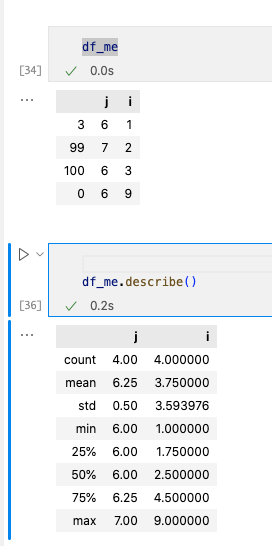
数据处理的时候经常性需要整理出表格,在这里介绍pandas常见使用,目录如下:
- 数据结构
- 导入导出文件
- 对数据进行操作
– 增加数据(创建数据)
– 删除数据
– 改动数据
– 查找数据
– 常用操作(转置,常用统计值)
参考链接:10 minutes to pandas https://pandas.pydata.org/docs/user_guide/10min.html#min
数据结构
Pandas常见的就两种数据类型:Series和DataFrame,可以对应理解为向量和矩阵,前者是一维的,后者是二维的。在DF中类似统计学中的数据组织方式,一行代表一项数据,一列代表一种特征,用这种方式记忆能够帮你更好理解DF。需要注意的是:在DF中index是行,column是列。


导入导出数据
常使用.csv格式的文件,我们在导入数据的时候使用pd.read_csv(),在导出数据的时候用df.write_csv(“/data/ymz.csv”).
# 读入数据
In [144]: pd.read_csv("foo.csv")
Out[144]:
Unnamed: 0 A B C D
0 2000-01-01 0.350262 0.843315 1.798556 0.782234
1 2000-01-02 -0.586873 0.034907 1.923792 -0.562651
2 2000-01-03 -1.245477 -0.963406 2.269575 -1.612566
3 2000-01-04 -0.252830 -0.498066 3.176886 -1.275581
4 2000-01-05 -1.044057 0.118042 2.768571 0.386039
.. ... ... ... ... ...
995 2002-09-22 -48.017654 31.474551 69.146374 -47.541670
996 2002-09-23 -47.207912 32.627390 68.505254 -48.828331
997 2002-09-24 -48.907133 31.990402 67.310924 -49.391051
998 2002-09-25 -50.146062 33.716770 67.717434 -49.037577
999 2002-09-26 -49.724318 33.479952 68.108014 -48.822030
[1000 rows x 5 columns]
# 写出数据
In [143]: df.to_csv("foo.csv")
对数据进行操作
对数据操作包括增(创建),删,改,查。
增加数据(创建数据)
相比较Series,我们更常使用DataFrame数据类型,常使用的创建DataFrame类型有两种,一种是使用data创建(注意data得是一个二维list/array等),一种是使用字典创建。
1. 使用data创建DF
# 使用data导入
In [5]: dates = pd.date_range("20130101", periods=6)
In [6]: dates
Out[6]:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
In [7]: df = pd.DataFrame(data=np.random.randn(6, 4), index=dates, columns=list("ABCD"))
In [8]: df
Out[8]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.524988
2. 使用字典创建DF
# 使用字典
In [9]: df2 = pd.DataFrame(
...: {
...: "A": 1.0,
...: "B": pd.Timestamp("20130102"),
...: "C": pd.Series(1, index=list(range(4)), dtype="float32"),
...: "D": np.array([3] * 4, dtype="int32"),
...: "E": pd.Categorical(["test", "train", "test", "train"]),
...: "F": "foo",
...: }
...: )
...:
In [10]: df2
Out[10]:
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
3. 增加一行数据
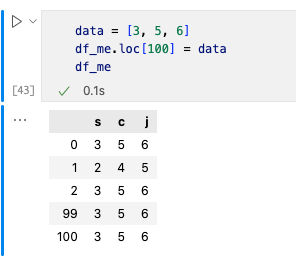
1)使用loc在行尾增加
增加一行数据的方法有loc, iloc, append, concat, merge。这里介绍一下loc,loc[index]是在一行的最后增加数据。但是你需要注意loc[index]中的index,如果与已出现过的index相同,则会覆盖原先index行,若不相同则才会增加一行数据。
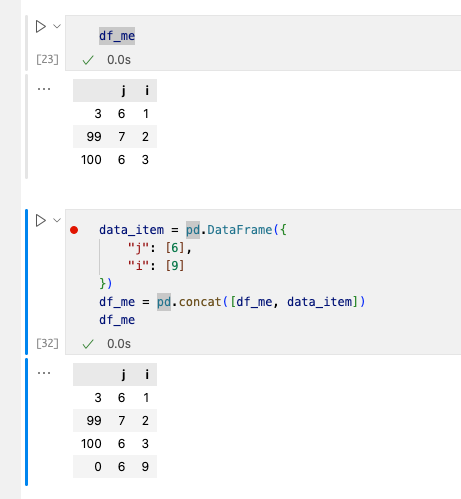
2)使用concat将两个DF合并
concat()也是一个增加数据常用的方法,常见于两个表的拼接与爬虫使用中,作用类似于append(),但是append()将在不久后被pandas舍弃,所以还是推荐使用concat()。
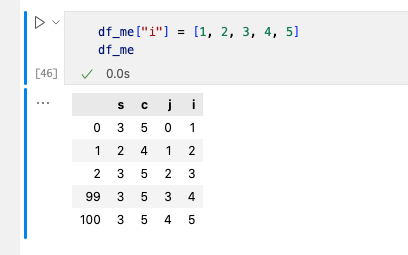
4. 增加一列数据
增加一列数据的方法直接用[]便可,例子如下:
Series用的比较少,案例如下:
In [3]: s = pd.Series([1, 3, 5, np.nan, 6, 8])
In [4]: s
Out[4]:
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
删除数据
对于删除数据,我们使用drop()方法,并指定参数为index(行)或者column(列)
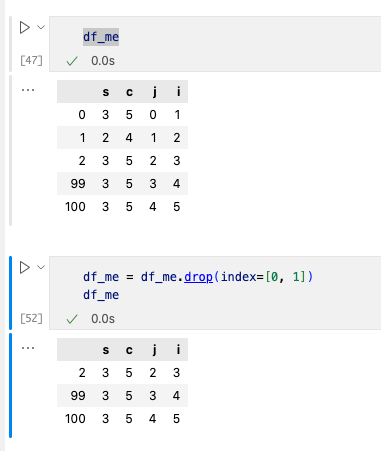
1. 删除一行数据
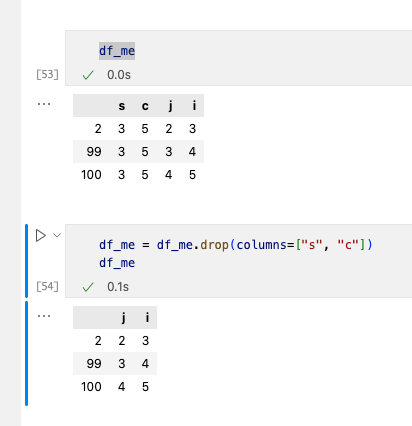
2. 删除一列数据
改动数据
改动一行,列数据常用loc()和[]方法。
1. 改动一行数据
改动一行我们使用loc[]=[…]进行更改。
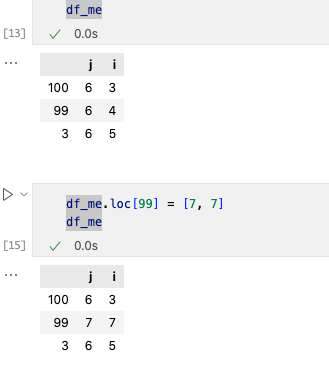
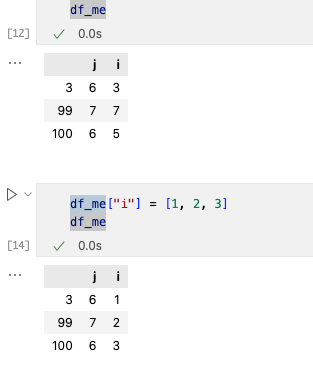
2. 改动一列数据
改动一列数据我们使用[]进行更改。
查找数据
在查找数据的时候,我们常使用[]来查看行列数据,配合.T来将矩阵转置。也可以使用head(),tail()来查看前几行和后几行数据。
1. 查看特定行数据
使用类似[0:2]来查看特定行数据,和python中list使用类似。

2. 查看特定列数据
我们需要使用两层[]嵌套来访问数据,例如[ [“j”, “i”] ]。
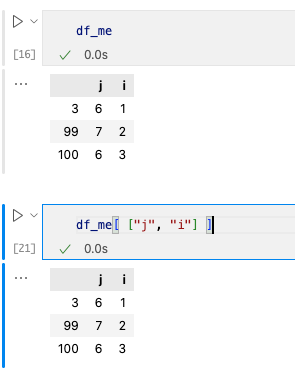
常用操作
数据分析时常用的两个操作,转置和计算统计量。
1. 转置
使用.T便可以完成。
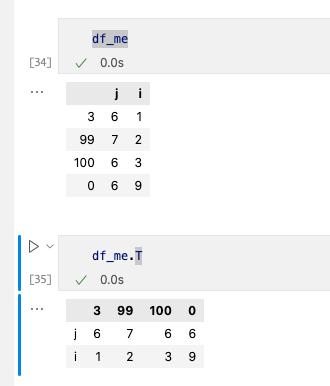
2. 计算统计量
使用.describe()。