev.mysql.com/doc/refman/8.0/en/exists-and-not-exists-subqueries.html
2.《SQL进阶教程》(MICK著/吴炎昌译) 1-8.EXISTS谓词的用法