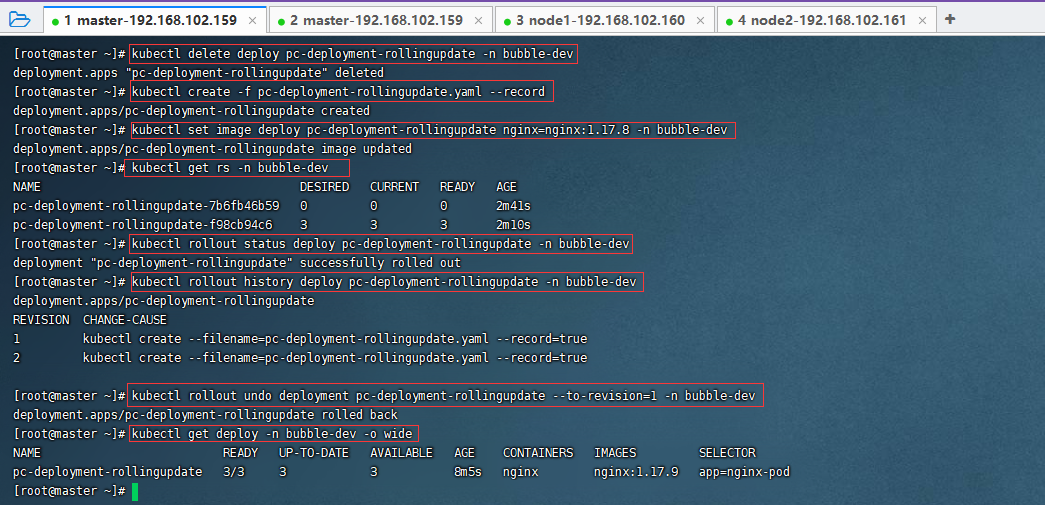
文章目录
- 课程记录
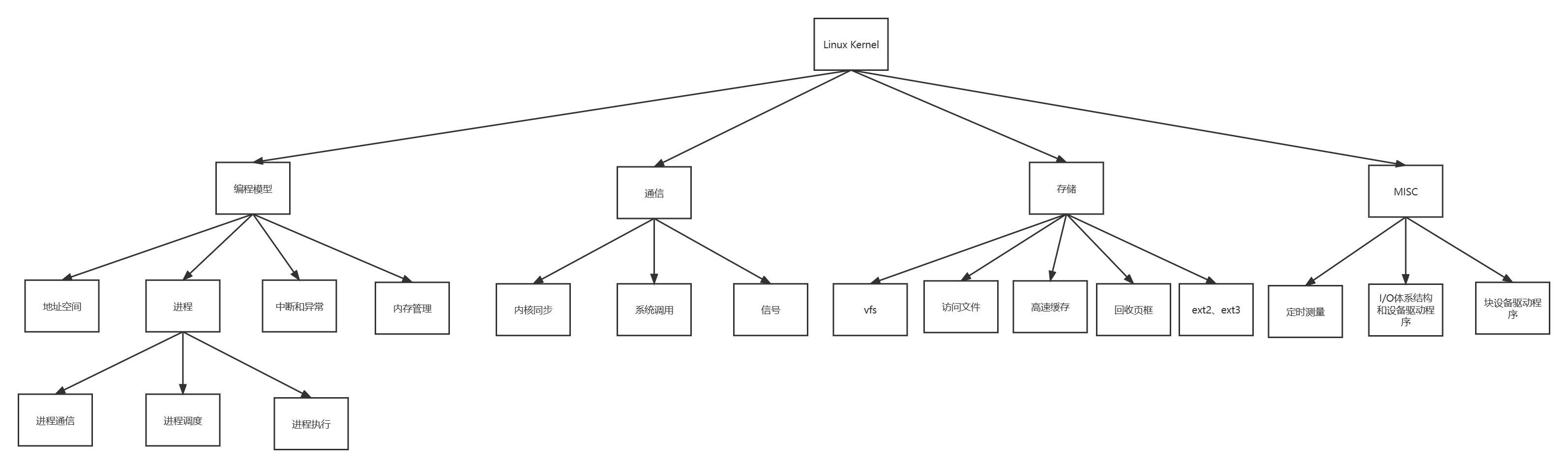
- 核心技术Core Technical Challenges
- representation表示
- alignment对齐
- 转换translation
- Fusion融合
- co-learning共同学习
- 总结
- Course Syllabus教学大纲
- 个人总结
- 第一周的安排
- 相关连接
课程记录
这部分是自己看视频,然后截屏,记录下来的这部分的感受,大家感兴趣但是又听得很费劲的话,可以看我的总结。
核心技术Core Technical Challenges
representation表示
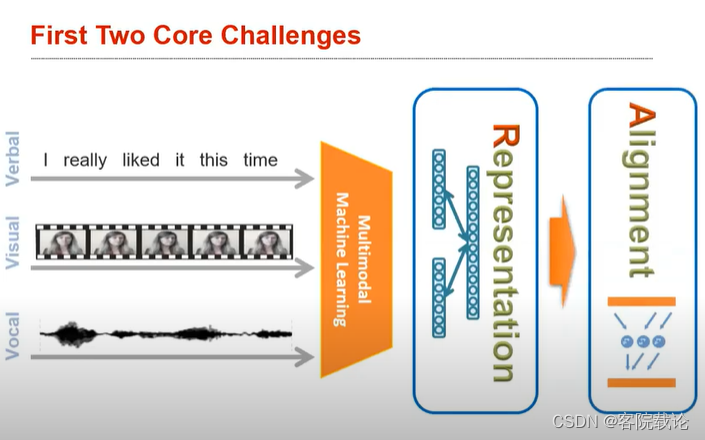
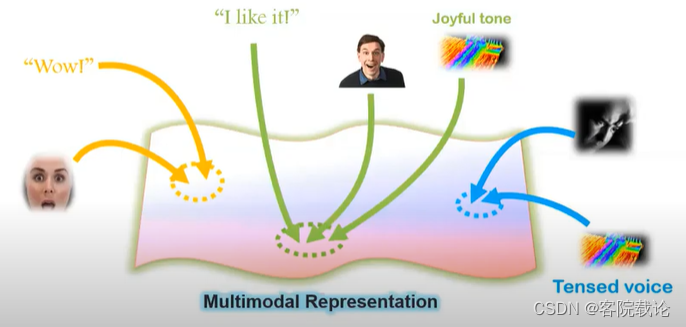
- 多模态学习的里程碑事件,是人们学会了联合表示joint representtation。
- 在上图中,可以看到不同的模态信息都是使用同一种表示进行表示,包括语言,感觉,触觉等。
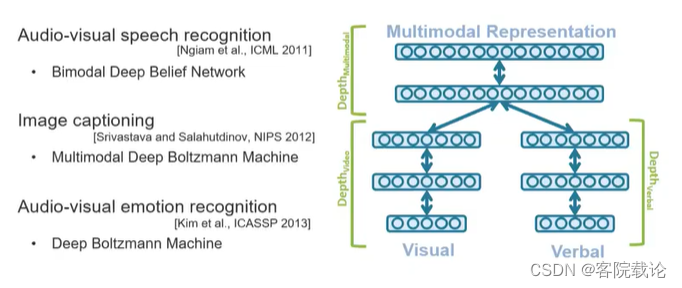
- 上图中左侧是图片和文字两种模态进行融合发展的典型样例。右侧是语言和视觉的结合,分别使用独立的语言模型和视觉模型,将文本和图片转为vector进行表示,然后再进行联合。这两个语义就存在于同一个空间。

- 上述slide是一个联合学习的简单应用 ,将一个蓝色的车辆生成的向量,减去blue生成vector,然后再加上新的单词,你就可以获得红色的车。可以用来做简单的内容理解,虽然内容仍旧很鸡肋,但是但是已经是划时代。进一步说,我们可以将多模态学习转为如何开发出一种能够表示不同模态数据的冗余性和互补型的表示。
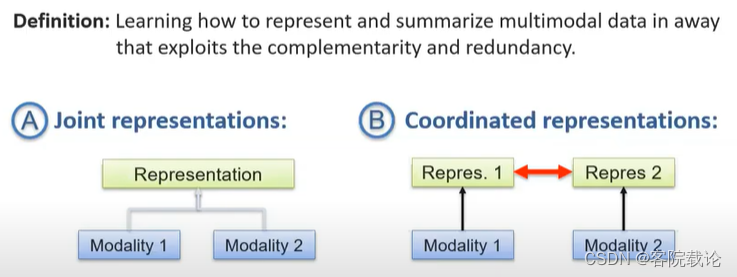
- 数据的互补性在于,仅仅通过一种模态并不能达成目标,需要两种信息互补。冗余性,就是通过一种信息就可以知道完全的信息,彼此是冗余的,但是可以保持模型的健壮性。
- 不同于多模态协调,多模态融合是将两种模态融合为一种模态,在同一空间中进行保存,图片就是文本,然后文本就是图片,这是绑定的。但是多模态协调, 是完全不同的模态。如果两个模态比较近似,可以使用联合表示joint representation。如果不相等,但是相似,就可以使用多模态协调。
- 多模态协调的典型样例就是:CCA Canonical Correlation analysis
alignment对齐

- alignment和多视角,多种语言中对齐定义相类似,正常你在说话的时候,需要将和语言和动作进行对齐,才会便于理解。多模态学习就像是对于同一事物,使用不同视角进行学习,这个视角可以看作是模态,就是使用不同的模态去学习同一个事物。常见的应用,比如说,将表示同样意义的图片和文字进行存储。
- Explicit Alignment:是根据意义将事物进行比对,比如说将做通一道菜的视频和菜谱进行配对,将意义相同的图片和文字进行配对。损失函数,的目标就是衡量是否对齐的。
- Implicit Alignment:不同于上文的清晰对齐,不清晰对齐的损失函数的目标并不是直接判定是否对齐的,是以别的任务为目标的。不清晰的对齐是作为某一项任务的中间过程,实际的损失函数可能是以别的任务为目标。常见的比如说,在从图片生成文本的过程中,文字和图片对齐仅仅是一个潜在的过程,对于研究这个方向的人来说,具体可能就是注意力模型。自注意力机制和tarnsformer就是按照这个线索展开的。
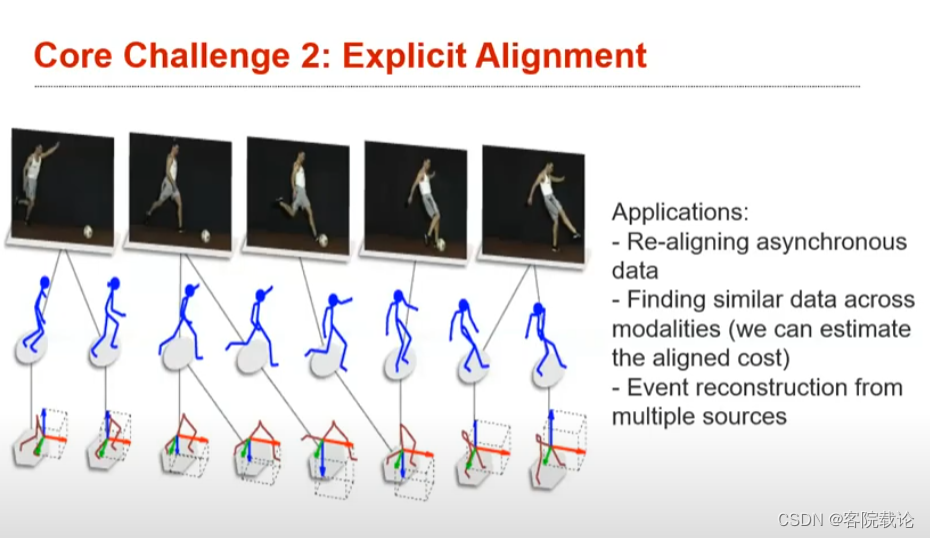

- 上述视频可能不同,运动力度不同,但是你仍旧可以想方设法使其进行对齐。上述slide就是explicit对齐,单纯为了对齐而对齐

- 上述过程就是隐式对齐,为了实现语言生成,需要进行文字对齐。对齐是作为其中一个过程存在的。
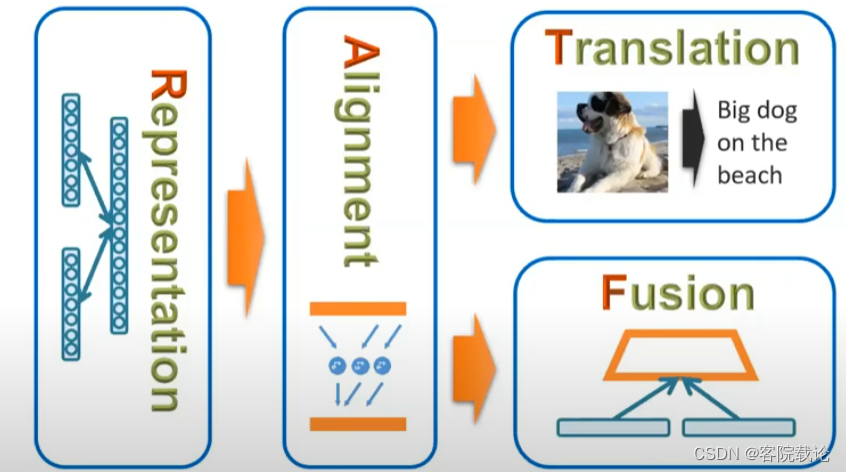
- representation和alignment对于大部分多模态模型而言,都是必须的部分,也是本课程最为重要的两个部分,分别花费三周的时间学习。在后者,将会产生分支,translation是作为转换,将一种模态转换为另外一种模态,而fusion虽然是融合,是将两种模态进行融合,但是不同于representation,其实为了获取更加高级的信息,比如说获取情感信息,或者获取视频中的具体事件等。
- translation的典型应用就是图片的注释生成。
转换translation

- 这就是转换的一个典型的应用,根据任务描述和台词,自动生成在说这些话的动画模型。
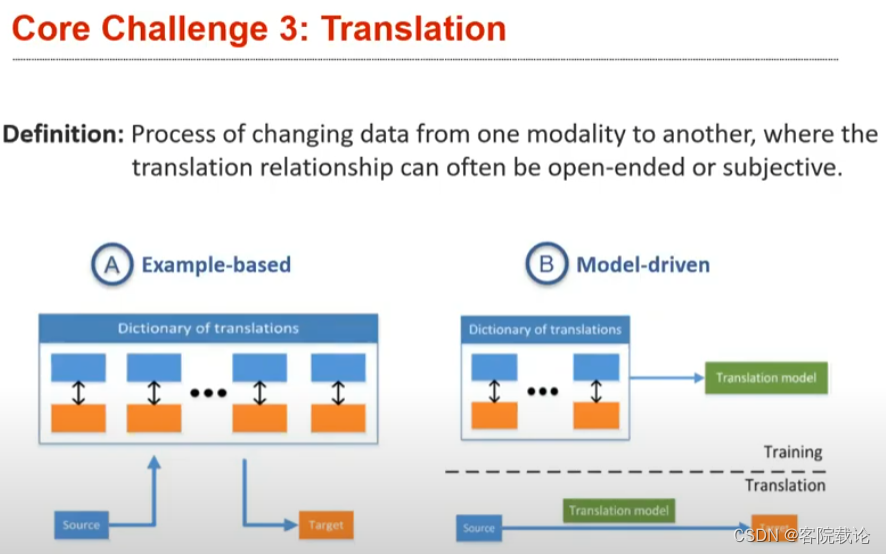
- 将数据从一种模态转变为另外一种模态的过程,其中转换关系一般是开放没有限度的,或者是主观的
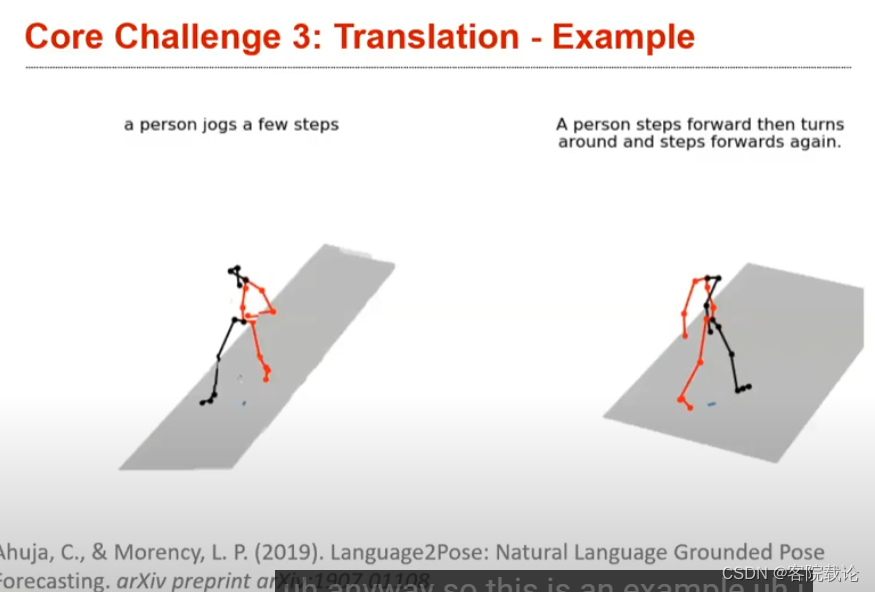
- 这个应用是根据文字生成对应的动作,作者的幻想就是根据剧本生成对应初始版本的动画,看看剧本的效果。
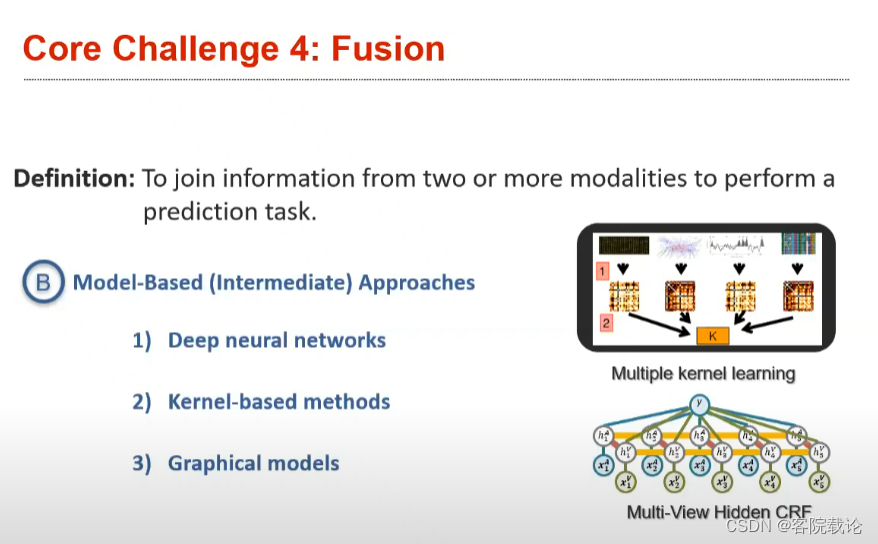
Fusion融合
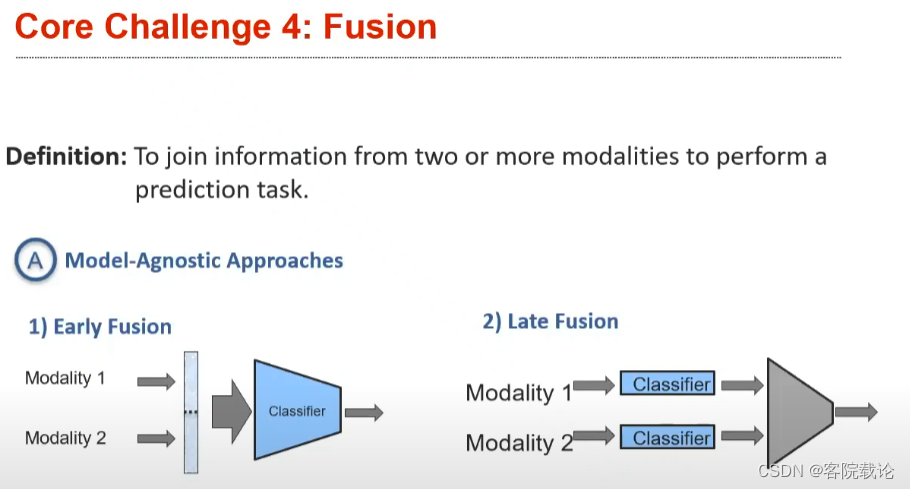
- 主要是分为早期融合和晚期融合,早期融合是针对,在将两种模态的数据进行融合,在融合之后的数据上进行更加复杂的操作。而后融合,就是先进行复杂操作,然后见结果进行融合,这样处理之后,整个模型的数据会变小。
- model-agnostic approach:模型不可知方法
co-learning共同学习
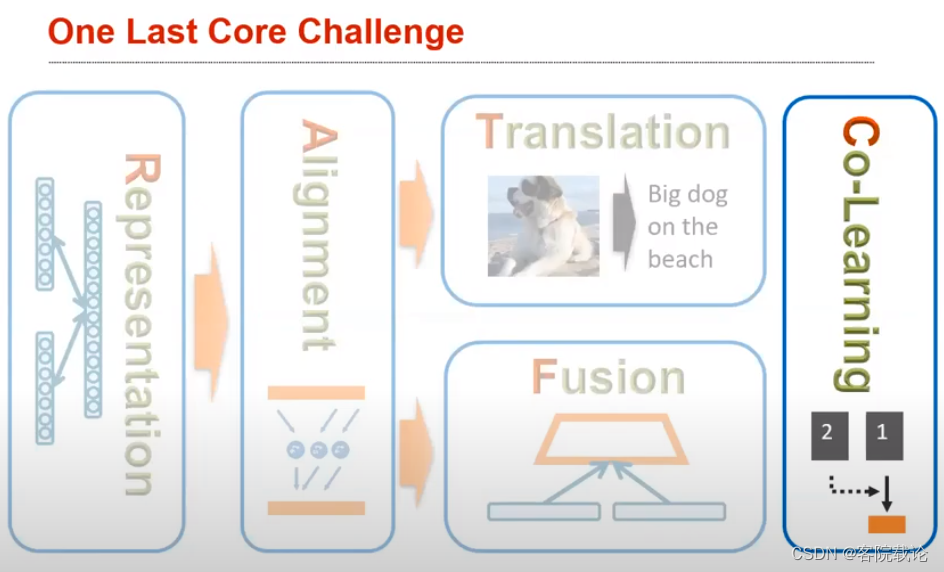
- 共同学习的目标:在模态之间尽心转换结果,包括表达方式和预测性的模型。比如说,目标检测就是一个单模态的任务,我们能否使用其他的已经训练好的相关的多模态模型,来减少单模态目标识别的训练时间。一般来说,是用来针对数据比较少的情况下使用的。
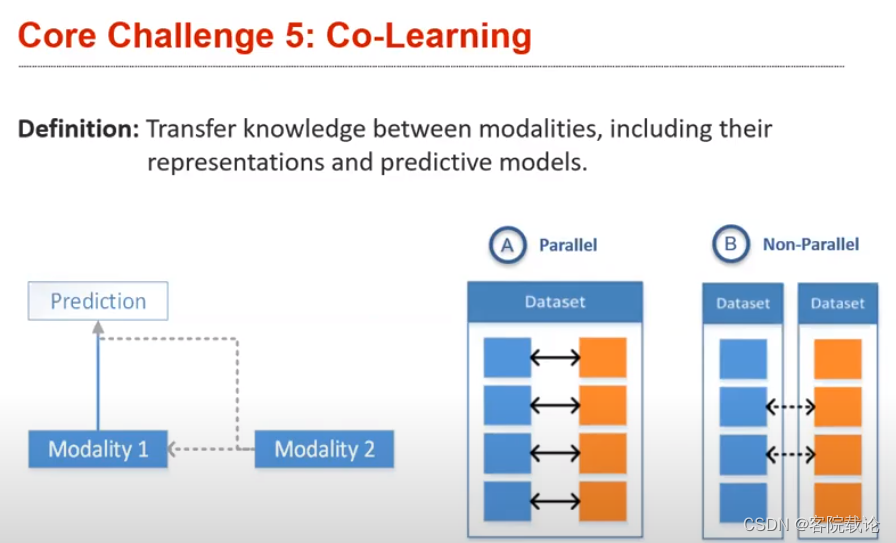
- 共同学习的最大问题,就是不知道两个共同学习的模态的相关性是强的,还是弱的,不知道如何进行配对。parallel就是完全匹配的关系,每一个模态的元素都是一一对应的,比如说单词和图片。另外一种就是non-parallel属于不完全匹配,但是整体的含义是相同的,比如说具有相同意义的,英文句子和法语句子。
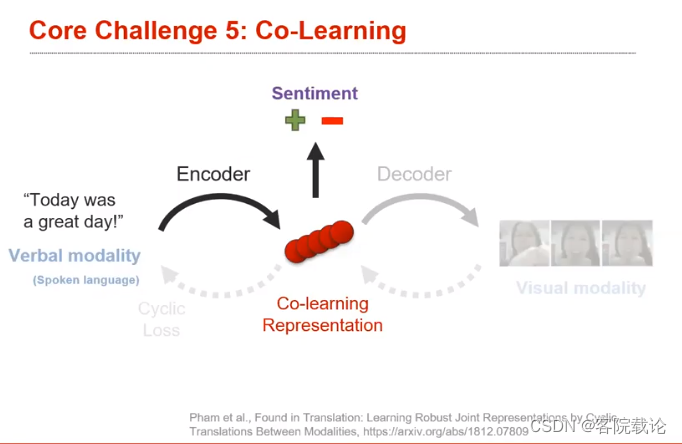
- ** a cyclic loss** : 循环损失
- 上述例子是学习language Embedding的过程,将用户说的话编码,用来进行情感识别。这里的想法是,如果语料库足够多,就可以单纯通过语言这个模态进行解决,但是针对手写的文本数据库比较多,但是对于语音的语料库并不是很多。正常讲话的过程中,是包含语音信息,语言信息和人物动作三种信息,可以在训练中使用,用来改良训练效果,但是在测试阶段,只能拥有语音信息。
- 首先,作者将语音模态转换,进行编码,变为中间表示,然后生成为视觉模态。然后,使用循环损失函数,进行逆向操作,由视觉模态,逆向生成共同学习的中间表示,然后在进行逆向生成,变成原始的语言模态。这个用来判定转换之后的目标模态是否保存了输入数据的所有信息。
- 然后,在实际训练的过程中,你就可以单纯针对中间表示进行训练,中间表是的数据集表较多,然后原先的数据集就只需要进行测试极了。最左端输入的是比较少的测试数据,中间是数据集比较多的数据集,右侧是最终的训练结果
总结

- 上述是五个分类的大概,并且指出了对应类别的研究挑战。

- 多模态机器学习已经解决了目前很多的问题,上述为目前主要的研究方向。
Course Syllabus教学大纲
- ICML:


- 不仅仅运行对应的代码,更重要能够进行错误分析,知道为什么。然后再提出一些改进意见,并不是追求什么准确度,而是做出不同的尝试


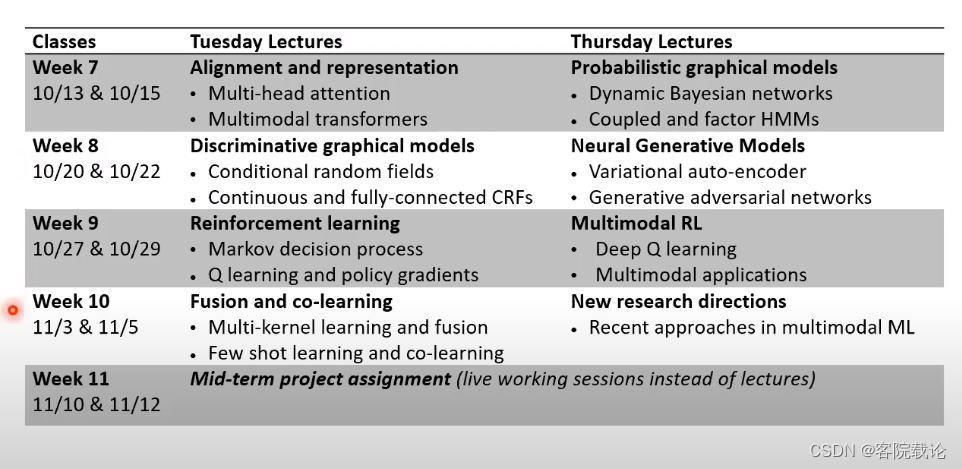
- 具体的课程安排


个人总结
- 这是完全听了这门课,觉得部分国外教学是要比部分国内教学好的,至少教的东西都是比较新的,并不是照本宣科的念,已经有了网课,就照着网课跟着学习,这里把链接贴出来。上面的内容是我听了网课总结的,感兴趣的可以进行学习。
- 这门课的最终的项目都发表了相关的文章,而且作者在github上都放上了相关的连接,大部分都已经发表了对应的文章。
- 这是一个系列性的课程,自己慢慢听,应该会收获很多。
- 每周的阅读内容,我都会将我自己的阅读内容写成博客,分享,如果大家对于这门课程感兴趣,可以和我一块讨论。
第一周的安排
- 阅读下述文献
- Multimodal Machine Learning:A Survey and Taxonomy
- Repersentation Learning:A Review and New Perspective
- 回答相关的问题
- What is Multimodal? Definitions, dimensions of heterogeneity and cross-modal interactions.
- Historical view and multimodal research tasks.
- Core technical challenges: representation, alignment, transference, reasoning, generation, and quantification.
相关连接
课程视频链接
课程安排连接







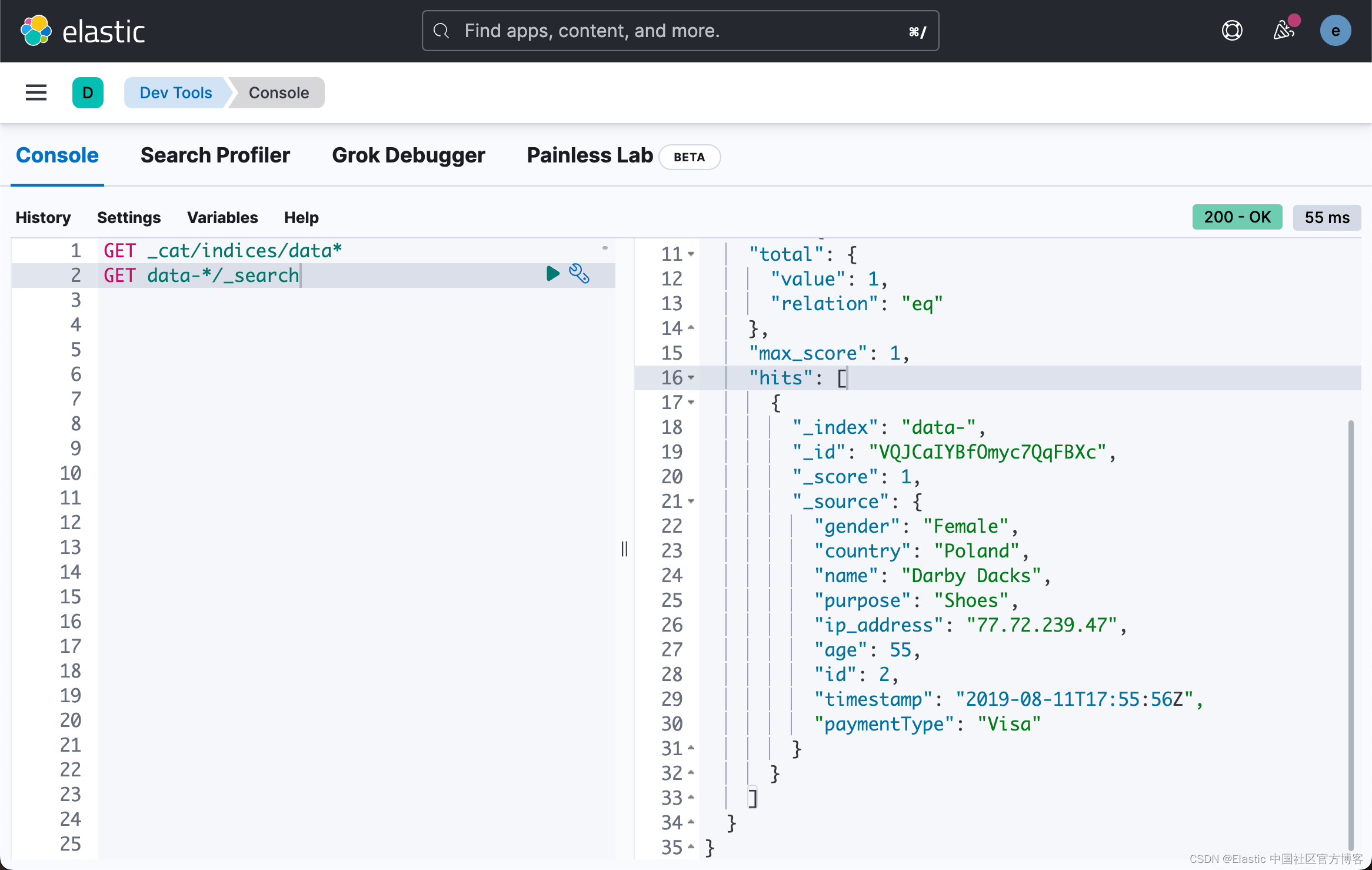
![pvs中pv显示[unknown]解决方法、正确剔除一个vg流程方法【不影响vg已有的lv数据】、vgs容量和硬盘容量显示不一致解决方法](https://img-blog.csdnimg.cn/71b82d1c3d7c49b29f5cfd3f44d432d8.jpeg)